






SHAP 分析的三种应用场景及其意义
随着SHAP分析应用的深入,SHAP在三个场景具有广泛的应用,体现出独特的分析价值:
1. 全局性解释:展示变量重要性
-
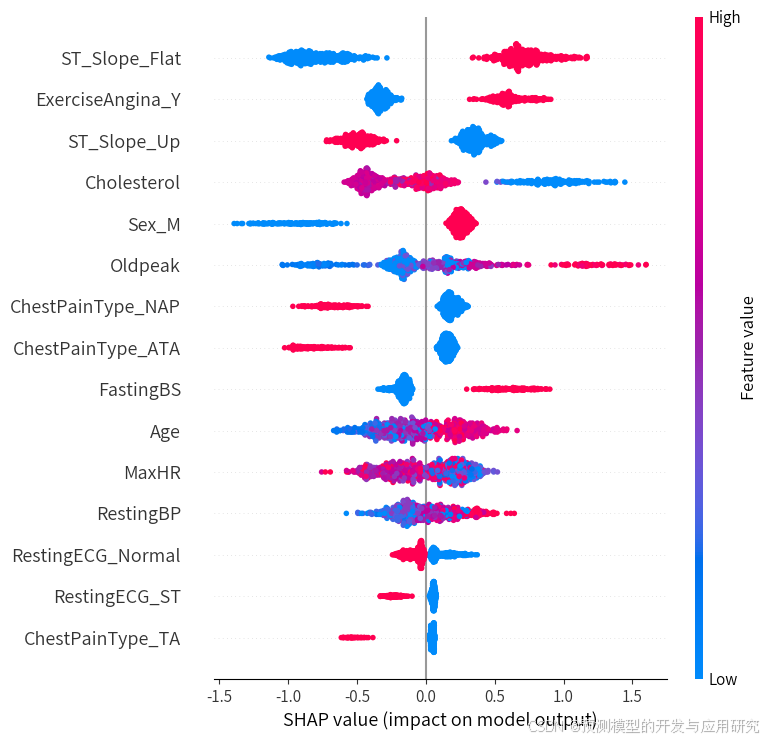
在众多机器学习模型中,如随机森林、神经网络等,模型内部的计算逻辑往往较为复杂,难以直观理解各个输入变量对最终预测结果的贡献程度。而 SHAP 分析通过计算每个特征的 SHAP 值,可以清晰地呈现出不同变量在模型中的重要性排序,图形展示是SHAP的蜂窝图和柱形图。
-
应用场景是在危险因素鉴定或者预测模型构建过程中,定量预测变量与结局变量之间的关系,借此展示对结局有重要影响的变量,类似变量的重要性,且变量之间SHAP值是可比的。需要注意的是,某个变量的SHAP值解释的时候,要在当前变量组合的前提下进行解释,换一个变量组合,SHAP就不同了。
2. 全局性解释:单个变量与结局变量之间的关系
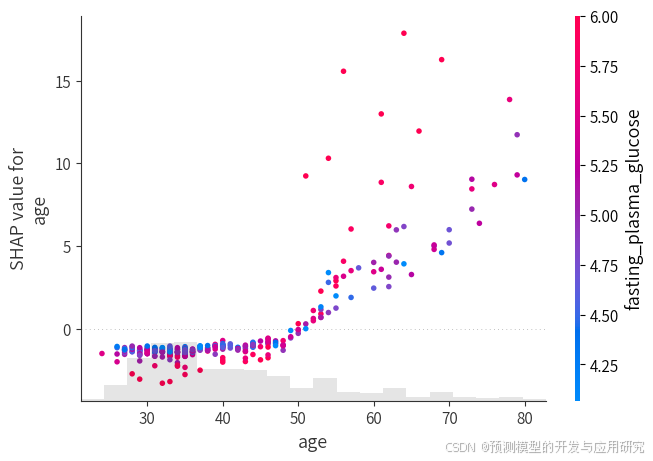
- 当我们想要探究某个特定变量如何影响结局变量时,SHAP 分析可以发挥重要作用。它能够展示出随着某个变量的变化,结局变量是如何变动的,这种关系可能是线性的,也可能是非线性的。SHAP典型图是散点图。
- 应用的场景,是危险因素鉴定场景,在通过以上的蜂窝图了解了变量具有重要作用之后,接下来可以深入观察了解这个变量随变量值的变化其对结局变量贡献的变化,还可以结合立方样条拟合曲线关系来配合分析。这种分析对于二分类结局变量具有特别的重要性,这种分析将结局分类变量转变一个连续变量,让我们可以使用散点图来观察变量间关系。当某个变量的SHAP值为零的时候时一个关键点,代表了预测变量值从支持一个结局到支持另外一个结局。
3. 局部性解释:解释单个样本的预测结果,精准化诊断
- 除了全局性解释,SHAP 分析在局部性解释方面也有重要应用。它可以针对单个样本,分析每个特征对该样本预测结果的影响。典型的图是力图和瀑布图。
- 应用场景是在模型预测的时候,给出各个变量当前值对于预测结果的贡献,如果预测结果是阳性的,那对预测结果有重要贡献的变量就是用户的病因,需要重点关注和处理。可以说是根据患者的具体状况,精准地给出了对应的诊断和措施,实现了“精准化”医疗。 我将其用在临床预测模型APP的预测过程中,赋予了预测结果更大的价值。

4. 总结
SHAP分析可以展示变量重要性、描述变量间的关系、给出变量当前值对预测结果的贡献,展现出了巨大的分析价值,并且除了以上的结果,SHAP分析还可以做交互作用分析,但是具体的应用场景话费意义还有待遇进一步挖掘。


















 2422
2422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











