









【卷积加速】深度学习卷积算法的GPU加速实现方法_cbd_2012的博客-CSDN博客
(Caffe)卷积的实现_沤江一流的专栏-CSDN博客_caffe卷积实现CC
Caffe是将feature map和kernel都展开成矩阵,使用矩阵成法来做的(利用了cuBLAS矩阵乘法加速)

其他方案:
1. 每个GPU thread负责计算一个output feature map pixel;缺点:访问显存太频繁,是瓶颈;
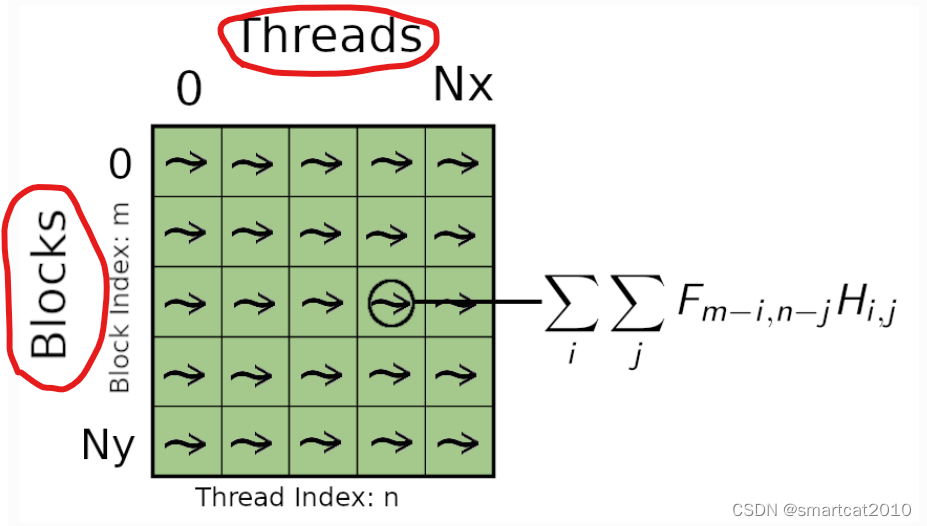
2. 每个GPU Block负责一组output pixel的计算;(可以把所有卷积核都加载进Block的shared memory;计算这组output所需要输入的input pixels也加载进shared memory;然后Block里的每个thread负责计算一个output pixel); 原文















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









