







BlendMask知识点记录
论文名称:《BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation》
论文链接:https://arxiv.org/abs/2001.00309
新出的实例分割算法,融合了mask rcnn和yolact的算法思想,既有mask rcnn的ROI,又有yolact的proto type(base)。该模型效果达到state-of-the-art,精度最高能到41.3AP,实时版本BlendMask-RT性能和速度分别为34.2mAP和25FPS。
第一次记录
实例分割是基本的视觉任务之一。最近,全卷积实例分割方法引起了很多关注,因为它们通常比诸如Mask R-CNN的两阶段方法更简单,更高效。迄今为止,当模型具有相似的计算复杂度时,几乎所有这些方法在掩模精度上都落后于两阶段Mask R-CNN方法,从而有很大的改进空间。在这项工作中,我们通过有效地将实例级信息与具有较低级细粒度的语义信息结合起来,实现了改进的掩码预测。我们的主要贡献是一个Blender模块,该模块从自上而下和自下而上的实例分割方法中汲取了灵感。提出的BlendMask可以通过很少的通道有效地预测密集的每像素位置敏感实例特征,并且仅使用一个卷积层就可以为每个实例学习注意力图,从而可以快速进行推理。BlendMask可以轻松地与最新的一阶段检测框架结合使用,并且在相同的培训计划下性能优于Mask R-CNN,但速度提高了20%。轻巧的BlendMask版本达到34.2在一张1080Ti GPU卡上评估了25 FPS时的mAP。由于它的简单性和有效性,我们希望BlendMask可以作为简单而强大的基线,适用于各种实例预测任务。
FCIS和YOLACT的融合方法,作者提出了Blender模块来更好地融合这两种特征。最终,BlendMask在COCO上的精度(41.3AP)与速度(BlendMask-RT 34.2mAP, 25FPS on 1080ti)都超越了Mask R-CNN。
本文主要讨论的是密集实例分割( Dense instance segmentation),密集实例分割也同样有top-down和bottom-up两类方法。
Top-down 方法
自上而下的密集实例分割的开山鼻祖是DeepMask,它通过滑动窗口的方法,在每个空间区域上都预测一个mask proposal。这个方法存在以下三个缺点:
1、mask与特征的联系(局部一致性)丢失了,如DeepMask中使用全连接网络去提取mask;
2、特征的提取表示是冗余的, 如DeepMask对每个前景特征都会去提取一次mask;
3、下采样(使用步长大于1的卷积)导致的位置信息丢失;
Bottom-up 方法
自下而上的密集实例分割方法的一般套路是,通过生成per-pixel的embedding特征,再使用聚类和图论等后处理方法对其进行分组归类。这种方法虽然保持了更好的低层特征(细节信息和位置信息),但也存在以下缺点:
1、对密集分割的质量要求很高,会导致非最优的分割;
2、泛化能力较差,无法应对类别多的复杂场景;
3、后处理方法繁琐;
混合方法
本文想要结合 top-down和bottom-up两种思路,利用top-down方法生成的instance-level的高维信息(如bbox),对bottom-up方法生成的 per-pixel prediction进行融合。因此,本文基于FCOS提出简洁的算法网络BlendMask。融合的方法借鉴FCIS(裁剪)和YOLACT(权重加法)的思想,提出一种Blender模块,能够更好地融合包含instance-level的全局性信息和提供细节和位置信息的低层特征。
总体思路
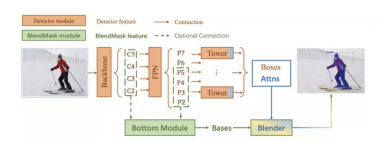
BlendMask的整体架构如下图所示,包含一个detector module和BlendMask module。文中的detector module直接用的FCOS,BlendMask模块则由三部分组成:bottom module用来对底层特征进行处理,生成的score map称为Base;top layer串接在检测器的box head上,生成Base对应的top level attention;最后是blender来对Base和attention进行融合。
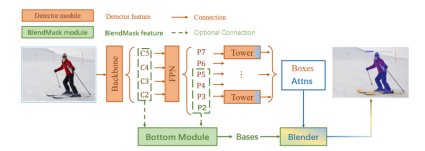
Bottom Module
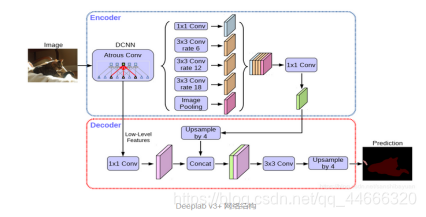
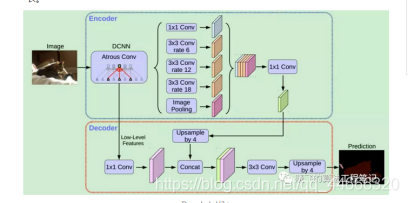
文中使用的是DeeplabV3+的decoder,其他分割网络的decoder同样适用。
Top Layer
在检测金字塔的每一层后面都加了一层卷积,用来预测 top-level attentions (A)。这里与YOLACT相似,但有所区别:

![]()
Blender
Blender模块是文章的创新部分,该部分的混合过程具体解释如下:
首先明确Blender模块的输入,分别为:
1、detector tower 生成的bbox proposal(P),维度为(K×H'×W');此外,在训练的时候,直接使用GT bbox作为P,而在推理时,则使用检测器的检测结果
2、top layer 生成的top-level attention(A),维度为(K×M×M)
3、bottom module 生成的base(B),是整图大小的k个mask,维度为(K×H×W)
实验结果(参数设置)
BlendMask的超参数共有以下几个:
1、R,bottom-level RoI的分辨率,论文中的设置为56;
2、M,top-level prediction(A)的分辨率,一般比R小得多,论文中的设置为7
3、K,base的数量,论文中的设置为4
4、bottom module的输入特征,来自骨干网络 (C3,C5)or FPN(P3, P5),论文中使用P3,P5
5、bottom bases的采样方法,最近邻池化 or 双线性池化,论文中采用 双线性池化
6、top-level attention的插值方法,最近邻插值法 or 双线性插值,论文中采用双线性插值
这些超参数在后面都会做消融实验,为了与其他模型做合理对比,在消融实验中使用的BlendMask设置如下:R_K_M分别为28, 4, 4;bottom module的输入特征采用来自骨干网络C3和C5;top-level attention使用的是最近邻插值法,与FCIS一致;Bottom level使用双线性池化,与RoIAlign一致。
精度
先来看总体的实验结果。在COCO数据集上,BlendMask的精度和速度超越了其他单阶段实例模型,并且也基本超越了Mask R-CNN(R-50, no aug情况下除外)。
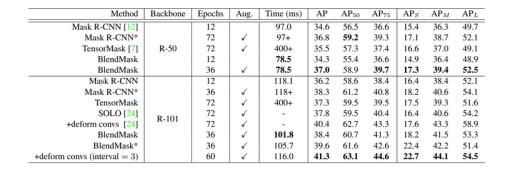
速度
同时也设置了一个快速版的BlendMask-RT,用以对比速度。快速版的改动如下:
1、prediction head的卷积数量减为3;
2、使用YOLACT中的Proto-FPN作为bottom module,将box tower和classification tower合并为一个(这里存疑);
从结果来看,BlendMask-RT比YOLACT在单张1080Ti上快了7ms,高出3.3AP

可视化效果
从可视化效果来看,BlendMask的效果明显好于Mask R-CNN,原因是BlendMask采用了更高的分辨率(56 vs 28);相比YOLACT,BlendMask使用到了多次的信息融合,因此对相邻的实例分割效果更好。具体原文中有很详细的分析

消融实验
从前面的分析可以看出,BlendMask其实是多个模型的优点的融合,因此作者也做了大量的消融实验,来证明所选取的BlendMask结构的优越性。
融合方法
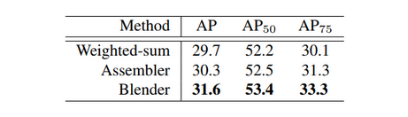
作者将blender改造成YOLACT和FCIS算法的融合方法进行实验,从实验结果可以看出,Blender的融合方法要更好。
此外,通过可视化中间过程,作者发现 BlendMask 可以编码两种局部信息,一是semantic masks,判断像素是否属于一个物体;二是position-sensitive feaures,判断像素是否在物体的某个部位。
如下图,四个base分别提取出了对不同的位置敏感的特征,这些特征可以帮助更好地分开相邻的实例,这也是比YOLACT更有效率的地方;而semantic masks可以让预测结果更加精细与顺滑。因此,BlendMask可以用更少的base学到更丰富的特征表示的原因。

特征分辨率(R)
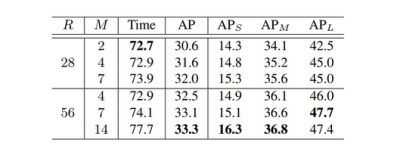
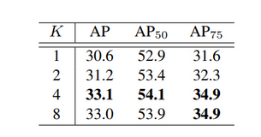
base数目(K)
对比 Mask R-CNN
熟悉Mask R-CNN的读者会发现,BlendMask其实与Mask R-CNN的结构思路很类似。如果将BlendMask的检测器部分从FCOS换成Faster R-CNN后,相似点就更明显了:
1、都使用了bbox形状的RoI提取实例,即用RoIPooler来定位实例并提取实例的特征
2、都有一个语义分割分支(FCN),对FPN或backbone提取的特征预测mask
BlendMask的整体结构其实就是在Mask R-CNN的box head后面加了一层卷积预测attention,再对mask head 生成的mask用attention进行blend。blend这块其实就是FCIS和YOLACT的创新点。
作者也在文末详细分析了一下两者的区别和BlendMask 的优势:
1、计算量小:使用一阶段检测器FCOS,相比Mask R-CNN使用的RPN,省下了对positon-sensitive feature map及mask feature的计算;
2、还是计算量小:提出attention guided blender模块来计算全局特征(global map representation),相比FCN和FCIS中使用的较复杂的hard alignment在相同分辨率的条件下,减少了十倍的计算量;
3、mask质量更高:BlendMask属于密集像素预测的方法,输出的分辨率不会受到 top-level 采样的限制。在Mask R-CNN中,如果要得到更准确的mask特征,就必须增加RoIPooler的分辨率,这样变回成倍增加head的计算时间和head的网络深度;
4、推理时间稳定:Mask R-CNN的推理时间随着检测的bbox数量增多而增多,BlendMask的推理速度更快且增加的时;
5、Flexible:可以加到其他检测算法里面;
第二次记录
1、基于Faster-RCNN,属于two-stage架构,RPN获取的bbox用于提取ROI特征;
2、mask分支与detection分支共享ROIAlign features;
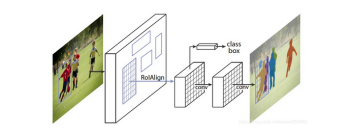
Bottom-up架构:
Bottom-up模型先对整图进行逐像素预测(per-pixel prediction),每个像素生成一维特征向量 (embedding)。由于进行的是逐像素级预测、且stride很小,局部一致性和位置信息可以很好的保存,但依然存在以下几个问题:
1、严重依赖逐像素预测的质量,context信息匮乏,容易导致非最优分割;
2、由于mask在低维提取,缺乏context信息,对于复杂场景的分割能力有限;
3、由于逐像素生成embedding,需要复杂的后处理方法;
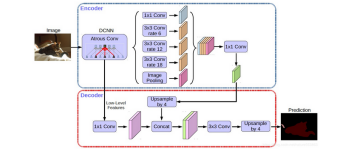
以Deeplab-v3+的Decoder为例 (语义分割):
Decoder以low-level特征为输入,执行per-pixel prediction;
以Mask-RCNN作为对比模型:
1、One-stage模型的执行效率更高;
2、Anchor-free模型的优势:
1)避免了anchor相关的超参设置,包括aspect-ratio、scale以及anchor匹配阈值等;
2)Anchor-free模型通常执行per-pixel预测,样本召回率更高;
3)节省了anchor相关的计算,尤其是anchor数目较多的情况下,能够提升执行效率;
BlendMask实现结构与算法原理
文章综合top-down和bottom-up方法,利用instance-level信息(bbox)对low-level per-pixel prediction进行ROI截取、以及attention加权,进而预测输出instance mask,主要贡献有以下几点:
1、设计了blender,用于生成proposal-based instance mask,在COCO上对比YOLACT和FCIS,分别提升了1.9和1.3 mAP;
2、基于FCOS提出简洁的算法网络BlendMask;
3、BlendMask的推理时间不会像two-stage detector一样,随着预测数量的增加而增加;
4、BlendMask的准确率和速度都优于Mask-RCNN,且mask mAP比最好的全卷积实例分割网络Tensor-Mask高1.1;
5、结合instance-level信息,bottom模块能同时分割多种物体,因而BlendMask可直接用于全景分割;
6、Mask-RCNN的mask输出固定为28×28,而BlendMask的mask输出像素可以很大;
7、BlendMask通用且灵活,只要一些小修改,就可以用于其它instance-level识别任务,例如关键点检测;
第三次记录
密集实例分割模型早期主要有两种:top-down apporach和bottom-up apporach。
top-down模型先通过一些方法获取box区域,然后对区域内的像素进行mask提取,这种模型一般有以下几个问题:
1、特征和mask之间的局部一致性会丢失,论文讨论的是Deep-Mask,用fc来提出mask;
2、冗余的特征提取,不同的bbox会重新提取一次mask;
3、由于使用了缩小特征图的卷积,位置信息会损失;
bottom-up模型先对整图进行逐像素预测(per-pixel prediction),每个像素生成一个特征向量,然后通过一些方法来对像素进行分组。由于进行的是逐像素级预测且步长很小,局部一致性和位置信息可以很好的保存,但是依然存在以下几个问题:
1、严重依赖逐像素预测的质量,容易导致非最优的分割;
2、由于mask在低维提取,对于复杂场景(类别多)的分割能力有限;
3、需要复杂的后处理方法;
高维特征包含整体的instance信息,而低维特征的则保留了更好的位置信息,论文的重点在于研究如何合并高低维特征,主要贡献有以下几点:
1、提出了proposal-based的instance mask合并方法,blender,在COCO上对比YOLACT和FCIS的合并方法分别提升了1.9和1.3mAP
基于FCOS提出简洁的算法网络BlendMask
BlendMask的推理时间不会像二阶检测器一样随着预测数量的增加而增加
BlendMask的准确率和速度比Mask R-CNN要好,且mask mAP比最好的全卷积实例分割网络Tensor-Mask要高1.1
由于bottom模块能同时分割多种物体,BlendMask可直接用于全景分割
Mask R-CNN的mask输出固定为28X28,BlendMask的mask输出像素可以很大,且不受FPN的限制
BlendMask通用且灵活,只要一些小修改,就可以用于其它instance-level识别任务中,例如关键点检测
BlendMask包含检测网络和mask分支,mask分支包含3个部分,bottom module用于预测score maps,top layer用于预测实例的attentions,blender module用于整合分数以及attentions,整体的架构如下图所示。
论文采用DeepLab V3+的decoder,该decoder包含两个输入,一个低层特征和一个高层特征,对高层特征进行upsample后与低层特征融合输出。这里使用别的结构也是可以的,而bottom module的输入可以是backbone的feature,也可以是类似YOLACT或Panoptic FPN的特征金字塔。
Experiment
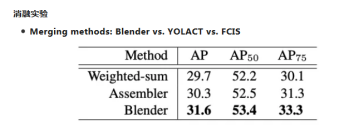
从上面表可以看出,论文将blender改造成其它两个算法的merge模型进行实验,从Table1可以看出,Blender的merge方法要比其它两个算法效果好。
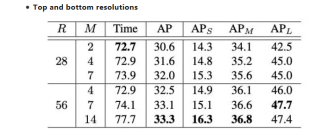
从上面表可以看出,随着resolution的增加,精度越来越高,为了保持性价比,R/M的比例保持大于4,总体而言,推理的时间是比较稳定的。
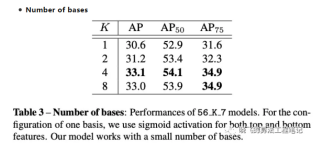
从Table3可以看出,K=4是最优。
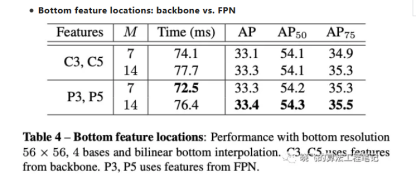
从图4可以看出,使用FPN特征作为bottom模块的输入,不仅效率提升了,推理时间也加快了。
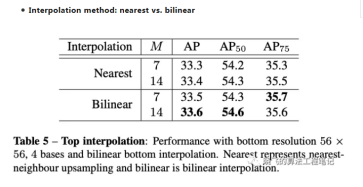
在对top-level attentions进行插值时,双线性比最近邻高0.2AP
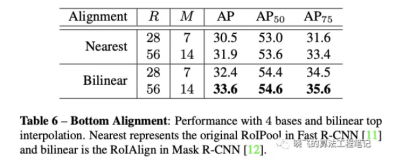
而对bottom-level score maps进行插值时双线性比最近邻高2AP。
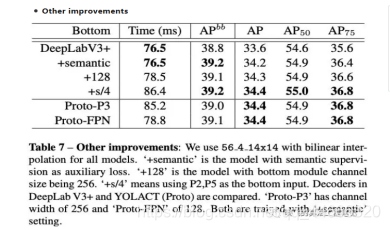
论文也尝试了其它提升网络效果的实验,虽然这些trick对网络有一定的提升,但是没有加入到最终的网络中。
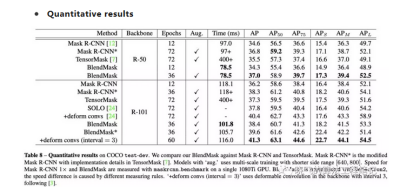
从结果来看,BlendMask在效果和速度上都优于目前的实例分割算法,但是有一点,在R-50不使用multi-scale的情况下,BlendMask的效果要比Mask R-CNN差。
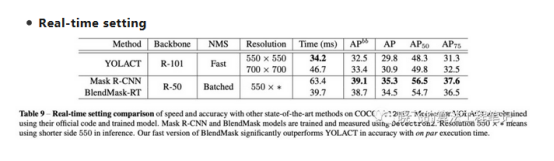
为了跟YOLACT对比,论文改造了一个紧凑版的BlendMask-RT: 1) 减少prediction head的卷积数 2) 合并classification tower和box tower 3) 使用Proto-FPN并去掉P7。从结果来看,BlendMask-RT比YOLACT快7ms且高3.3AP。

图4展示了可视化的结果,可以看到BlendMask的效果比Mask R-CNN要好,因为BlendMask的mask分辨为56而Mask R-CNN的只有28,另外YOLACT是难以区分相邻实例的,而BlendMask则没有这个问题。
Comparison with Mask R-CNN
BlendMask的结构与Mask R-CNN类似,通过去掉position-sensitive feature map以及重复的mask特征提取来进行加速,并通过attentions指导的blender来替换原来复杂的全局特征计算。
BlendMask的另一个优点是产生了高质量的mask,而分辨率输出是不受top-level采样限制。对于Mask R-CNN增大分辨率,会增加head的计算时间,而且需要增加head的深度来提取准确的mask特征 。另外Mask R-CNN的推理时间会随着bbox的数量增加而增加,这对实时计算是不友好的最后,blender模块是十分灵活的,因为top-level的实例attention预测只有一个卷积层,对于加到其它检测算法中几乎是无花费的。
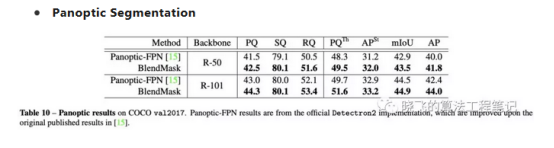
BlendMask可以通过使用Panoptic-FPN的语义分割分支来进行全景分割任务,从结果来看,BlendMask效果更好。
总结
BlendMask通过更合理的blender模块融合top-level和low-level的语义信息来提取更准确的实例分割特征,该模型综合各种优秀算法的结构,例如YOLACT,FOCS,Mask R-CNN,比较tricky,但是很有参考的价值。BlendMask模型十分精简,效果达到state-of-the-art,推理速度也不慢,精度最高能到41.3AP,实时版本BlendMask-RT性能和速度分别为34.2mAP和25FPS,论文实验也做得很充足。
参考文献
https://blog.csdn.net/lichlee/article/details/103897491
https://blog.csdn.net/sanshibayuan/article/details/104011910
https://mp.weixin.qq.com/s?__biz=MzI5MDUyMDIxNA==&mid=2247492995&idx=1&sn=da368b1d82b5f5ba997f966c5a11bf89&chksm=ec1c087adb6b816c65771b3f3b0854ed717ca6e2a5e4b8d0945a5cab4fa02583718c650ad379&mpshare=1&scene=1&srcid=&sharer_sharetime=1578740650770&sharer_shareid=29411222320ea29c693fa4a59b2d0388#rd

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









