







deepseek的出现瞬时成了现象级、国运级产品,爆火导致的用户规模增加以及被攻击导致经常出现服务器忙的现象,调侃一句就是”你回它是秒回,它回你是轮回“:

好在deepseek将模型开源,并且有已经量化到可以在我们本地电脑部署,本文我们介绍从PC端到手机端一站式部署deepseek。
首先说明下各个版本模型要求的显存大小:
- 1.5B 需要2G显存
- 7B、8B 需要6G显存
- 14B 需要10G显存
- 32B 需要20G显存
- 70B 需要40G显存
- 671B 需要400G显存,这个才是真正的满血deepseek,前边都是小模型蒸馏。
模型量越大,生成的效果越好,对电脑的配置就越高,生成速度也和模型的大小息息相关。如果要有很好的体验,那就留一点性能存量,比如我使用的是 M3 的Mbp,内存为 16GB,理论上可以跑 14B 的模型,但是很慢,一秒才吐三四个字,而如果是小一些的话,一秒就八九个字了,十分流畅。
接下来介绍如何本地部署deepseek并且集成chatbot页面。
首先需要安装ollama,从官网https://ollama.com/下载对应系统的安装包安装即可。
接下来下载cherry studio,官网下载地址:https://cherry-ai.com/。
由于此前文章介绍过了ollama安装和使用,这里直接介绍cherry studio。
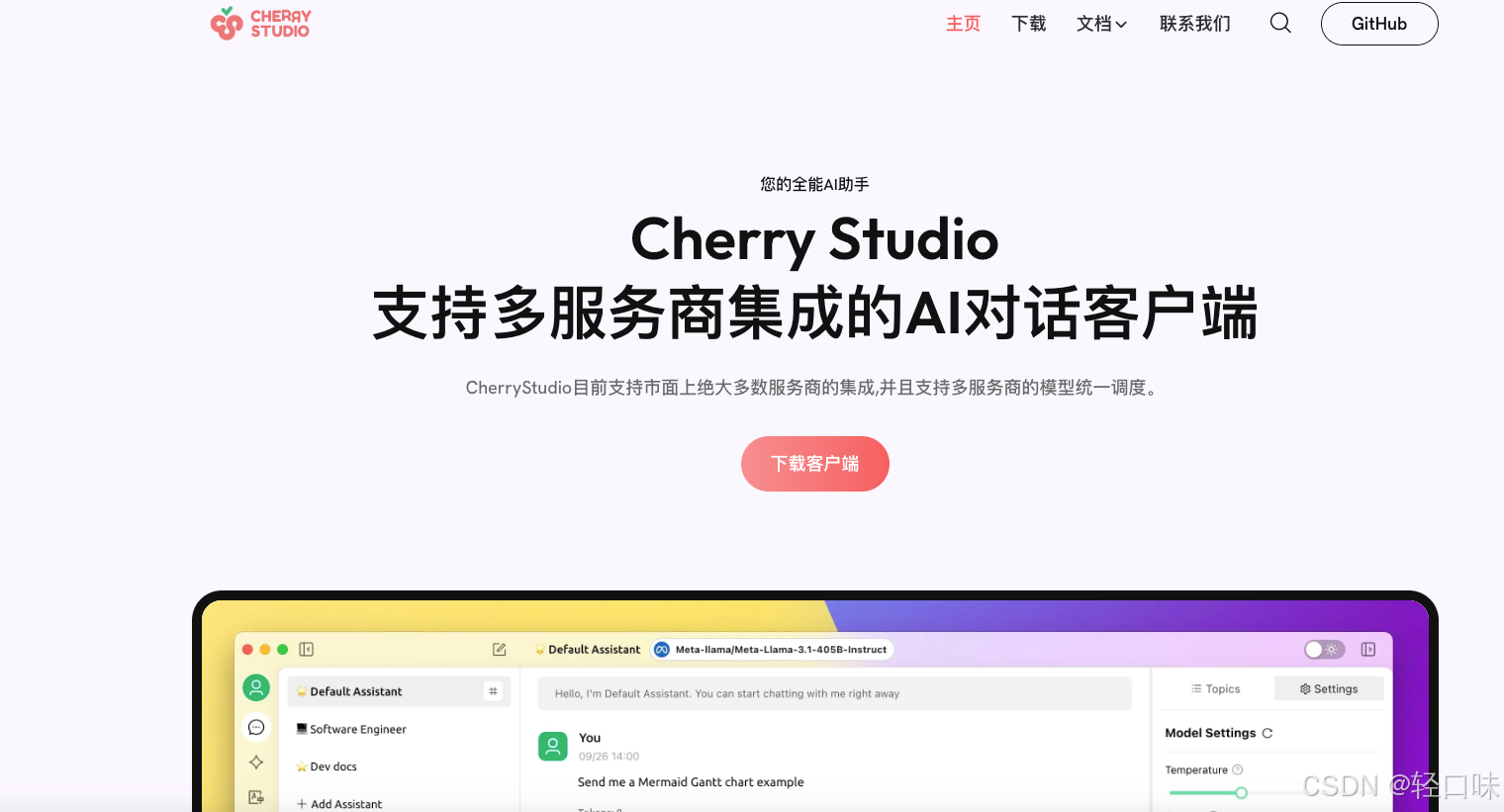
下载完成后界面:
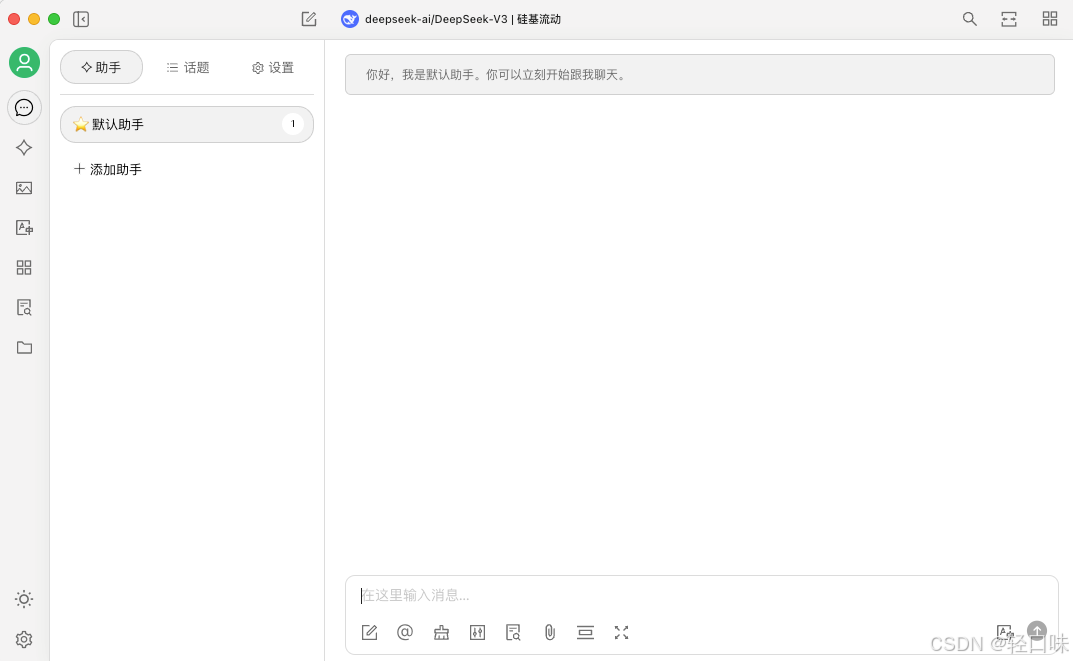
点击设置,模型服务选择ollama,点击开启:
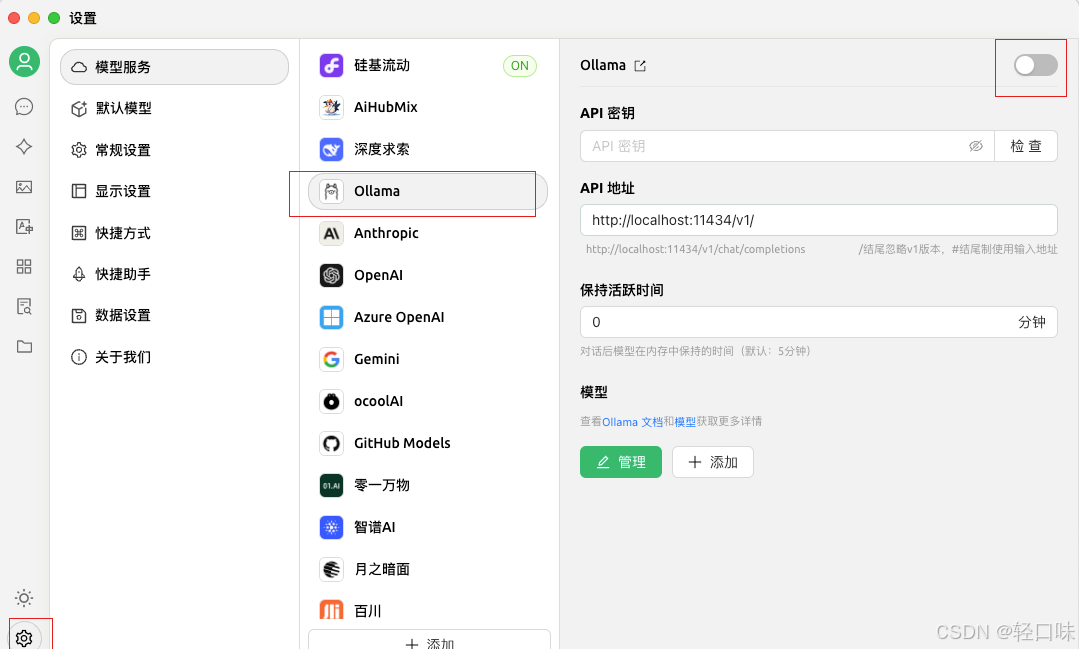
点击添加后选择模型deepseek-r1模型:
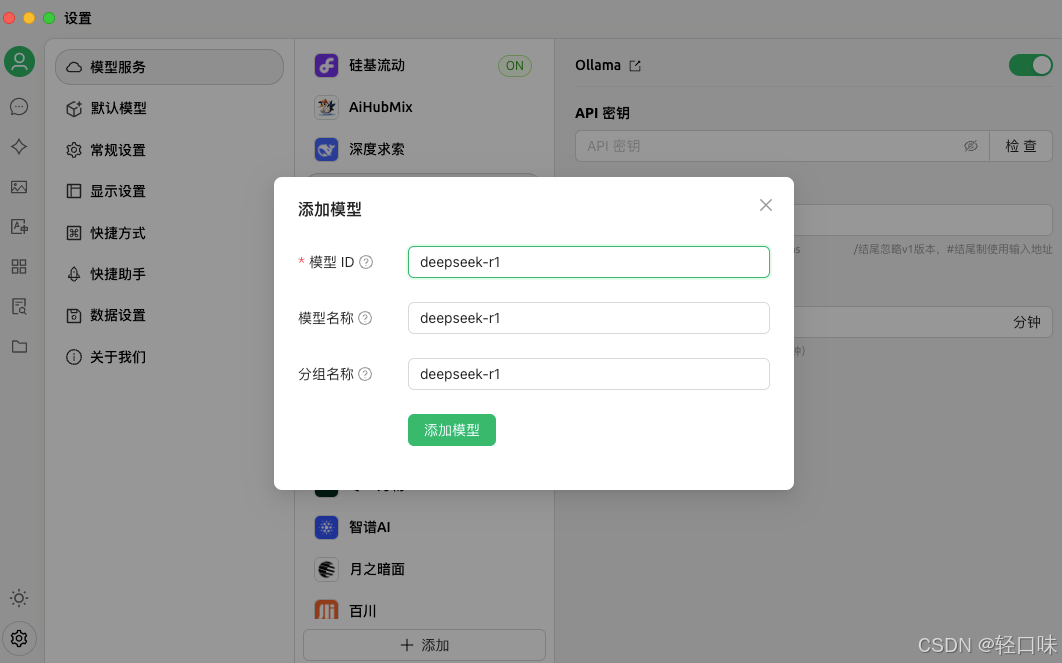
点击检查api秘钥:
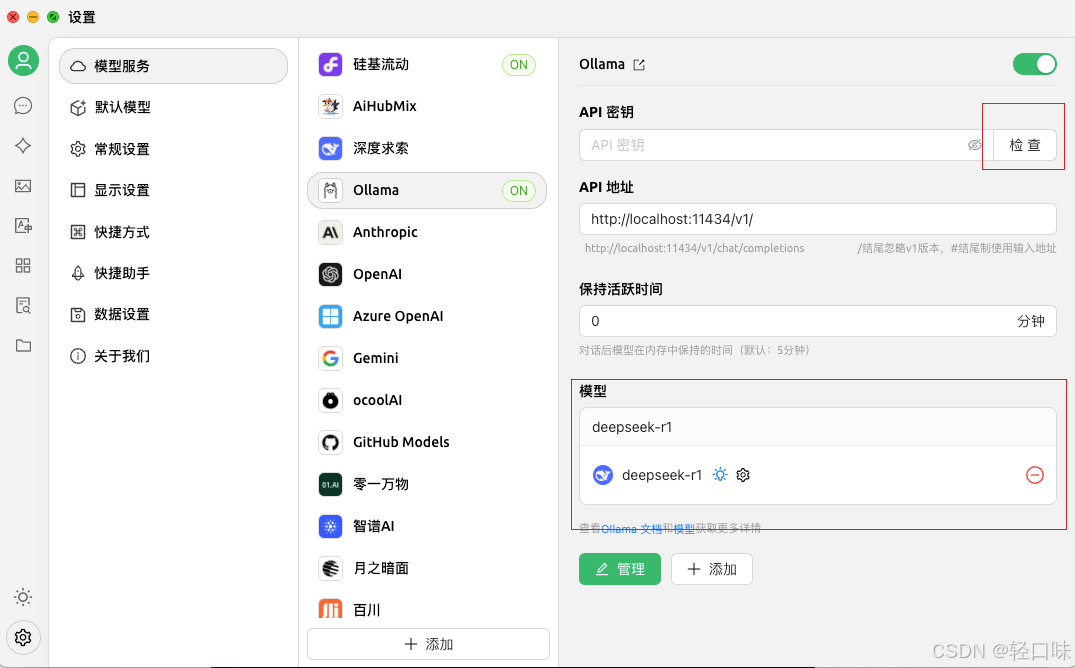
选择要检查的模型:
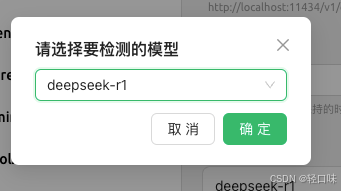
这里检查失败了,因为本地安装模型是1.5b,这里输入模型的时候有写全:deepseek-r1:1.5b,这时候点击确定后显示连接成功。
这时候点击聊天图标,选择对应模型后就可以开始使用了:
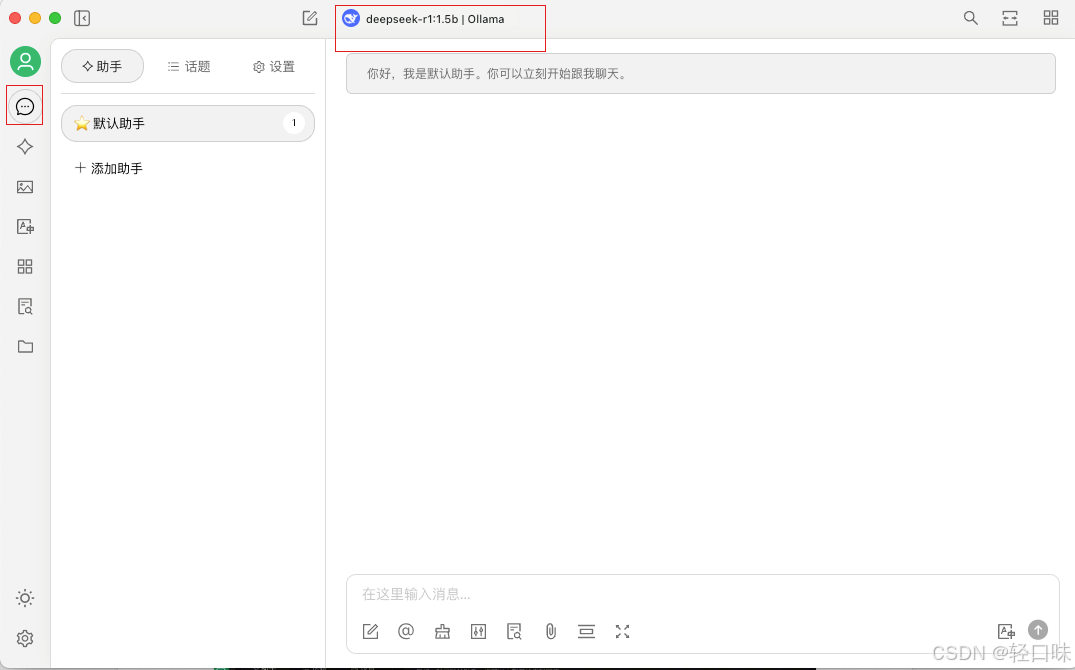
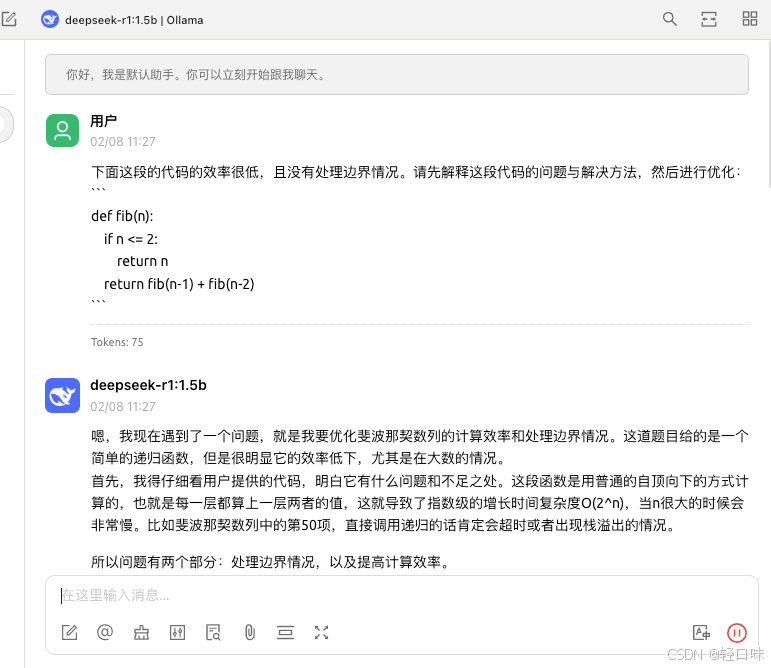
由于使用的是1.5的,速度杠杠的:
接下来介绍在Android端和iOS端部署进行本地部署。
对于iOS需要切换到美区,注册美区Apple ID,然后下载PocketPal AI:

Android端可以从github(https://github.com/a-ghorbani/pocketpal-ai?tab=readme-ov-file#android)直接下载后安装(跳转googleplay,也可以自己安装运行)。
安装后选择go to module:
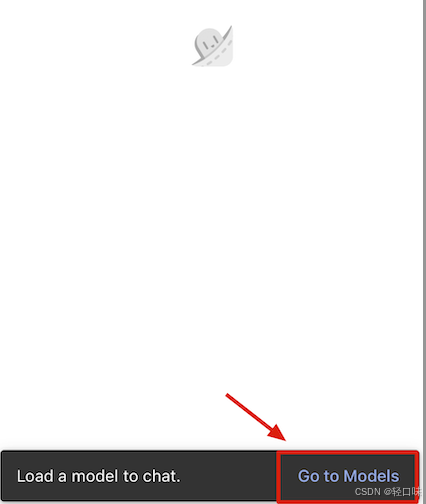
点击 “+” 选择 hugging Face:
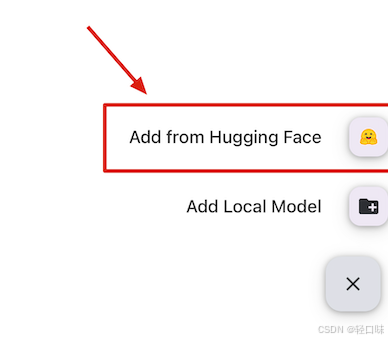
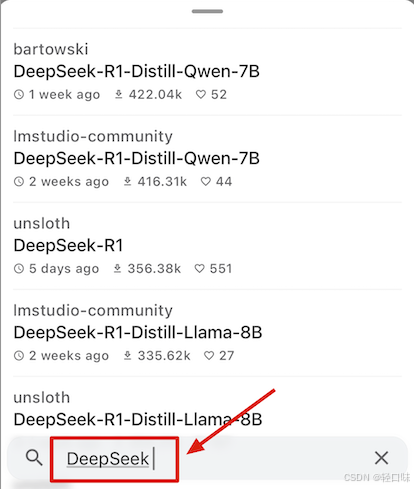
搜索deepseek R1,选择适合自己的模型,并下载
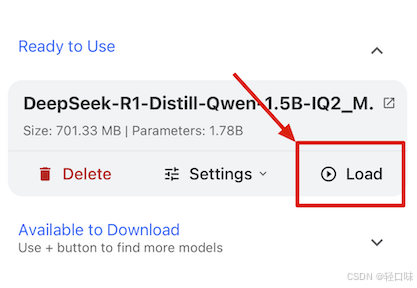
返回首页,点“load”就可以发起对话了
接下来可以在手机使用本地离线模型聊天了。
这里需要注意手机端离线模型安装需要访问国外网站。



















 2314
2314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











