









一、论文简介
1.1、论文和代码链接
paper:http://xxx.itp.ac.cn/pdf/2001.00309.pdf
code:https://github.com/aim-uofa/AdelaiDet
AdelaiDet 是一个开源工具箱,用于基于Detectron2 的多个实例级识别任务。有很多实例分割的都在这开源了,用来进行实验十分的方便。
code2:https://github.com/aim-uofa/adet
1.2、论文基本信息

发表于CVPR2020
这篇论文名为:BlendMask:自上而下与自下而上的实例分割,BlendMask在COCO上的精度为41.3AP,在1080ti速度为 25FPS on 1080ti,全面超越了Mask R-CNN,下面将详细介绍一下BlendMask。
二、详细解读
2.1、摘要
实例分割是最基本的视觉任务之一。近年来,由于完全卷积的实例分割方法通常比Mask R-CNN等两阶段方法更简单、更有效,因此备受关注。到目前为止,当模型的计算复杂度相似时,这些方法在掩模精度方面几乎都落后于两阶段Mask R-CNN方法,有很大的改进空间。在本工作中,我们通过有效地结合实例级信息和低层细粒度的语义信息来实现改进的掩码预测。我们的主要贡献是一个混合模块,它的灵感来自自顶向下和自底向上的实例分割方法。提出的BlendMask可以用很少的通道有效地预测密集的每像素位置敏感实例特征,并且仅用一个卷积层就可以学习每个实例的注意图,从而具有较快的推理速度。BlendMask可以轻松地与最先进的一级检测框架结合。
2.2、介绍
①、发现问题
这篇文章主要讨论的是密集实例分割,密集实例分割分为两种,一种是自底向上,另一种是自顶向下,这两种方法存在一定的缺陷,如图所示。
②、改进介绍
本文针对这两种方法的缺点,提出一种融合的方式进行改进:利用top-down方法生成的instance-level的高维信息(如bbox),对bottom-up方法生成的 per-pixel prediction进行融合。借鉴FCIS(裁剪)和YOLACT(权重加法)的思想,提出一种Blender模块,能够更好地融合包含instance-level的全局性信息和提供细节和位置信息的低层特征。2.3、网络架构
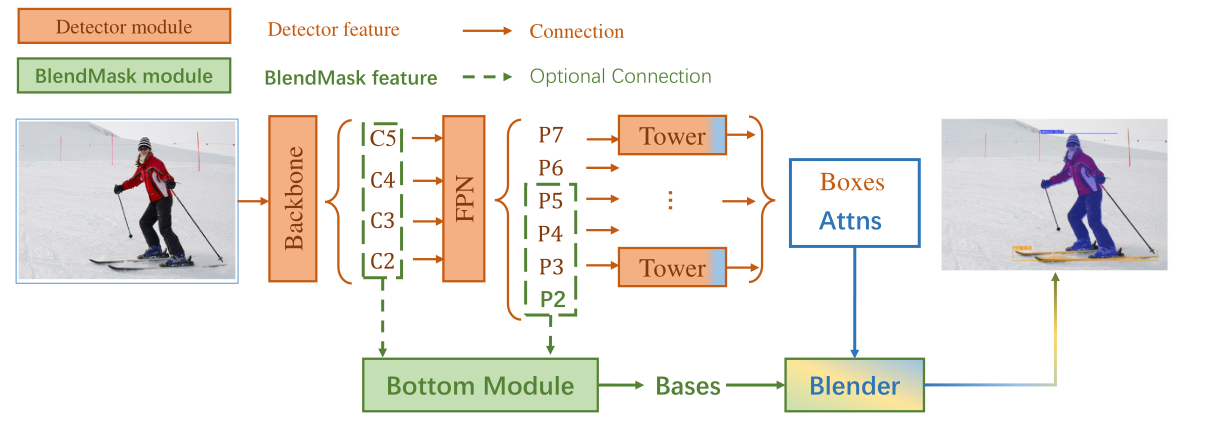
如上图,BlendMask包含一个Detector 模块(图中橙色)和一个BlendMask模块(图中绿色)。文中的detector 模块直接用的FCOS,而BlendMask 模块分为三个部分。
2.4、改进与创新
Blender模块是论文的创新部分,BlendMask其实是多个模型的优点的融合。
Blender模块的输入,分别为:
1、detector tower 生成的bbox proposal§,维度为(K×H’×W’);此外,在训练的时候,直接使用GT bbox作为P,而在推理时,则使用检测器的检测结果。
2、top layer 生成的top-level attention(A),维度为(K×M×M)。
3、bottom module 生成的base(B),是整图大小的k个mask,维度为(K×H×W)。
2.5、实验结果


在COCO数据集上与MaskRcnn,TensorMask,SOLO,YOLACT等算法进行了比较,比较了这些算法的ResNet50和ResNet101两种骨架,指标为AP值,AP50,AP75(指的是取detector的IoU阈值大于0.5,大于0.75),PANet采用ResNet-101时明显是最优的。APs,APm,APl分别代表小物体,中等物体和大物体,有一定的优势。
2.6、使用的数据集
COCO数据集。
三、总结与思考
虽然精度、速度高,但创新点不能算突出。好在实验做的很充足,优化模型的思路也很值得借鉴。得出一个结论,要学会如何使用别人的优点,取长补短无论在什么时候都不过时。



















 576
576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











