






对目前看过的视频目标检测论文做一个简单的综述,也欢迎大家补充一些其他遗漏掉的,不错的视频目标检测论文。持续更新。。。
github:https://github.com/breezelj/video_object_detection_paper
论文详细笔记:https://blog.csdn.net/breeze_blows/article/details/104533004
参考链接:原文出处
目标检测已经做到很成熟了,但是视频目标检测确实还在发展之中,视频目标检测主要挑战在于在长视频中往往有些帧的质量非常差,比如目标物体出现以下情况,单纯的目标检测算法难以胜任(图片来自于FGFA论文)
既然单帧图片进行检测效果不好,视频目标检测的主要考虑就是如何去融合更多的时空上面的特征,比如从bbox,frame,feature,proposal等level进行特征融合,从而弥补在训练或者检测中单帧得到的特征的不足。大概就是从上面level上面去融合特征,怎么去融合特征。
数据集:常用的数据集就是ImageNet VID dataset, 其中训练集包含了3862个video snippets,验证集含有555个snippets。共有30个类,这些类别是ImageNet DET dataset类别的子集。有时候训练集也可以用ImageNet DET这30个类的图片集。
评价标准:沿用目标检测中的mAP,但是会根据目标的速度分为mAP(slow), mAP(medium), mAP(fast), 划分标准按照FAFG论文中的方法为求当前帧与前后10帧的IOU的平均得分值score,the objects are divided into slow (score > 0.9), medium (score ∈ [0.7, 0.9]), and fast (score < 0.7) groups。
下面是按照自己的理解进行的分类与整理。主要有两个方向,一个是关注于精度的提升即Accuracy,另外一个就是注重速度即speed,想达到Accuracy和speed的tradeoff。
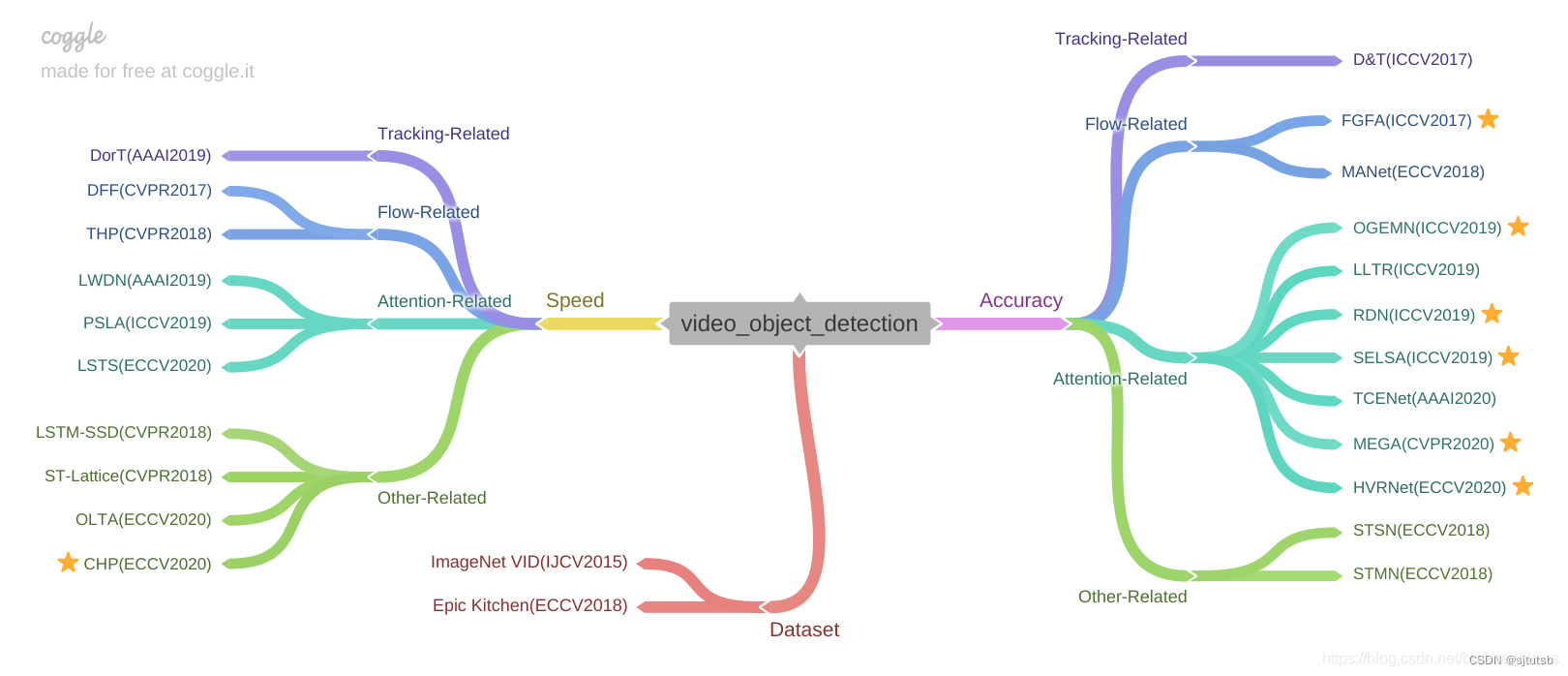
目录
1.Accuracy
Tracking-Related
Flow-Related
Attention-Related
Other-Related
2.Speed
Flow-Related
Attention-Related
Other-Related
1.Accuracy
Tracking-Related
D&T: Detect to Track and Track to Detect[paper][code]. 将跟踪引入到检测之中,通过使用track去学习不同帧feature之间的相似性,从而进行roi track得到帧间目标的位移,辅助检测。
Flow-Related
FGFA: Flow-Guided Feature Aggregation for Video Object Detection[paper][code]. 用bilinear warp融合FlowNet得到的当前帧与相邻帧特征,最后将这些特征进行加权aggregation。detection network采用R-FCN.详细分析:https://blog.csdn.net/breeze_blows/article/details/104533004
MANet: Fully Motion-Aware Network for Video Object Detection[paper]。 先提取出帧的feature和用FlowNet提取出帧间的光流信息,完成pixel-level的calibration,接着通过预测出来的instance的movement,其实就是R-FCN得到的proposal,进行instance-level的calibration,最后融合pixel-level和instance-level得到的feature用于训练和测试。
Attention-Related
RDN: Relation Distillation Networks for Video Object Detection[paper]. faster rcnn为backbone,用multi-stage的形式将support frame的proposal来逐步增强reference frames的proposal特征,以融合更多的proposal之间联系的特征。最后advanced stage出来的feature用于最后检测的分类和回归。并且提出BLR(Box Linking with Relations)的后处理方式。详细分析:https://blog.csdn.net/breeze_blows/article/details/104709770
SELSA: Sequence Level Semantics Aggregation for Video Object Detection[paper][code]. faster rcnn为backbone,用两个selsa模块(其实就是self-attention)融合多帧训练时候的proposal特征,达到Spectral Clustering的效果。详细分析:https://blog.csdn.net/breeze_blows/article/details/104533004
LLTR: Leveraging Long-Range Temporal Relationships Between Proposals for Video Object Detection[paper]. 受non local,relation network的启发设计了一个relation block来发掘视频序列中target frame与support frames提取的proposal之间的关系,在这个relation block中还引入了feat norm以及一个graph loss进一步提高准确率。详细分析:https://blog.csdn.net/breeze_blows/article/details/104533004
OGEMN: Object Guided External Memory Network for Video Object Detection[paper]. Memory和attention结合的方法,通过一个guided external memory network Nmem存储pix级别的Memory Mpix(来自当前帧经过backbone之后的feature与previous Mpix attention), 存储instance级别的Memory Minst(来自roi align之后的feature与previous Minst attention), 并且通过去除redundant feature来更新Nmem。
HVRNet: Mining Inter-Video Proposal Relations for Video Object Detection[paper]. 原来的视频目标检测文章都是在当前帧所在的视频序列中随机选取另外的support frames用来增强当前帧目标特征,作者指出当前视频序列只能知道该序列目标look like and how it moves in this video,has a little clue about object relations and variations among different videos。所以在文中分别用intra-video proposal relation and inter-video proposal relation来挖掘当前序列和不同序列中object 之间的relation,并且最后通过一个relation regularization来监督relation的学习,进一步提高了精度。详细分析见:https://blog.csdn.net/breeze_blows/article/details/108796729
Other-Related
STSN: Object Detection in Video with Spatiotemporal Sampling Networks[paper]. 用STSN模块从当前帧的邻近帧中学到spatially sample features,最后将这个spatially sample features结合到当前帧的feature用于最后的检测分类。 spatially sample features是通过DCN(deformable convolutional)完成的,不同于光流那种的聚合。
STMN: Video Object Detection with an Aligned Spatial-Temporal Memory[paper][code]. 与RNN结合的方法,当前帧和邻近帧经过backbone的feature都被送入STMM模块,STMM可以聚合先前所有帧在时间t-1的feature和当前时间t所有当前帧与邻近帧的feature,最后将聚合的feature用于检测与分类。
2.Speed
Flow-Related
THP: Towards High Performance Video Object Detection[paper]. 在DFF和FGFA基础上进行改进,提出sparsely recursive feature aggregation:inference时关键帧feature的聚合方式,spatially-adaptive partial feature updating:关键帧feature聚合到非关键帧feature的方式,temporally-adaptive key frame scheduling:关键帧的选取方式,达到了较高速度而且不错的精度.The mAP score is 78.6% at a runtime of 13.0 / 8.6 fps on Titan X / K40
DFF: Deep Feature Flow for Video Recognition[paper][code]. 区分关键帧与非关键帧,对于关键帧直接检测,对于非关键帧,就利用warp融合关键帧经过backbone得到的feature,FlowNet提取非关键帧的光流信息,最后用于最后非关键帧的检测这样做的目的主要是为了加速非关键帧的检测速度,因为视频中非关键与关键帧特征的相似性。
Attention-Related
LWDN: Video Object Detection with Locally-Weighted Deformable Neighbors[paper]. 受flow warp和non local的启发提出了一个LWDN模块(有点DCN的意思)用来聚合邻近帧的feature,并且在训练过程中维护了一个memory,逐步用memory和LWDN将关键帧的feature align到当前帧中,VID上面mAP为76.3, 在Titan X GPU有20fps的速度。
PSLA: Progressive Sparse Local Attention for Video Object Detection[paper]. a temporal feature Ft和关键帧经过backbone之后的feature经过Recursive Feature Updating (RFU)聚合优化Ft,以及输出用于关键帧检测与分类的feature。Ft和非关键帧经过backbone之后的feature通过Dense Feature Transforming (DenseFT)输出用于非关键帧检测和分类的feature,RFU和DenseFT的核心是PSLA模块,其实就是non local的一种变体。
Other-Related
LSTM-SSD: Mobile Video Object Detection with Temporally-Aware Feature Maps[paper]. 将SSD作为Mobilenet architecture,将其中的conv替换为depthwise separable convolutions,最后将LSTM插入到SSD中用于提取视频帧的空间和时间信息,据文中描述在cpu上面可以有15fps,不过mAP大概40-50的样子
ST-Lattice: Optimizing Video Object Detection via a Scale-Time Lattice[paper]. 先在稀疏的关键帧上进行检测,然后利用提出的尺度-时间网格(Scale-Time Lattice), 从不同尺度,时间维度辅助非关键帧的检测,进行位置修正,可以达到 79.6 mAP(20fps)和 79.0 mAP(62 fps)
CHP: CenterNet Heatmap Propagation for Real-time Video Object Detection[paper]。原来的所有视频目标检测算法都是基于two-stage的目标检测算法进行改进(大多数为Faster rcnn和R-FCN),这样就难以做到实时。在这篇文章中作者首次提出基于one-stage的目标检测算法即CenterNet进行视频目标检测,主要就是通过不断地propagate 前一帧的heatmap到当前帧,这里的heatmap每个点表示当前位置是否有目标的置信度。其实也是用其他帧的feature来进一步refine当前帧的feature。最后online performance:76.7% mAP at 37 FPS, offline performance:78.4% mAP at 34 FPS。
附上自己整理的实验结果图
无后处理的
加上后处理步骤的,∗ indicates use of video-level post-processing methods(e.g Seq-NMS, tubelet rescoring, BLR), △ indicates using data augmentation.
最后放两张论文中的实验图(分别来自PSLA和MEGA)















 1424
1424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









