







 本文探讨了DCNV2如何改进早期DCN模型,解决输入尺寸受限和crossnetwork与DNN容量不平衡的问题。它引入了灵活的随机交叉模式,通过低秩矩阵分解优化模型容量,并借鉴MOE思想进行跨空间融合。关键点包括自定义的embedding层、增强的crossnetwork结构和loss函数调整。
本文探讨了DCNV2如何改进早期DCN模型,解决输入尺寸受限和crossnetwork与DNN容量不平衡的问题。它引入了灵活的随机交叉模式,通过低秩矩阵分解优化模型容量,并借鉴MOE思想进行跨空间融合。关键点包括自定义的embedding层、增强的crossnetwork结构和loss函数调整。
DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems 这篇paper,不是指的图像里面的可形变卷积。
DCN v1可参考这篇blog,比较详细清晰。
前言
DCN V2提出是为了更好的在大型工业界的实践中应用,多项式的特征交叉仅仅被输入尺寸所表征(是指特征交叉是限定死的,按照输入的特征穷举交叉),大大的限制了其在随机交叉模式上的灵活性。而且,对于cross network和dnn之间限定好的容量是不平衡的,这些都局限了DCN在大规模的生产数据上的表现。
之前的工作都要致力于怎么联合好显式和隐式的表达,有parallel结构和stacked两种架构。
parallel架构,这里的开山之作就是wide&deep模型,deep部分使用dnn,dense特征,wide部分使用lr学习sparse交叉的特征,负责学习cross特征,两者联合训练。deepfm改善了wide部分,使用fm来替代学习特征交互。dcn介绍了一种cross network,强行用公式限定了交叉特征的部分。Xdeepfm通过生成多种特征图来增强了dcn部分的表现能力,增加了当前层和输入层的pairwise交互。
stacked架构,介绍了一种显式的交互层,在embedding layer和DNN 模型之间显式的增加了特征交互。如PNN,用了内积层和外积层做一个pairwise的交互层,但OPNN层的计算消耗太大。
proposed structure
embedding layer
输入:sparse+dense,输出:combined feature,dense会被norm。
sparse->hash到高维-〉用W来降维,本文不同的是embedding size是可以任意的。
cross network
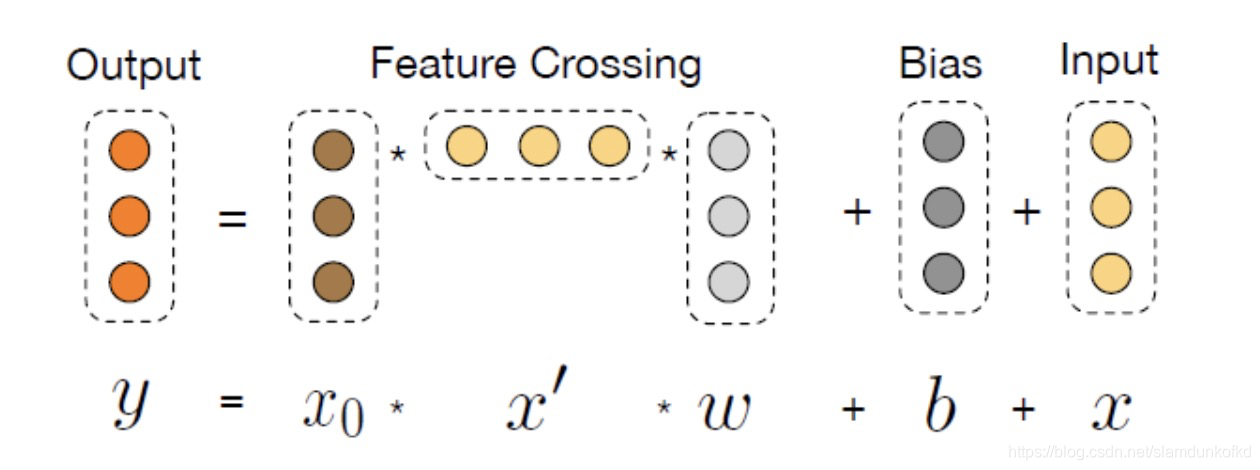
这是dcn v1 的cross network。公式为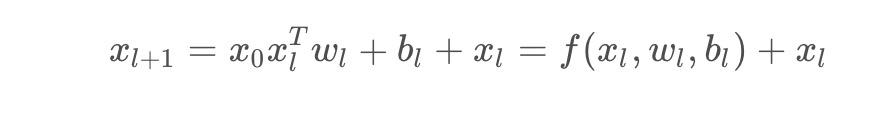
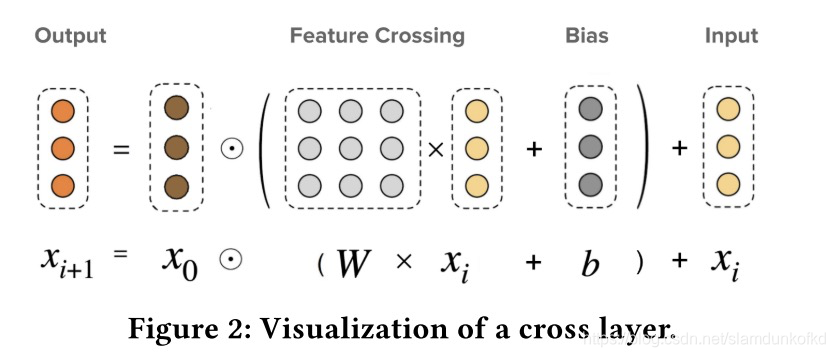
这是dcn v2 的cross network。公式如: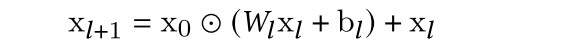
dcn v2的cross网络区别不大,增大了权重参数,当权重多行退化为一行时,该网络就退化成v1的。
deep layer
mlp+激活层
deep and cross combination
联合cross network和deep network有两种结构,一种是串行的,一种是并行的。哪一种结构更好,取决于数据是怎么分布的。
如下图所示,串行结构就是把cross network的输出喂给deep network,作为其输入。而并行结构,则是两个网络并行处理,最后用一层mlp来融合两个网络的输出。
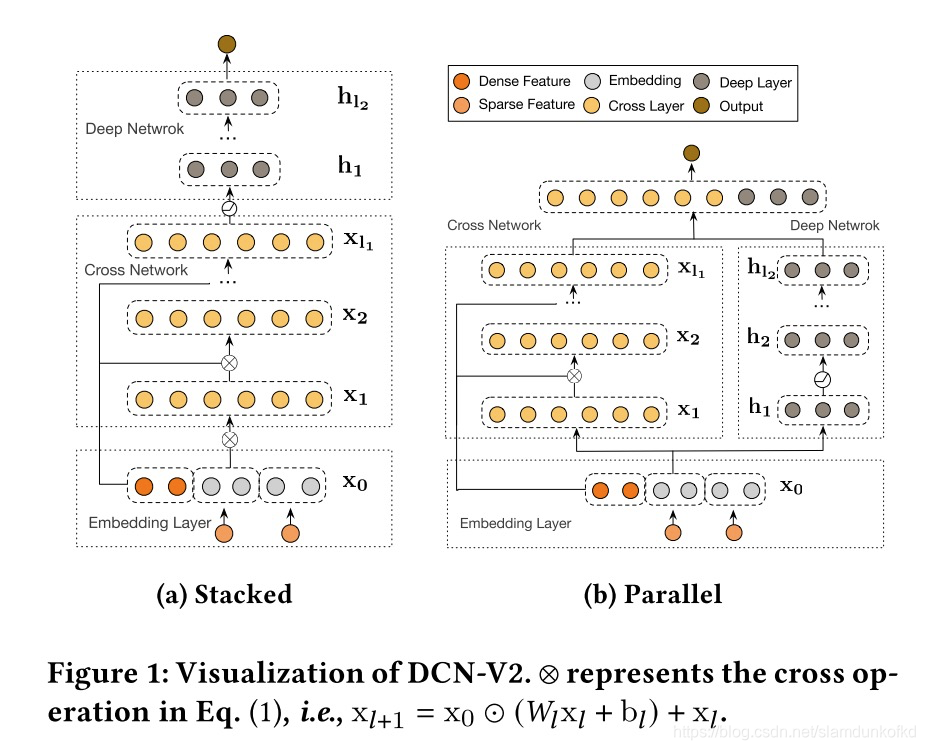
最后网络的loss使用logloss(二分类的交叉熵)加上l2正则项。

将dcn中的低秩矩阵分解
在实际的工业模型中,模型的容量很重要,这会限制serving的资源和时延。低秩矩阵分解被广泛的用于降低计算量,一个dense martix 分解成两个高瘦的矩阵
。当r<d/2时,计算量就会减少。在实际中发现,学习的矩阵在数值上是低秩的。相比于初始化的矩阵,可学习的矩阵展示了一个更快的频谱衰减模式。Rt表示大多数达到了容忍度,被保存在top K的奇异值中。
作者这边提出将cross-layer的w分解(如下一个公式),用两个维度较低的矩阵来表示,这里可以有两个解释:1.我们学习在一个更小的特征空间学习feature cross;2.我们project输入到低维空间上,在把输出project回来。
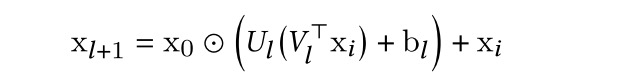
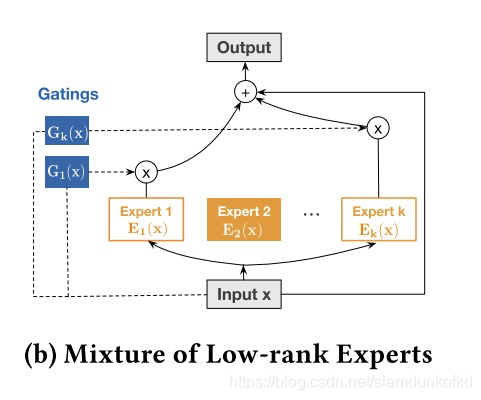
这里借鉴MOE多专家系统的思路,将矩阵分解弄个N个,最后用一个gating来自适应的选择这K个专家系统,公式和可视化图如下,算是融合了K个小空间内的cross-layer的结果。
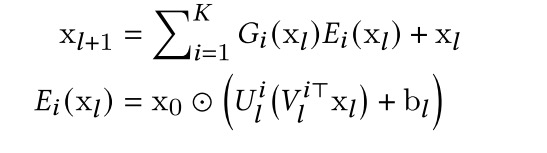

















 2301
2301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









