







XGBoost
- XGBoost(以下仅为个人笔记,如有错误还请指出)
- 1.算法步骤
- 2.参数选择
- 3.MATLAB 实现
- 参考资料
XGBoost(以下仅为个人笔记,如有错误还请指出)
XGBoost(eXtreme Gradient Boosting)实现了机器学习中的梯度提升决策树算法(Gradient Boosting Decision Trees, GBDT),并以其出色的性能和效率在数据科学界获得了广泛的认可。XGBoost是一个强大而高效的机器学习工具,特别适合需要高准确率和处理大规模数据集的任务。无论是学术研究还是工业应用,XGBoost都是一个值得考虑的选择。以下是关于XGBoost的一些关键点:
- 算法基础:XGBoost 基于梯度提升框架,通过迭代地添加决策树来构建模型。每棵新树都试图纠正之前所有树的预测错误,从而逐步改进模型;
- 优化与扩展:
- XGBoost引入了正则化项以控制模型复杂性,减少过拟合的风险;
- 支持自定义损失函数,只要损失函数是可微的;
- 采用二阶导数信息(Hessian 矩阵)来更精确地找到最佳分裂点;
- 包含处理缺失值的功能,自动学习缺失值的最佳方向;
- 实现了并行与分布式计算,支持大规模数据集的训练。
- 应用场景:XGBoost因其强大的表现力和灵活性,被广泛应用于分类、回归和排序等问题中。它在众多数据科学竞赛中表现出色;
- 易用性:XGBoost提供了对多种编程语言的支持,包括Python、MATLAB、R、Java、Scala等,并且可以轻松集成到现有的数据流水线中。它还提供了一个直观的接口,使得用户能够快速上手并进行实验。
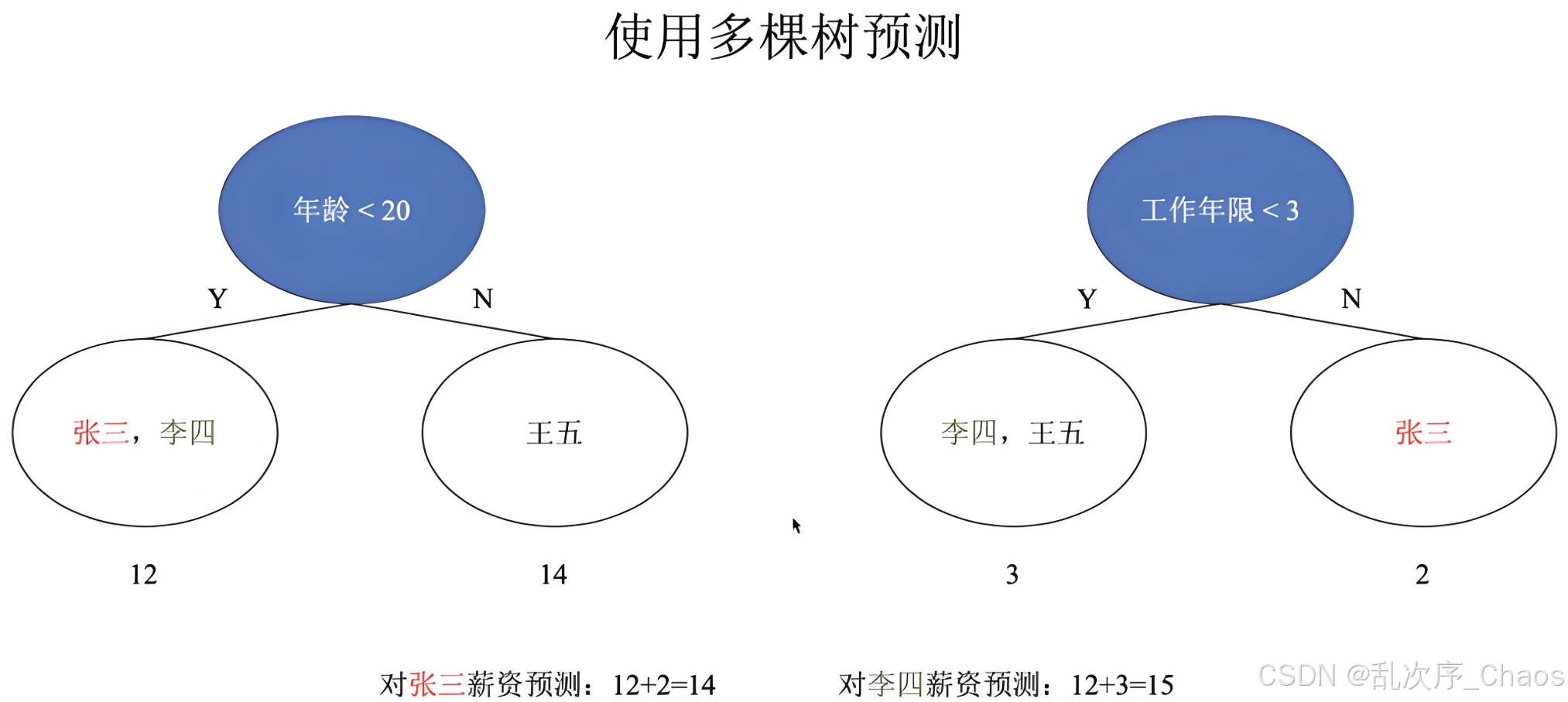
1.算法步骤
-
初始化预测值
- 目标:设定初始预测值(通常为常数,如样本标签的均值);
- 公式:
F
0
(
x
)
=
arg
min
γ
∑
i
=
1
n
L
(
y
i
,
γ
)
F_0(x) = \arg \min_{\gamma} \sum_{i=1}^{n} L(y_i, \gamma)
F0(x)=argγmini=1∑nL(yi,γ)
- F 0 ( x ) F_0(x) F0(x):这是模型的初始预测值。对于所有的样本点,它是一个常数值,因为这是在考虑任何特征或进行任何提升迭代之前的初步猜测;
- arg min γ \arg \min_{\gamma} argminγ:这个操作是在寻找一个能最小化后面损失函数的参数 γ γ γ 的值。换句话说,它是要找到那个使得损失函数达到最小值的 γ γ γ ;
- ∑ i = 1 n L ( y i , γ ) \sum_{i=1}^{n} L(y_i, \gamma) ∑i=1nL(yi,γ):这部分表示对所有训练样本(从 i = 1 i=1 i=1 到 i = n i=n i=n )计算的损失函数 L ( y i , γ ) L(y_i,γ) L(yi,γ) 的总和。这里的 y i y_i yi 是第 i i i 个样本的真实标签,而 γ γ γ 是我们试图优化的参数,即初始预测值;
- L ( y i , γ ) L(y_i,γ) L(yi,γ):损失函数衡量了真实值 y i y_i yi 和预测值 γ γ γ 之间的差异。不同的问题可能使用不同的损失函数,比如回归问题中常用的平方误差损失或者分类问题中的对数损失等,例如,对于平方损失函数,初始预测值为所有样本标签的均值: F 0 ( x ) = 1 n ∑ i = 1 n y i F_0(x) = \frac{1}{n} \sum_{i=1}^{n} y_i F0(x)=n1∑i=1nyi。
-
迭代构建树(Boosting)
- 核心思想:通过加法模型(Additive Model)逐步添加决策树,修正前一轮的残差;
- 第 t 轮迭代步骤:
- 2.1 计算梯度:对每个样本计算损失函数的一阶梯度(
g
i
g_i
gi )和二阶梯度(
h
i
h_i
hi ):
g
i
=
∂
L
(
y
i
,
F
t
−
1
(
x
i
)
)
∂
F
t
−
1
(
x
i
)
,
h
i
=
∂
2
L
(
y
i
,
F
t
−
1
(
x
i
)
)
∂
F
t
−
1
(
x
i
)
2
g_i = \frac{\partial L(y_i, F_{t-1}(x_i))}{\partial F_{t-1}(x_i)}, \quad h_i = \frac{\partial^2 L(y_i, F_{t-1}(x_i))}{\partial F_{t-1}(x_i)^2}
gi=∂Ft−1(xi)∂L(yi,Ft−1(xi)),hi=∂Ft−1(xi)2∂2L(yi,Ft−1(xi))
- g i g_i gi:这是损失函数对当前预测值 F t − 1 ( x i ) F_{t−1}(x_i) Ft−1(xi) 的一阶导数,也被称为梯度。在给定第 i i i 个样本的真实标签 y i y_i yi 和前一棵树(或之前所有树)的预测结果 F t − 1 ( x i ) F_{t−1}(x_i) Ft−1(xi) 的情况下,它衡量了损失函数随预测值变化的变化率。一阶导数帮助我们了解如何调整预测以减少误差;
- h i h_i hi:这是损失函数对当前预测值 F t − 1 ( x i ) F_{t−1}(x_i) Ft−1(xi) 的二阶导数,可以视为曲率的一种度量。二阶导数提供了关于损失函数形状的信息,特别是它的弯曲程度,这有助于确定下一步应该移动多远才能更接近最小值,在XGBoost中,使用二阶导数来更好地近似损失函数,并进行更加精确的更新。
- 2.2 生成候选分裂点:
- 对每个特征按分位数(如三分位数)划分候选分裂点;
- 优化:XGBoost 采用加权分位数法,减少候选点数量,提升效率。
- 2.3 选择最佳分裂点:
- 计算每个分裂点的 增益(Gain),选择增益最大的分裂点:
Gain
=
1
2
[
(
∑
i
∈
L
g
i
)
2
∑
i
∈
L
h
i
+
λ
+
(
∑
i
∈
R
g
i
)
2
∑
i
∈
R
h
i
+
λ
−
(
∑
i
g
i
)
2
∑
i
h
i
+
λ
]
−
γ
\text{Gain} = \frac{1}{2} \left[ \frac{\left( \sum_{i \in L} g_i \right)^2}{\sum_{i \in L} h_i + \lambda} + \frac{\left( \sum_{i \in R} g_i \right)^2}{\sum_{i \in R} h_i + \lambda} - \frac{\left( \sum_i g_i \right)^2}{\sum_i h_i + \lambda} \right] - \gamma
Gain=21[∑i∈Lhi+λ(∑i∈Lgi)2+∑i∈Rhi+λ(∑i∈Rgi)2−∑ihi+λ(∑igi)2]−γ
- Gain \text{Gain} Gain:代表了如果按照当前考虑的特征和阈值分裂节点,模型损失函数的减少量。增益越高,说明这个分裂越有价值;
- L L L 和 R R R 分别代表分裂后生成的左子树和右子树中的样本集合。对于每个子集,我们计算其梯度 g i g_i gi 和二阶梯度 h i h_i hi 的总和;
- ∑ i ∈ L g i \sum_{i \in L} g_i ∑i∈Lgi 和 ∑ i ∈ R g i \sum_{i \in R} g_i ∑i∈Rgi:分别是左子树和右子树中所有样本的一阶导数之和,反映了两个子树各自预测误差的方向和大小;
- ∑ i ∈ L h i \sum_{i \in L} h_i ∑i∈Lhi 和 ∑ i ∈ R h i \sum_{i \in R} h_i ∑i∈Rhi:分别是左子树和右子树中所有样本的二阶导数之和,用于衡量这两个子集中样本的预测误差的变化率或曲率;
- ( ∑ i ∈ L g i ) 2 ∑ i ∈ L h i + λ \frac{\left( \sum_{i \in L} g_i \right)^2}{\sum_{i \in L} h_i + \lambda} ∑i∈Lhi+λ(∑i∈Lgi)2 和 ( ∑ i ∈ R g i ) 2 ∑ i ∈ R h i + λ \frac{\left( \sum_{i \in R} g_i \right)^2}{\sum_{i \in R} h_i + \lambda} ∑i∈Rhi+λ(∑i∈Rgi)2:这两个项分别计算了分裂后左右子树的损失减少量。这里分母加上了一个正则化参数 λ λ λ,目的是为了防止过拟合,增加分裂的质量要求,避免因为数据的小波动而做出不必要的分裂;
- ( ∑ i g i ) 2 ∑ i h i + λ \frac{\left( \sum_i g_i \right)^2}{\sum_i h_i + \lambda} ∑ihi+λ(∑igi)2 :这是分裂前整个节点的损失情况,作为对比基准;
- 括号前的 1 2 \frac{1}{2} 21 是一个缩放因子,不影响分裂的选择,仅用于简化后续的计算;
- 最后减去的 γ γ γ 是叶子节点的复杂度代价,也是一个正则化项,用来惩罚过于复杂的模型(即过多的叶子节点)。这有助于控制模型的复杂性,避免过拟合并提高泛化能力。
- 计算每个分裂点的 增益(Gain),选择增益最大的分裂点:
Gain
=
1
2
[
(
∑
i
∈
L
g
i
)
2
∑
i
∈
L
h
i
+
λ
+
(
∑
i
∈
R
g
i
)
2
∑
i
∈
R
h
i
+
λ
−
(
∑
i
g
i
)
2
∑
i
h
i
+
λ
]
−
γ
\text{Gain} = \frac{1}{2} \left[ \frac{\left( \sum_{i \in L} g_i \right)^2}{\sum_{i \in L} h_i + \lambda} + \frac{\left( \sum_{i \in R} g_i \right)^2}{\sum_{i \in R} h_i + \lambda} - \frac{\left( \sum_i g_i \right)^2}{\sum_i h_i + \lambda} \right] - \gamma
Gain=21[∑i∈Lhi+λ(∑i∈Lgi)2+∑i∈Rhi+λ(∑i∈Rgi)2−∑ihi+λ(∑igi)2]−γ
- 2.4 生成子树:
- 根据分裂点递归生成树结构,直至达到最大深度或无法继续分裂;
- 叶子节点权重计算:
w
j
=
−
∑
i
∈
I
j
g
i
∑
i
∈
I
j
h
i
+
λ
w_j = -\frac{\sum_{i \in I_j} g_i}{\sum_{i \in I_j} h_i + \lambda}
wj=−∑i∈Ijhi+λ∑i∈Ijgi
- I j I_j Ij:属于叶子节点 j j j 的样本集合。
- w j w_j wj:这是第 j j j 个叶子节点上的预测值(权重)。对于回归问题,它可以被看作是该叶子节点对最终预测结果的贡献;对于分类问题,它代表了该叶子节点上样本属于某一类别的得分;
- ∑ i ∈ I j g i \sum_{i \in I_j} g_i ∑i∈Ijgi:表示分配到第 j j j 个叶子节点的所有样本的一阶梯度之和。一阶梯度衡量了损失函数相对于当前预测的变化率,反映了模型在这些样本点上的误差方向和大小;
- ∑ i ∈ I j h i \sum_{i \in I_j} h_i ∑i∈Ijhi:表示分配到第 j j j 个叶子节点的所有样本的二阶梯度之和。二阶导数提供了关于损失函数形状的信息,特别是其曲率,这有助于确定调整预测值的方向和步长;
- λ λ λ :这是一个正则化参数,用于控制模型的复杂度,防止过拟合。通过在分母中添加 λ λ λ,可以避免模型过于依赖训练数据中的噪声或异常值,从而提高模型的泛化能力。
- 2.1 计算梯度:对每个样本计算损失函数的一阶梯度(
g
i
g_i
gi )和二阶梯度(
h
i
h_i
hi ):
g
i
=
∂
L
(
y
i
,
F
t
−
1
(
x
i
)
)
∂
F
t
−
1
(
x
i
)
,
h
i
=
∂
2
L
(
y
i
,
F
t
−
1
(
x
i
)
)
∂
F
t
−
1
(
x
i
)
2
g_i = \frac{\partial L(y_i, F_{t-1}(x_i))}{\partial F_{t-1}(x_i)}, \quad h_i = \frac{\partial^2 L(y_i, F_{t-1}(x_i))}{\partial F_{t-1}(x_i)^2}
gi=∂Ft−1(xi)∂L(yi,Ft−1(xi)),hi=∂Ft−1(xi)2∂2L(yi,Ft−1(xi))
-
正则化
- 目标:防止过拟合,提升泛化能力;
- 策略:
- 权重收缩(Shrinkage):每棵树的贡献乘学习率
η
η
η(如 0.1 ):
F
t
(
x
)
=
F
t
−
1
(
x
)
+
η
⋅
f
t
(
x
)
F_t(x) = F_{t-1}(x) + \eta \cdot f_t(x)
Ft(x)=Ft−1(x)+η⋅ft(x)
- F t ( x ) F_t(x) Ft(x):这是在第 t t t 轮迭代后的模型输出。随着每次迭代,模型会逐步学习到数据中的模式,并试图减少预测误差;
- F t − 1 ( x ) F_{t-1}(x) Ft−1(x):这是前一轮迭代结束时的模型输出。也就是说,这是在没有加上本轮新学到的信息之前的模型状态;
- η η η :这是学习率(也称为收缩率或步长),通常是一个介于 0 和 1 之间的数。学习率控制了每棵树对最终结果的影响程度。较小的学习率意味着需要更多的树来拟合训练数据,但通常可以带来更好的泛化能力和更平滑的决策边界;
- f t ( x ) f_t(x) ft(x) :这是在第 t t t 轮迭代中训练出的新树的预测结果。每一次迭代都致力于纠正之前所有树的预测错误,通过聚焦于那些先前模型预测不准确的数据点,从而逐步改进模型的整体性能。
- 列采样(Column Subsampling):随机选择部分特征进行分裂;
- 剪枝(Pruning):根据增益阈值 γ γ γ 剪除低增益的分支。
- 权重收缩(Shrinkage):每棵树的贡献乘学习率
η
η
η(如 0.1 ):
F
t
(
x
)
=
F
t
−
1
(
x
)
+
η
⋅
f
t
(
x
)
F_t(x) = F_{t-1}(x) + \eta \cdot f_t(x)
Ft(x)=Ft−1(x)+η⋅ft(x)
-
更新预测值
- 将新生成的树 f t ( x ) f_t(x) ft(x) 加入模型: F t ( x ) = F t − 1 ( x ) + η ⋅ f t ( x ) F_t(x) = F_{t-1}(x) + \eta \cdot f_t(x) Ft(x)=Ft−1(x)+η⋅ft(x)
-
停止条件
- 预设轮次:达到最大迭代次数(如 100 轮);
- 早停(Early Stopping):验证集误差连续 k k k 轮不再下降;
- 性能阈值:损失函数降至目标值以下。
2.参数选择
| 参数类型 | 核心参数 | 调优优先级 | 作用方向 |
|---|---|---|---|
| 基础控制 | η (学习率) | 中 | 控制模型收敛速度与稳定性 |
| 复杂度控制 | max_depth(树复杂度参数) | 高 | 防止过拟合/欠拟合 |
min_child_weight(最小样本权重和) | 高 | 控制叶子节点最小样本权重 | |
| 正则化 | λ (L2 正则化) | 中 | 约束权重,抑制过拟合 |
γ (分裂增益阈值) | 中 | 剪枝,简化模型结构 | |
| 随机化 | subsample (行采样) | 低 | 增强多样性,防过拟合 |
colsample_bytree (列采样) | 低 | 类似随机森林的特征抽样 |
-
学习率 η
- 作用:控制每棵树的权重,值越小模型越保守,需更多树;
- 经验范围:
0.01 ~ 0.3 - 调优策略:
- 高学习率(0.1~0.3):快速收敛,适合数据量小或树数少(
n_estimators=50~100); - 低学习率(0.01~0.1):需更多树(
n_estimators=200~1000),配合早停法(early_stopping_rounds=10)。
- 高学习率(0.1~0.3):快速收敛,适合数据量小或树数少(
- 案例:
若η=0.3时测试集MSE=5.2,η=0.1时MSE=4.8,但需 3 倍树数量,需权衡时间与性能。
-
树复杂度参数
max_depth(树最大深度):- 作用:控制树的生长,值越大模型越复杂。
- 经验范围:
3~10- 分类任务:3-6
- 回归任务:5-10
- 调优:从
3开始逐步增加,观察验证集性能。
min_child_weight(最小样本权重和):- 作用:基于二阶导数(Hessian)的样本权重和,限制叶子节点样本量。
- 经验范围:
1~20- 小数据集:1-5
- 大数据集:10-20
- 公式:
∑
i
∈
node
h
i
≥
min_child_weight
\sum_{i \in \text{node}} h_i \geq \text{min\_child\_weight}
i∈node∑hi≥min_child_weight
- h i h_i hi 是样本 ii 的二阶导数(Hessian),与损失函数相关;
- 左式表示当前节点的所有样本的 Hessian 之和;
- 分裂条件:只有当分裂后的 左子节点和右子节点 的 Hessian 之和均满足此阈值时,才允许分裂。
-
正则化参数
λ(L2正则化系数):- 作用:惩罚叶子权重的平方,值越大模型越简单。
- 经验范围:
0.1~10 - 调优:若模型过拟合(
训
练
误
差
<
<
测
试
误
差
训练误差 << 测试误差
训练误差<<测试误差),增大
λ。
γ(最小分裂增益阈值):- 作用:分裂增益需超过该值才允许分裂,越大模型越简单。
- 经验范围:
0~5 - 公式: Gain ≥ γ 才 分 裂 \text{Gain}≥γ 才分裂 Gain≥γ才分裂
-
随机化参数
subsample(行采样比例):- 作用:每棵树训练时采样样本的比例,增强多样性。
- 经验范围:
0.5~1.0 - 调优:数据量大时用
0.8~1.0,小数据用0.5~0.8。
colsample_bytree(列采样比例):- 作用:每棵树训练时采样特征的比例。
- 经验范围:
0.5~1.0 - 调优:特征数多时用
0.5~0.8,特征少时用0.8~1.0。
3.MATLAB 实现

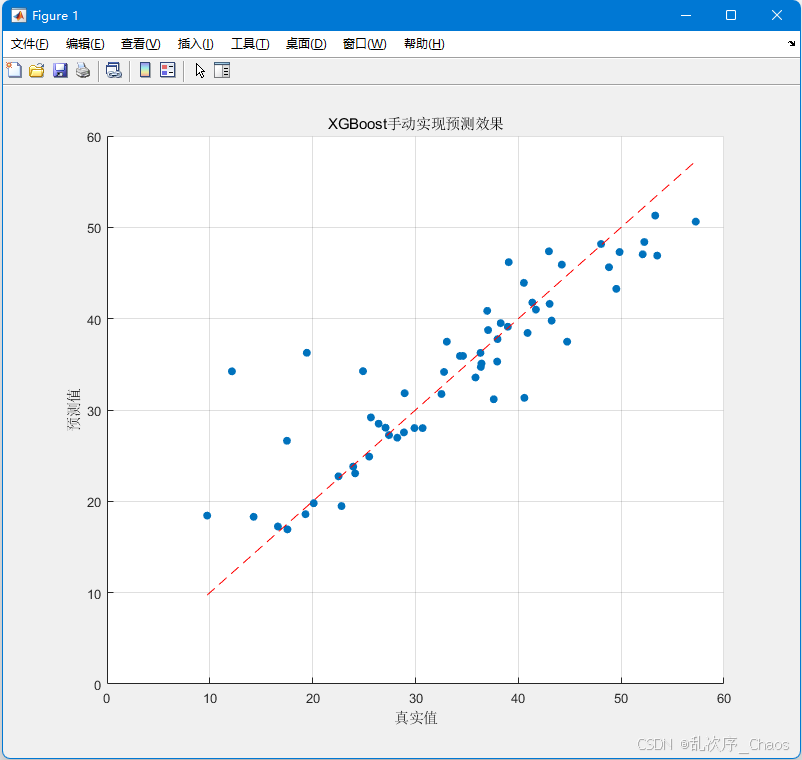
%% XGBoost matlab实现
clc; clear; close all;
%% XGBoost核心参数设置
params = struct(...
'eta', 0.05, ... % 学习率 (同learning_rate), 控制每棵树的贡献
'gamma', 0, ... % 最小分裂增益阈值,防止过拟合
'lambda', 1, ... % L2正则化系数,约束叶子权重
'max_depth', 3, ... % 树最大深度,控制模型复杂度
'subsample', 1, ... % 行采样比例,增强多样性
'colsample_bytree', 1, ... % 列采样比例,类似随机森林
'min_child_weight', 1 ... % 叶子节点最小样本权重和(基于Hessian)
);
%% 生成模拟数据(含10%缺失值)
rng(42); % 固定随机种子
n_samples = 200; % 样本数量
n_features = 5; % 特征维度
X = rand(n_samples, n_features) * 10; % 特征矩阵范围[0,10]
Y = 3*X(:,1) + 2*X(:,2) + 1.5*X(:,3) + randn(n_samples,1)*2; % 目标变量(线性关系+噪声)
% 添加10%缺失值(NaN表示缺失)
X(randperm(numel(X), round(0.1*numel(X)))) = NaN;
% 划分训练集和测试集
cv = cvpartition(n_samples, 'HoldOut', 0.3);
X_train = X(cv.training,:);
Y_train = Y(cv.training,:);
X_test = X(cv.test,:);
Y_test = Y(cv.test,:);
%% 初始化预测值(基学习器为均值)
base_score = mean(Y_train); % 初始预测值
F = base_score * ones(size(Y_train)); % 训练集预测值初始化
F_test = base_score * ones(size(Y_test)); % 测试集预测值初始化
%% XGBoost训练主循环
n_estimators = 70; % 树的数量
trees = cell(n_estimators, 1); % 存储所有树结构
for t = 1:n_estimators
% 步骤1: 数据采样(行采样 + 列采样)
[sub_X, sub_Y, sub_idx, col_idx] = subsample(X_train, Y_train, ...
params.subsample, params.colsample_bytree);
% 步骤2: 计算一阶梯度(g)和二阶导数(h) —— 均方误差损失
g = -(sub_Y - F(sub_idx)); % 一阶导数:负残差
h = ones(size(g)); % 二阶导数:平方损失下恒为1
% 步骤3: 训练XGBoost树(处理缺失值)
tree = xgb_train_tree(sub_X, g, h, params, 0, 1:size(col_idx,2));
% 步骤4: 更新训练集预测值(带学习率)
leaf_pred = xgb_predict_tree(tree, X_train(:, col_idx)); % 仅使用采样特征
F = F + params.eta * leaf_pred;
% 存储树结构和使用的特征索引
trees{t} = struct('tree', tree, 'col_idx', col_idx);
% 打印训练进度
fprintf('Tree %d 训练完成 | 最佳增益: %.2f\n', t, tree.best_gain);
end
%% 测试集预测
for t = 1:n_estimators
% 获取当前树的特征子集
col_idx = trees{t}.col_idx;
% 预测并累加结果
leaf_pred = xgb_predict_tree(trees{t}.tree, X_test(:, col_idx));
F_test = F_test + params.eta * leaf_pred;
end
% 计算评估指标
mse = mean((Y_test - F_test).^2);
fprintf('\n测试集MSE: %.2f\n', mse);
plot(1:size(Y_test,1),Y_test,1:size(F_test,1),F_test)
%% ========== 核心函数定义 ==========
function tree = xgb_train_tree(X, g, h, params, depth, col_idx)
% XGBoost树训练函数(递归实现)
% 输入:
% X - 特征矩阵(可能含NaN)
% g - 一阶梯度
% h - 二阶导数
% params - 超参数
% depth - 当前深度
% col_idx - 全局特征索引(用于预测时对齐)
% 输出:
% tree - 树结构体
% 终止条件1: 达到最大深度
% 终止条件2: 节点样本权重和不足(min_child_weight)
if depth >= params.max_depth || sum(h) < params.min_child_weight
% 计算叶子节点权重(带L2正则化)
w = -sum(g) / (sum(h) + params.lambda);
tree = struct('is_leaf', true, 'value', w, 'best_gain', 0, 'col_idx', col_idx);
return;
end
% 初始化最佳分裂参数
best_gain = -inf;
best_feature = 0;
best_threshold = 0;
best_default = 0; % 缺失值默认方向(0=左子树,1=右子树)
% 遍历所有采样特征(此处使用全局特征索引)
for f_global = col_idx
% 获取当前特征数据(可能含NaN)
feature_data = X(:, f_global);
% 步骤1: 处理缺失值,获取有效数据点
valid_mask = ~isnan(feature_data);
sorted_data = sort(feature_data(valid_mask));
% 步骤2: 生成候选分裂点(简化版分位数)
n_bins = min(10, length(sorted_data)); % 分箱数量
candidates = linspace(min(sorted_data), max(sorted_data), n_bins+1);
candidates = candidates(2:end-1); % 去除首尾
% 步骤3: 评估每个候选点
for threshold = candidates
% 分裂掩码(处理缺失值为默认方向)
left_mask = feature_data <= threshold;
left_mask(isnan(feature_data)) = false; % 初始假设缺失值归右
% 计算增益(假设缺失值在右)
G_left = sum(g(left_mask));
H_left = sum(h(left_mask));
G_right = sum(g) - G_left;
H_right = sum(h) - H_left;
gain = (G_left^2)/(H_left + params.lambda) + ...
(G_right^2)/(H_right + params.lambda) - ...
(G_left + G_right)^2/(H_left + H_right + params.lambda);
gain = gain/2 - params.gamma; % XGBoost官方增益公式
% 检查是否更优增益(考虑缺失值在左的情况)
G_left_alt = sum(g(left_mask | isnan(feature_data)));
H_left_alt = sum(h(left_mask | isnan(feature_data)));
G_right_alt = sum(g) - G_left_alt;
H_right_alt = sum(h) - H_left_alt;
gain_alt = (G_left_alt^2)/(H_left_alt + params.lambda) + ...
(G_right_alt^2)/(H_right_alt + params.lambda) - ...
(G_left_alt + G_right_alt)^2/(H_left_alt + H_right_alt + params.lambda);
gain_alt = gain_alt/2 - params.gamma;
% 选择更优的缺失值分配方向
if gain_alt > gain
gain = gain_alt;
default_dir = true; % 缺失值归左
else
default_dir = false; % 缺失值归右
end
% 更新最佳分裂
if gain > best_gain
best_gain = gain;
best_feature = f_global;
best_threshold = threshold;
best_default = default_dir;
end
end
end
% ========== 修改后的终止条件判断 ==========
% 当所有特征都无法产生有效分裂时
if best_gain <= params.gamma || best_feature == 0
w = -sum(g)/(sum(h) + params.lambda);
tree = struct('is_leaf', true, 'value', w, 'best_gain', best_gain, 'col_idx', col_idx);
return;
end
% % 终止条件3: 无有效分裂(增益不足)
% if best_gain <= 0
% w = -sum(g)/(sum(h) + params.lambda);
% tree = struct('is_leaf', true, 'value', w, 'best_gain', best_gain, 'col_idx', col_idx);
% return;
% end
% 步骤4: 执行分裂
% 生成分裂掩码(处理缺失值)
feature_data = X(:, best_feature);
left_mask = feature_data <= best_threshold;
left_mask(isnan(feature_data)) = best_default; % 根据最佳方向分配缺失值
% 检查左右子节点是否为空
if sum(left_mask) == 0 || sum(~left_mask) == 0
w = -sum(g)/(sum(h) + params.lambda);
tree = struct('is_leaf', true, 'value', w, 'best_gain', best_gain, 'col_idx', col_idx);
return;
end
% ========== 带保护的递归调用 ==========
try
left_tree = xgb_train_tree(X(left_mask, :), g(left_mask), h(left_mask), ...
params, depth+1, col_idx);
right_tree = xgb_train_tree(X(~left_mask, :), g(~left_mask), h(~left_mask), ...
params, depth+1, col_idx);
catch ME
% 递归错误处理
warning('深度 %d 递归失败: %s', depth, ME.message);
w = -sum(g)/(sum(h) + params.lambda);
tree = struct('is_leaf', true, 'value', w, 'best_gain', best_gain, 'col_idx', col_idx);
return;
end
% % 递归构建子树
% left_tree = xgb_train_tree(X(left_mask, :), g(left_mask), h(left_mask), ...
% params, depth+1, col_idx);
% right_tree = xgb_train_tree(X(~left_mask, :), g(~left_mask), h(~left_mask), ...
% params, depth+1, col_idx);
% 返回非叶子节点结构
tree = struct(...
'is_leaf', false, ...
'feature', best_feature, ...
'threshold', best_threshold, ...
'default', best_default, ... % 缺失值方向
'left', left_tree, ...
'right', right_tree, ...
'best_gain', best_gain, ...
'col_idx', col_idx ...
);
end
function pred = xgb_predict_tree(tree, X)
% XGBoost树预测函数
% 输入:
% tree - 训练好的树结构
% X - 特征矩阵(必须包含tree.col_idx指定的特征)
% 输出:
% pred - 预测值
pred = zeros(size(X,1), 1);
for i = 1:size(X,1)
node = tree;
while true
if node.is_leaf
pred(i) = node.value;
break;
end
% 获取特征值(注意特征索引对齐)
f_global = node.feature;
val = X(i, f_global);
% 处理缺失值
if isnan(val)
go_left = node.default; % 使用训练时确定的方向
else
go_left = val <= node.threshold;
end
% 移动到子节点
if go_left
node = node.left;
else
node = node.right;
end
end
end
end
function [sub_X, sub_Y, sub_idx, col_idx] = subsample(X, Y, subsample_ratio, colsample_ratio)
% 数据采样函数(行+列采样)
% 输入:
% X, Y - 原始数据和标签
% subsample_ratio - 行采样比例
% colsample_ratio - 列采样比例
% 输出:
% sub_X, sub_Y - 采样后的数据和标签
% sub_idx - 行采样索引(相对于原始数据)
% col_idx - 列采样索引(全局特征索引)
% 行采样
n = size(X,1);
sub_idx = randperm(n, round(n * subsample_ratio));
sub_X = X(sub_idx, :);
sub_Y = Y(sub_idx);
% 列采样
n_features = size(X,2);
col_idx = sort(randperm(n_features, round(n_features * colsample_ratio)));
sub_X = sub_X(:, col_idx);
end
参考资料
[1] XGBoost详解_哔哩哔哩_bilibili
[2] 机器学习第二阶段:机器学习经典算法(4)——Xgboost_哔哩哔哩_bilibili
[3] 如何向5岁小孩解释模型:XGBoost_哔哩哔哩_bilibili


















 3896
3896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









