




 本文分析了在Cortex-A8处理器上memcpy慢的问题,特别是在从uncached到cached区域的拷贝。通过研究内核和用户空间的memcpy实现、页表属性以及预取指令,找到了优化方案。首先,使用内核memcpy提升性能;其次,通过设置页表属性L_PTE_MT_DEV_SHARED,显著提高uncached区域的写入速度。经过优化,uncached到uncached、uncached到cached以及cached到uncached的拷贝速度均有大幅提升。
本文分析了在Cortex-A8处理器上memcpy慢的问题,特别是在从uncached到cached区域的拷贝。通过研究内核和用户空间的memcpy实现、页表属性以及预取指令,找到了优化方案。首先,使用内核memcpy提升性能;其次,通过设置页表属性L_PTE_MT_DEV_SHARED,显著提高uncached区域的写入速度。经过优化,uncached到uncached、uncached到cached以及cached到uncached的拷贝速度均有大幅提升。
公司产品涉及到视频编解码和人脸识别,但是出现帧率太低的现象,同事做了一些测试,最后问题定位到应用程序中memcpy慢,特别是由uncached区域(视频采集buf,使用mmap对/dev/mem映射到用户空间)到cached区域(用户空间malloc),因此需要想办法进行下优化。
首先交代下设备处理器背景,处理器是公司自研,使用ARM Cortex-A8处理器核,CPU为800MHZ,SAXI总线为533MHZ。后续一系列测试都是在相同的clk下进行,保证测试数据的硬件环境一致,有可对比性。
同事对系统下各种场景的memcpy进行一系列测试。测试数据如下。
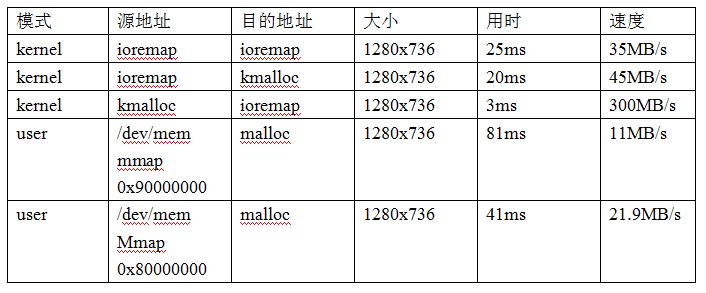
对这个表的测试方法进行下说明,kernel和user空间下分别使用do_gettimeofday和gettimeofday获取时间,公司SOC的地址空间中0x80000000开始是ddr空间,kernel的cmdline中mem=256MB,因此0x80000000-0x90000000为lowmem。
mmap映射/dev/mem可以完成整个4G空间的映射(关于mem驱动的原理,可以看我的另一篇学习powerpc /dev/mem的博文,http://blog.csdn.net/skyflying2012/article/details/47611399),但是具体访问权限以及属性还需要看mem驱动中mmap函数的实现。
公司设备的应用场景是从物理地址0x90000000的uncached区域到cached区域进行memcpy,测试速度仅有11MB/s,这对于1080P的人脸识别完全不够,优化是必须的。
仔细对比分析这组测试数据,我有以下几个疑问。
1 用户空间mmap mem的uncached区域(mem驱动中映射页表属性默认是uncached)向malloc出来的cached缓冲区拷贝,0x80000000区域为什么比0x90000000区域的拷贝快?
2 kernel下ioremap的uncached区域向kmalloc的cached区域拷贝,为什么比用户空间的快很多?
3 kmalloc的cached区域向ioremap的uncached区域拷贝,为什么比kernel下ioremap的uncached区域向kmalloc的cached区域拷贝要慢很多?
3个问题逐步递进,都分析明白解决了,特别是第2点,内核memcpy远快于用户空间,就能找到一些对用户空间memcpy的优化方法。
那我们就来逐步的分析下这3个问题。
1 用户空间mmap mem的uncached区域向malloc出来的cached缓冲区拷贝,0x80000000区域为什么比0x90000000区域的拷贝快?
这2者都是在用户空间进行测试,测试代码完全一致,统计方法也都一致,memcpy都是使用的libc库的实现。为什么memcpy速度不一样,想来想去也只有可能是这2个区域的页表属性不一样,有可能一个cached一个uncached,这个需要从mem驱动的实现下手。
公司kernel版本是3.4.55。mem实现在kernel的driver/char/mem.c中,找到mem的mmap实现,如下
static int mmap_mem(struct file *file, struct vm_area_struct *vma)
{
size_t size = vma->vm_end - vma->vm_start;
if (!valid_mmap_phys_addr_range(vma->vm_pgoff, size))
return -EINVAL;
if (!private_mapping_ok(vma))
return -ENOSYS;
if (!range_is_allowed(vma->vm_pgoff, size))
return -EPERM;
if (!phys_mem_access_prot_allowed(file, vma->vm_pgoff, size,
&vma->vm_page_prot))
return -EINVAL;
vma->vm_page_prot = phys_mem_access_prot(file, vma->vm_pgoff,
size,
vma->vm_page_prot);
/* Remap-pfn-range will mark the range VM_IO and VM_RESERVED */
if (remap_pfn_range(vma,
vma->vm_start,
vma->vm_pgoff,
size,
vma->vm_page_prot)) {
return -EAGAIN;
}
return 0;
}mmap_mem开始会进行映射区域的一些检查,然后设置映射属性,最后调用remap_pfn_range建立真正的页表。我们所关心的是映射属性,就是phys_mem_access_prot的实现。该函数在mem.c中有一个实现,对于ARM架构来说,phys_mem_access_prot默认设置属性位uncached。
但是由于公司设备在menuconfig时定义了CONFIG_ARM_DMA_MEM_BUFFERABLE(该选项使DMA一致性映射时属性为bufferable而不是uncached,但是发现一致性映射工作正常,很奇怪为什么选这个),phys_mem_access_prot的实现在arch/arm/mm/mmu.c中,如下。
#ifdef CONFIG_ARM_DMA_MEM_BUFFERABLE
pgprot_t phys_mem_access_prot(struct file *file, unsigned long pfn,
unsigned long size, pgprot_t vma_prot)
{
if (!pfn_valid(pfn))
{
return pgprot_noncached(vma_prot);
}
else if (file->f_flags & O_SYNC)
{
return pgprot_writecombine(vma_prot);
}
return vma_prot;
}
EXPORT_SYMBOL(phys_mem_access_prot);
#endif应用程序测试代码中mem设备open时设置了属性O_SYNC,因此主要看pfn_valid实现了,看字面意思,该pfn页有效,则属性为bufferable,反之为uncached。pfn_valid在arch/arm/mm/init.c中,如下。
#ifdef CONFIG_HAVE_ARCH_PFN_VALID
int pfn_valid(unsigned long pfn)
{
return memblock_is_memory(__pfn_to_phys(pfn));
}
EXPORT_SYMBOL(pfn_valid);memblock_is_memory实现在/mm/memblock.c中,该函数实现这里不详细说了,后续在我的内存管理学习笔记专栏里会详细学习。
这里简单说明下,memblock.c中维护了memblock.memory(可用)和memblock.reserve(保留)2个链表,arm-linux启动中,在paging_init建立页表前,会调用arm_memblock_init对memblock链表进行初始化,arm_memblock_init中会将cmdline中指定的lowmem调用memblock_add添加到memblock.memory链表中(公司kernel没有配置CONFIG_HIGHMEM)。
而memblock_is_memory是在memblock.memory链表中搜索是否有该物理页。
因此pfn_valid对于lowmem(0x80000000-0x90000000)返回ture,对于其他物理地址则返回false。
返回上级函数phys_mem_access_prot,一目了然,该函数的逻辑是对于mmap映射lowmem(0x80000000-0x90000000)区域,页表映射属性prot配置为bufferable,其他区域页表属性配置为uncached。
这样第一个问题就解决了,对于公司设备的kernel,用户空间mmap mem驱动,物理地址在0x80000000-0x90000000区域内,为bufferable,其他区域为uncached(这样reg空间也可以映射出来访问,实现用户空间驱动)。所以映射lowmem区域的拷贝速度要快于其他区域。
不过要说明下的是,这个问题是因为该kernel配置了CONFIG_ARM_DMA_MEM_BUFFERABLE,使用了arm特定的phys_mem_access_prot实现。
如果不配置该选项,则mmap_mem使用了mem.c中的phys_mem_access_prot实现。该实现中如果open时指定了O_SYNC或者O_DSYNC,则所有空间的映射属性都配置为uncached。
2 kernel下ioremap的uncached区域向kmalloc的cached区域拷贝,为什么比用户空间uncached到cached区域拷贝要快很多?
这个问题如果解决,对于优化用户空间memcpy会很有帮助,对于同事测试的数据,我从以下3个方面进行了分析调试。
(1)统计时间的准确性不一致,需要修改。
kernel下使用do_gettimeofday获取时间,kernel下是没有调度的(进程调度发生在由内核态返回时,检查是否有就绪进程,然后调度。内核态下即使发生中断,都还只是内核态下的相互切换,不会有调度),但是用户空间有进程调度(中断 系统调用等异常,导致陷入内核态,再返回时产生调度),进程调度对时间统计准确性有影响,一是会导致gettimeofday时间统计没有内核态下那么准确(有部分时间是其他进程的开销),二是进程调度还需要切换进程的页表(每个进程独立拥有16KB内存页表),进程调度导致页表切换,MMU需要重新读入TLB,我想也会对性能有所影响吧。
因此要想办法统一时间统计方法,使应用程序暂时不再调度。我的解决方法如下。
a 保证应用程序不产生调度
在应用程序中将处理器的寄存器空间mmap出来,在开始测试前配置中断寄存器将中断全部mask,测试结束再unmask,保证没有中断产生而陷入内核态,
再对malloc区域提前访问,保证页表提前建立,不会产生缺页异常(malloc缓冲区在访问时才缺页异常建立页表)。
不使用gettimeofday系统调用,二是直接读取timer计数,利用计数来计算用时。
b 对于内核测试代码,也不使用do_gettimeofday,直接读取timer计数,计算用时,与应用程序统一。
对应用程序进行修改后,再次测试1MB数据从uncached区域到cached区域拷贝,计算用时是68ms,速度为14.7MB/s。相比于同事的测试数据的确有所提升,这说明用户空间进程调度对时间统计是有些影响,但是排除进程调度影响后的测试速度跟内核的速度还是相差很大。看来根本原因还没有找到。
(2)memcpy实现不一致。
kernel不依赖于任何库,自己实现memcpy,应用程序的memcpy是依赖于libc中的实现,这2者实现可能有差异。
这个的解决方法就简单粗暴了,对比memcpy的实现呗。
kernel的memcpy实现在arch/arm/lib/memcpy.S中,是汇编代码,粗略看了下实现。
主要是使用PLD指令(armv5以上支持)进行数据预取,并且使用stmia/ldmia进行数据的32 bytes批量读写。
而对于应用程序的memcpy实现,如果去找libc的实现,要麻烦些,需要顺着所使用的编译器一步步的找相应的版本,
这里想了一个懒办法。就是将应用程序静态编译,然后反汇编找memcpy实现,在反汇编文件中找到memcpy实现,如下:
00014104 <memcpy>:
14104: e3520003 cmp r2, #3 ; 0x3
14108: e92d07f0 push {
r4, r5, r6, r7, r8, r9, sl}
1410c: 8a000009 bhi 14138 <memcpy+0x34>
14110: e3520000 cmp r2, #0 ; 0x0
14114: 0a000005 beq 14130 <memcpy+0x2c>
14118: e3a0c000 mov ip, #0 ; 0x0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









