







内容框架
- Lakehouse 概念与特性
- Lakehouse 架构与实现
- 云上 Lakehouse 架构与实践
- 案例分享及未来展望
Lakehouse 概念与特性
数据架构的演进
1980年后期,以 Teradata、Oracle 等产品为代表的数据仓库,主要用于解决 BI 分析和报表的数据采集与计算需求。通过内置存储系统,对上层提供数据抽象,数据经过清洗和转化,以已定义的schema结构写入,强调建模和数据管理以提供更好的性能和数据一致性,具备细粒度的数据管理和治理能力;支持事务、版本管理;数据深度优化,和计算引擎深度集成,提升了对外的 SQL 查询性能。然而,随着数据量的增长,数据仓库开始面临若干挑战。首先是存储和计算耦合,需要根据两者峰值采购,导致采购成本高、采购周期长;其次越来越多的数据集是非结构化的,数据仓库无法存储和查询这些数据;此外,数据不够开放,导致不易用于其他高级分析(如 ML )场景。
随着 Hadoop 生态的兴起,以 HDFS、S3、OSS 等产品为代表,统一存储所有数据,支持各种数据应用场景,架构较为复杂的数据湖开始流行。以基于 HDFS 存储、或者基于云上的对象存储这种相对低成本、高可用的统一存储系统,替换了原先的底层存储。可以存储各种原始数据,无需提前进行建模和数据转化,存储成本低且拓展性强;支持半结构化和非结构化的数据;数据更加开放,可以通过各种计算引擎或者分析手段读取数据,支持丰富的计算场景,灵活性强且易于启动。不过随着十年来的发展,数据湖的问题也逐渐暴露。数据链路长/组件多导致出错率高、数据可靠性差;各个系统间不断的数据迁移同步给数据一致性和时效性带来挑战;湖里的数据杂乱无章,未经优化直接访问查询会出现性能问题;整体系统的复杂性导致企业建设和维护成本高等。
为了解决上述问题,结合数据湖和数据仓库优势的 LakeHouse 应运而生。底层依旧是低成本、开放的存储,上层基于类似 Delta lake/Iceberg/Hudi 建设数据系统,提供数据管理特性和高效访问性能,支持多样数据分析和计算,综合了数据仓库以及数据湖的优点形成了新的架构。存算分离架构可以进行灵活扩展;减少数据搬迁,数据可靠性、一致性和实时性得到了保障;支持丰富的计算引擎和范式;此外,支持数据组织和索引优化,查询性能更优。不过,因为 LakeHouse 还处于快速发展期,关键技术迭代快且成熟的产品和系统少。在可借鉴案例不多的情况下,企业如果想采用 LakeHouse,需要有一定技术投入。
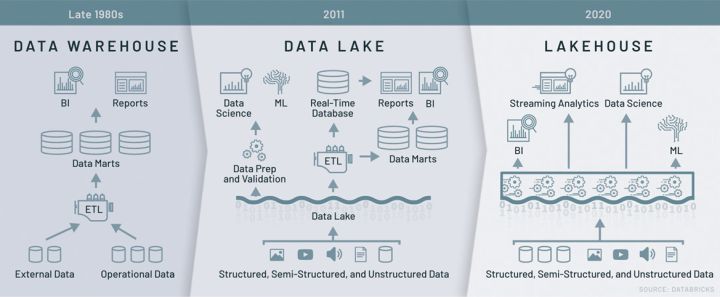
数据架构的对比

上图从多维度对数据仓库、数据湖、LakeHouse 进行了对比,可以明显看到 LakeHouse 综合了数据仓库和数据湖的优势,这也是 LakeHouse 被期待为“新一代数据架构基本范式”的原因。
Lakehouse 架构与实现
Lakehouse 架构图
Lakehouse = 云上对象存储 + 湖格式 + 湖管理平台
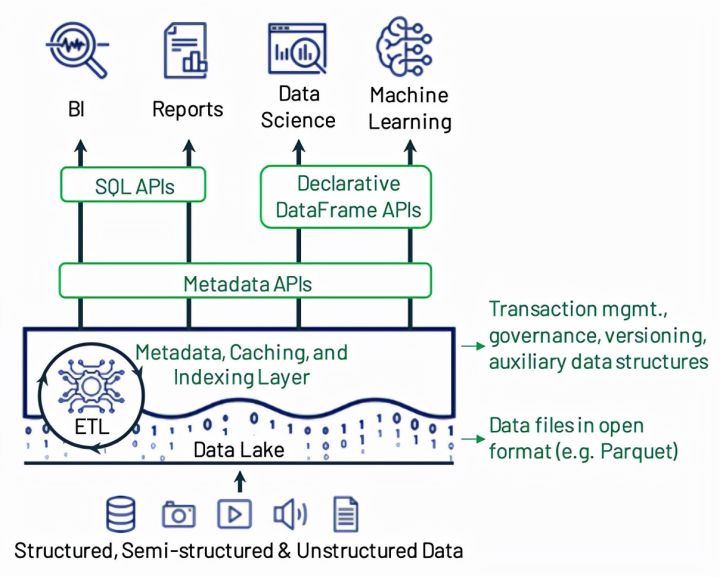
访问层
- 元数据层查询和定位数据
- 对象存储支持高吞吐的数据访问
- 开放的数据格式支持引擎直接读取
- Declarative DataFrame API 利用SQL引擎的优化和过滤能力
优化层
- Caching、Auxiliary data structures(indexing and statistics)、data layout optimization,Governance
事务层
- 实现支持事务隔离的元数据层,指明每个Table版本所包含的数据对象
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4176
4176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









