







根据进阶班作业贴:【CANN训练营2022年度第一季】【进阶班】【媒体数据处理精讲与实战】课程资源及作业发布专用帖_昇腾论坛_华为云论坛
大作业2题目如下:
开发媒体数据处理的应用,应用的输入为视频码流、输出为 JPEG 图片,且 JPEG 图片与视频的分辨率不同。
根据作业提示,转换的思路如下:
原始MP4视频=》H264/H265视频=>使用dvpp的vdec解码成yuv图片(多张)-》使用dvpp的进行resize缩放-》使用dvpp的jpege将yuv图片编码=》JPEG图片(多张)
下面看看如何实战:
一、准备MP4视频文件
先去搞个MP4过来。
张小白手头有一个:黑寡妇.2021.BD1080p.中英双字.mp4
打开格式工厂FormatFactory官网:
http://www.pcfreetime.com/formatfactory/CN/index.html
下载,安装:

耐心等待安装完毕:
点击下一步:

点击立即体验:
进入主页面:
点击->MP4
点击添加文件,选择刚才的MP4文件。
点击右上角的输出配置:
可以看到视频编码为 H264,这种格式按理说 dvpp是能解析的吧。。
由于影片长达2个多小时,只截取1分钟的片段,点击文件右边的“选项”按钮:

根据预览画面,选中 31:18到32:18之间的影像进行剪辑:
点击确定:
点击页面中的开始,进行转换:

很快就转换成功了。
打开MP4文件看看:
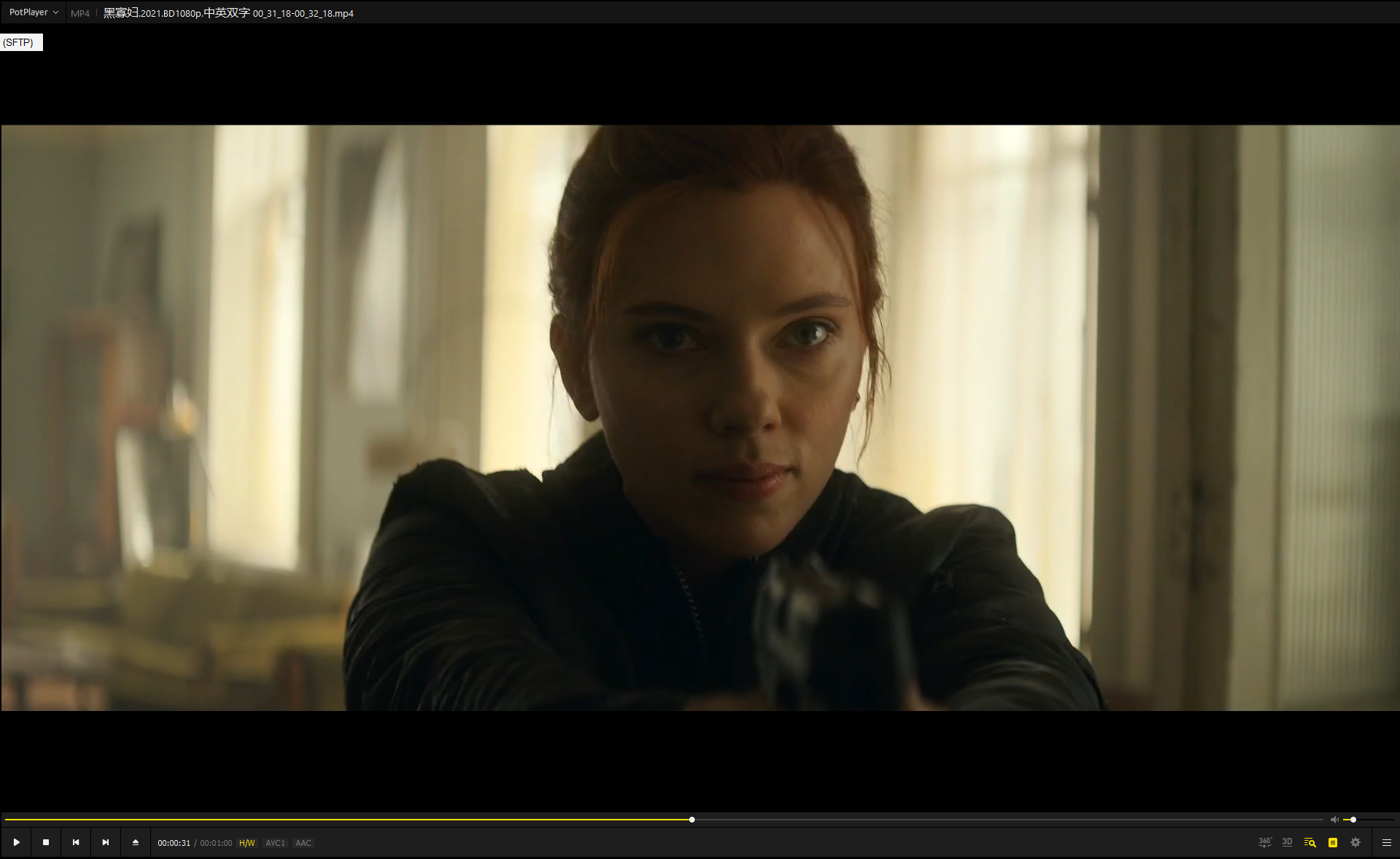
确实是1分钟时长。且可以播放。
那么H264格式的视频已经准备好了。我们可以试vdec,看看能不能解出成YUV吧。
二、视频解码VDEC的样例尝试
接着我们来看dvpp的vdec的文档:
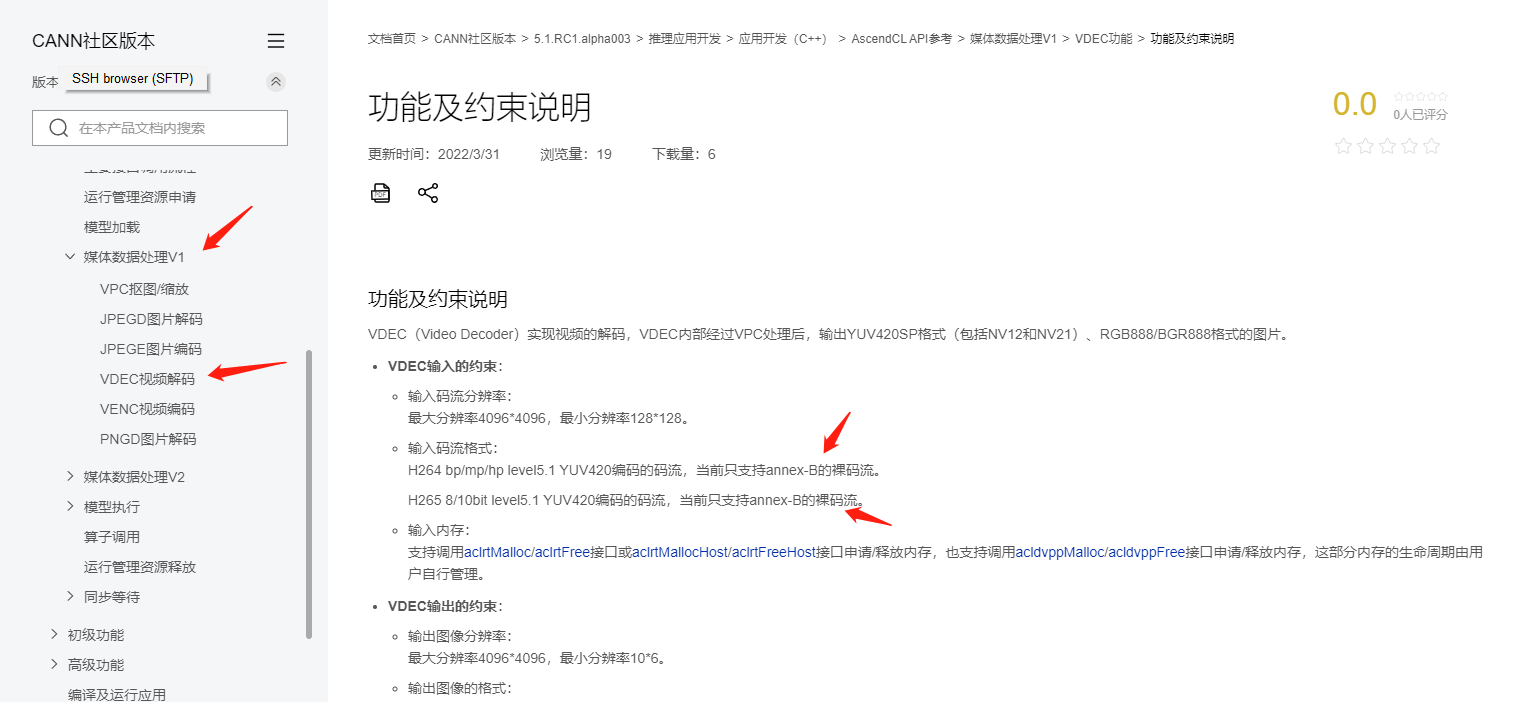
按理说刚才做好的1分钟视频是应该支持的。到底行不行呢?
再看看具体说明:昇腾社区-官网丨昇腾万里 让智能无所不及

这个图的流程示意很清楚了,下面也有具体的解释,就不一一说明了。大概的意思是:
循环处理输入视频流,调用aclvdecSendFrame进行视频解码,然后判断是否触发回调。一直到视频流结束为止。
查看对用的sample仓代码吧:samples: CANN Samples - Gitee.com
主代码在此:
cplusplus/level2_simple_inference/0_data_process/vdec/src/main.cpp · Ascend/samples - Gitee.com
我们编译试试:
cd /home/HwHiAiUser/samples/cplusplus/level2_simple_inference/0_data_process/vdec
cd scripts
bash ./sample_build.sh

记住,现在编译的样例代码。
运行样例代码试试:
bash ./sample_run.sh

去output目录看看:
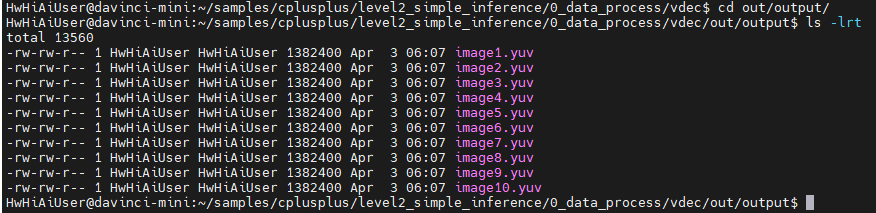
生成了10张yuv的文件。
我们可以把原来的H265文件下载下来,然后把这几个yuv文件做jpege编码,看看图片是啥样子.

切换到jpege目录:
cd /home/HwHiAiUser/samples/cplusplus/level2_simple_inference/0_data_process/jpege/data
cp ~/samples/cplusplus/level2_simple_inference/0_data_process/vdec/out/output/*.yuv .

修改 jpege的运行脚本:(先改一个yuv看看)

运行:
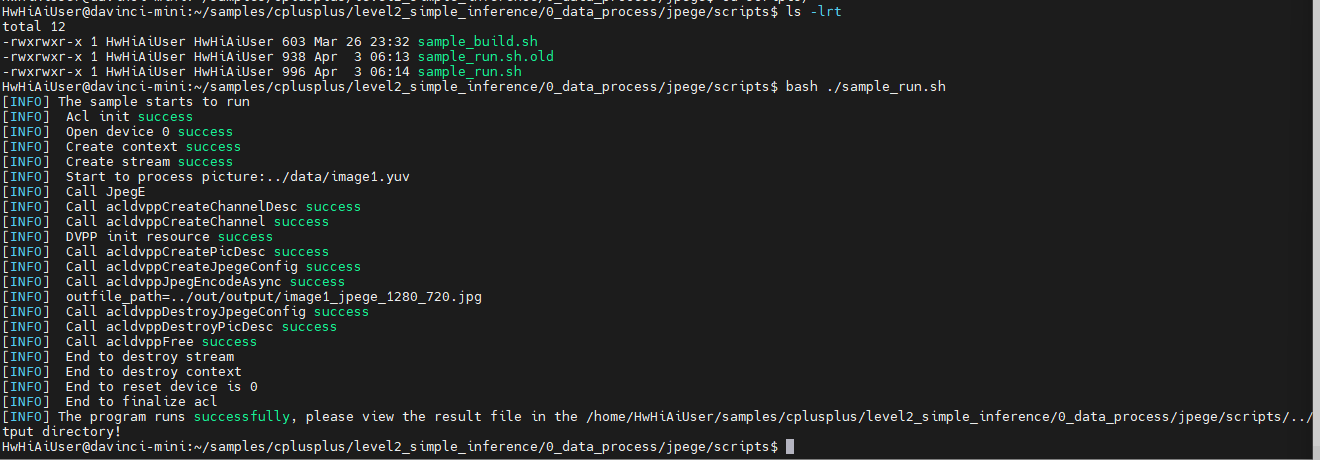
查看结果文件:

下载下来:
好像是个兔子:

唉,不知道原视频是不是兔子啊。。。
有没有什么办法知道呢?从文件名感知一下:vdec_h265_lframe_rabbit_1280X720.h265,好像跟兔子有关。
三、用VDEC解析自己准备的MP4视频的初步尝试
回到 vdec,把 黑寡妇的1分钟短视频传进去:
(我是不是应该把视频转成H265的再试试呢?)
黑寡妇.2021.BD1080p.中英双字 00_31_18-00_32_18.mp4
把名字改改吧:
00_31_18-00_32_18.mp4

去对应的main.cpp修改下文件名和分辨率:

去scripts下执行编译:
bash ./sample_build.sh
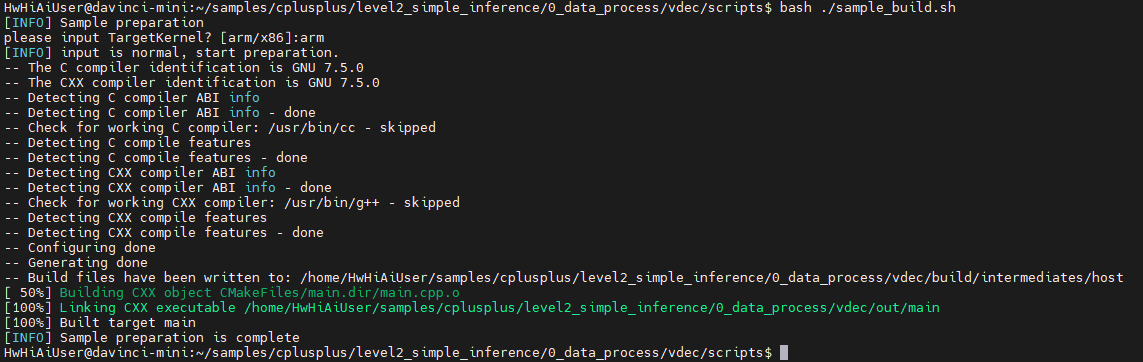
运行:
bash ./sample_run.sh

查看结果文件,这个文件只有10个(奇怪),但是文件比原来的大小大了。因为分辨率高了。
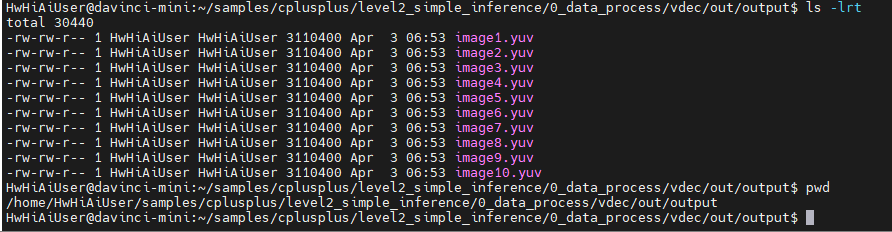
我们再把这个文件jpege编码后看看是什么图片吧!
cd /home/HwHiAiUser/samples/cplusplus/level2_simple_inference/0_data_process/jpege/data
cp /home/HwHiAiUser/samples/cplusplus/level2_simple_inference/0_data_process/vdec/out/output/*.yuv .
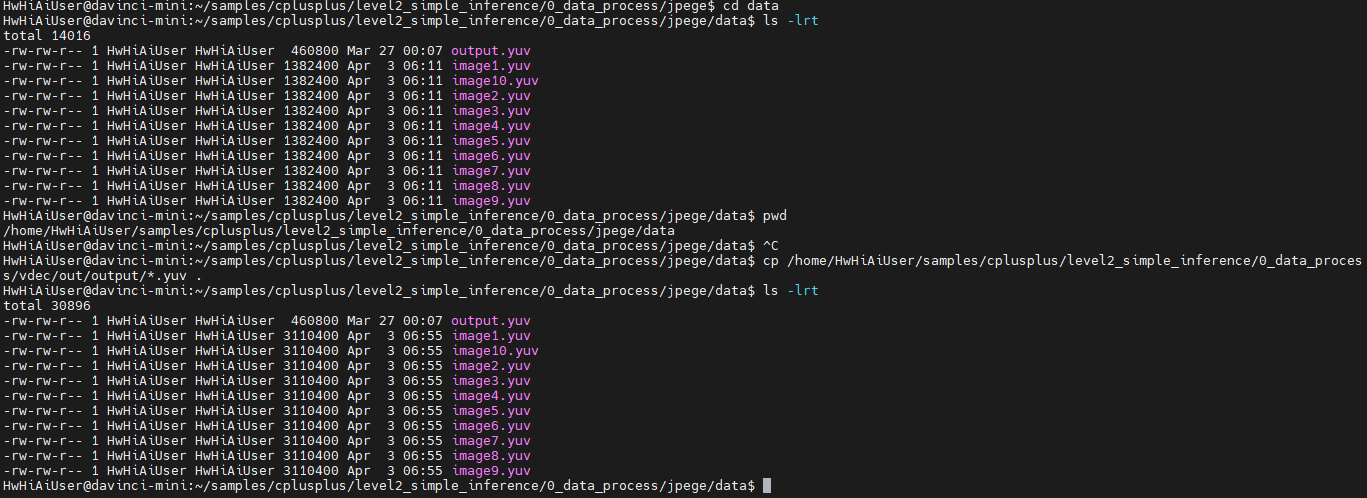
文件名不变,但是分辨率变了,修改下 sample_run.sh

执行:
bash sample_run.sh
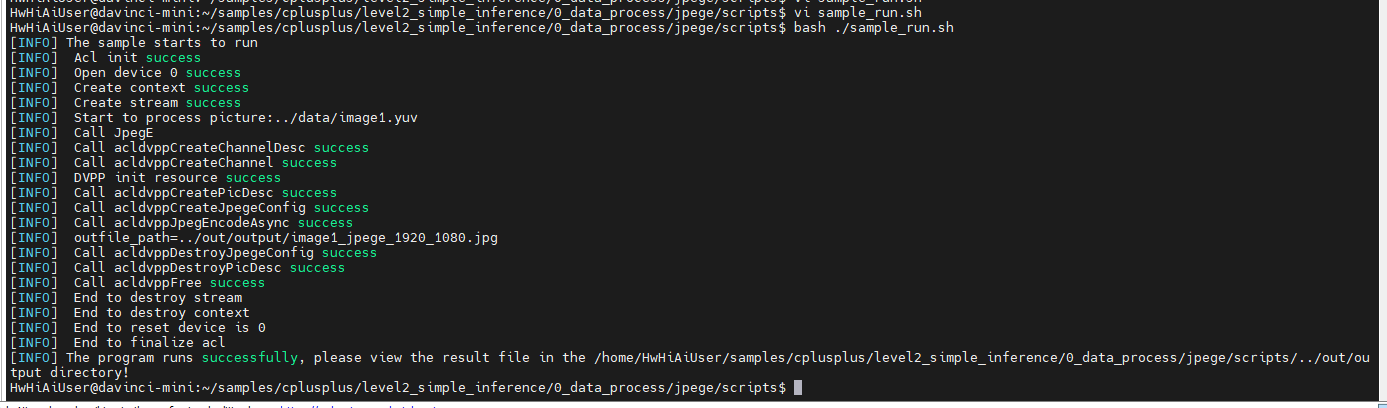
查看结果图片:

下载下来看看:
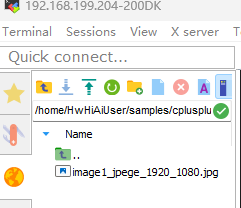
打开:

芭比Q了。。
四、重做一个H265的视频试试VDEC视频解码
张小白再用前面的方法,使用格式工厂将H264格式的MP4转换为H265视频的MP4:

源文件改名为H264.MP4
点击开始进行转换:

并将D:\FFOutput下的H264.MP4:

改名为H265.MP4,并使用MobaXterm上传到vdec的data目录下:

结果如下图所示:

这里面需要更新 vdec的main.cpp
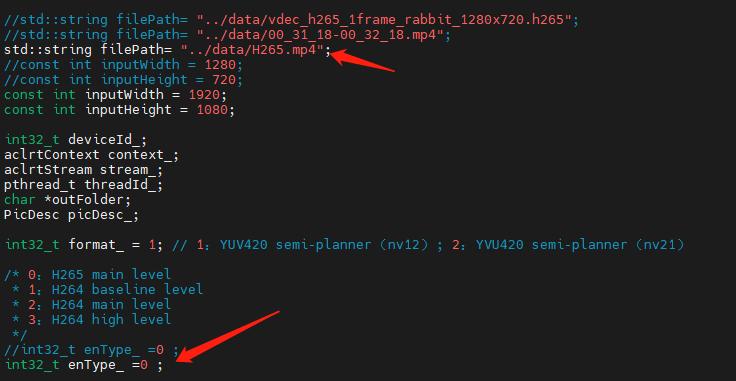
(前面对于H264的转换时,也需要修改enType)
对于H265,需要将enType设为0
同样进行编译,运行:
然后再切换到jpege目录下,将yuv文件拷贝到jpege的data目录下
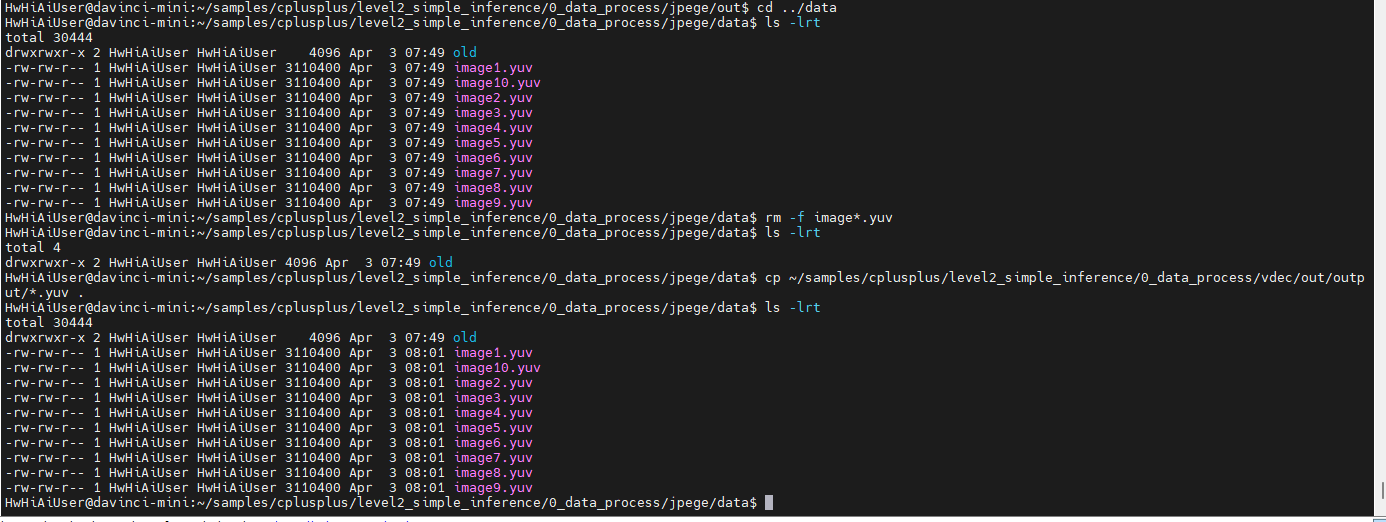
接着做jpege编码,将结果文件download下来一看,仍然跟前面的结果一样,啥也看不到。。。
五、失败的问题分析与H264视频流的VDEC-JPEGE
张小白有点蒙圈。只好在群里咨询。
这时候,西瓜哥给了一盏明灯:
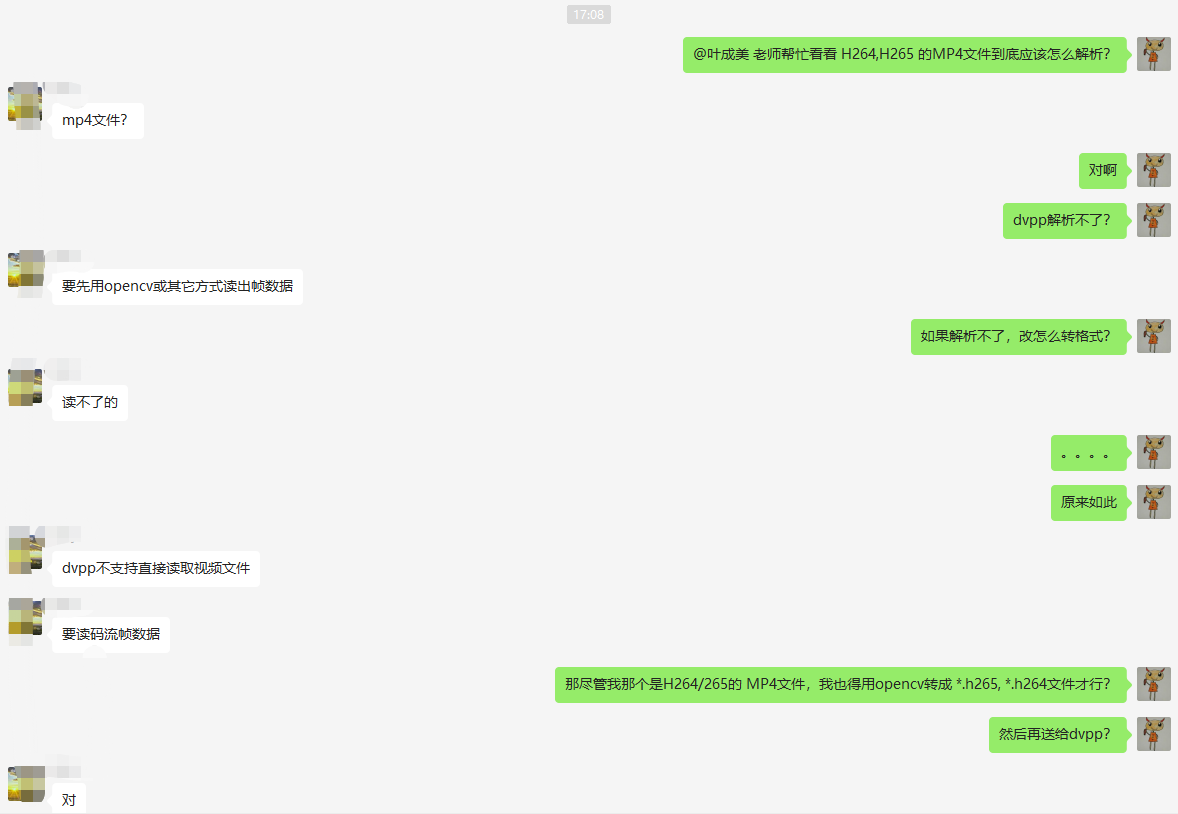
原来dvpp只认识h264和h265,如果是mp4文件,需要先解码成流文件。
可以用opencv解码成流文件,但是张小白突然发现200DK上安装了ffmpeg.
那就用ffmepg将mp4转换成H264文件吧!
ffmpeg -i 00_31_18-00_32_18.mp4 -vcodec h264 my.h264
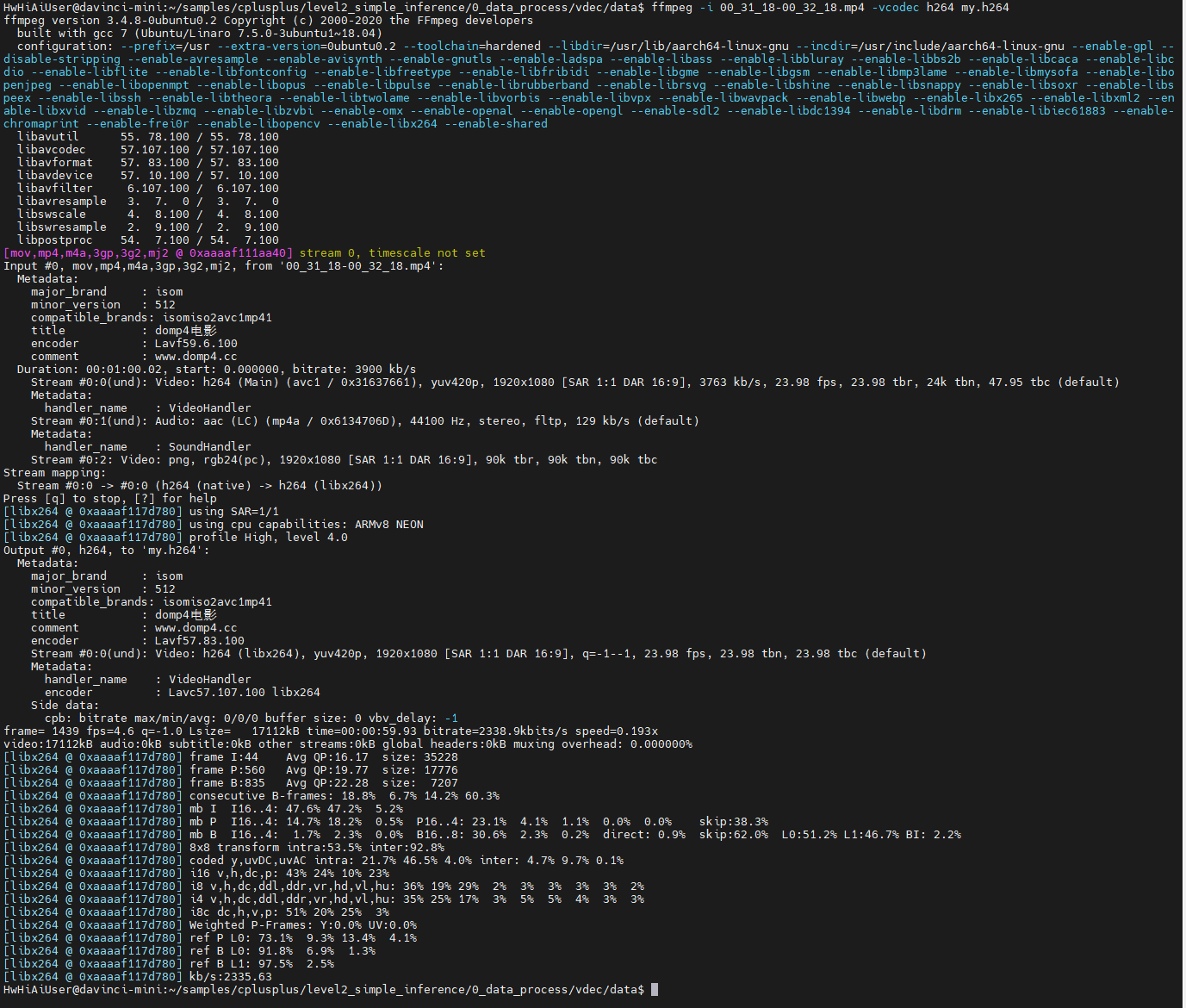
成功生成了my.h264文件。
再回到vdec目录,修改src/main.cpp:
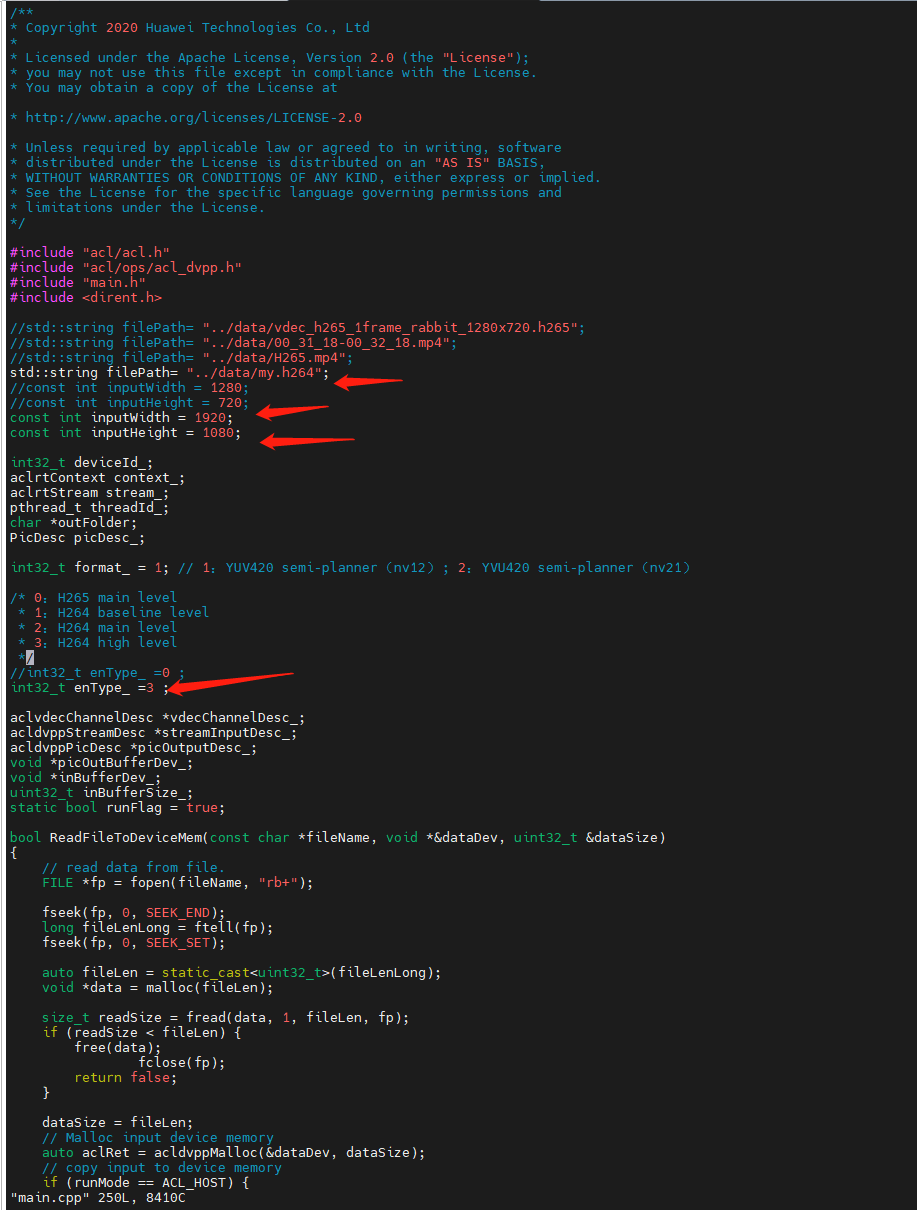
文件名改为 my.h264, 分辨率改为 1920X1080,enType=3(H264 high level)
切换到 ../scripts下重新编译:
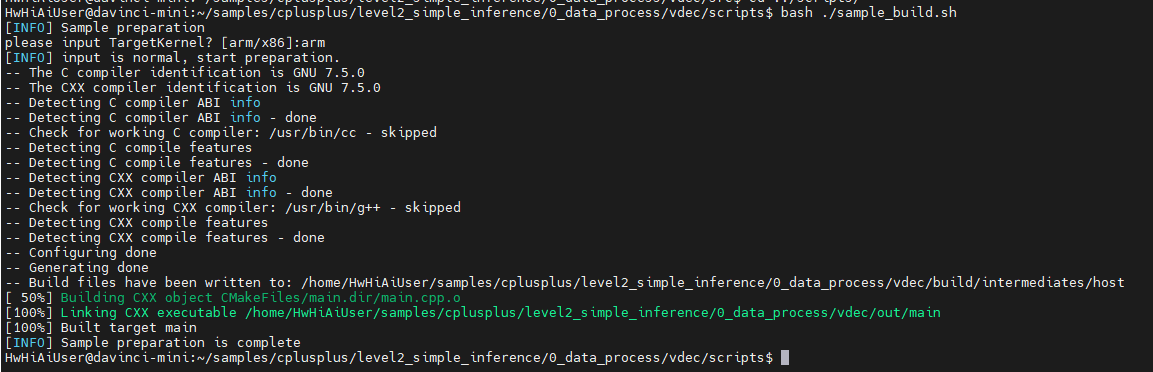
切换到 ../out/output目录,清空 *.yuv文件:
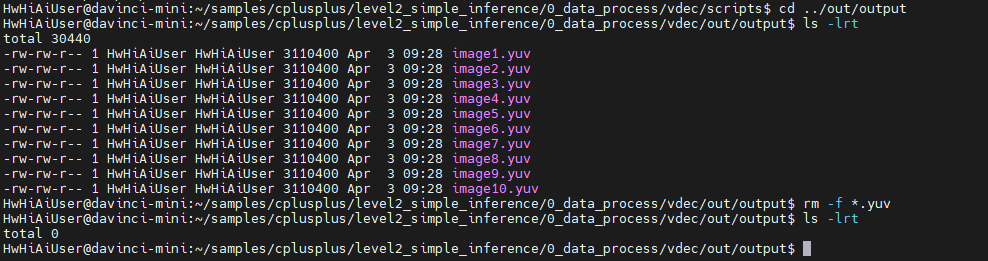
再切回到 ../../scripts下运行:

回到../out/output下检查生成的文件:

切换到jpege目录
cd ~/samples/cplusplus/level2_simple_inference/0_data_process/jpege/scripts
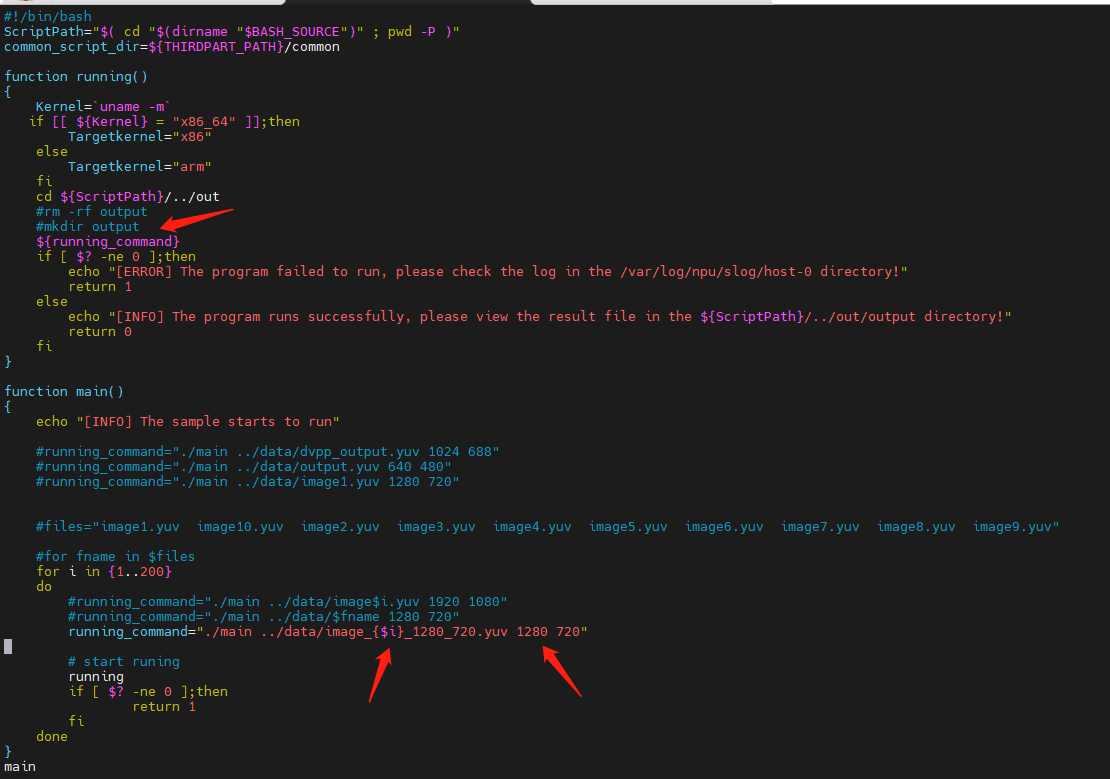
编辑sample_run.sh
将编码1个yuv文件改为循环编码所有的yuv文件,且把分辨率改为1920X1080
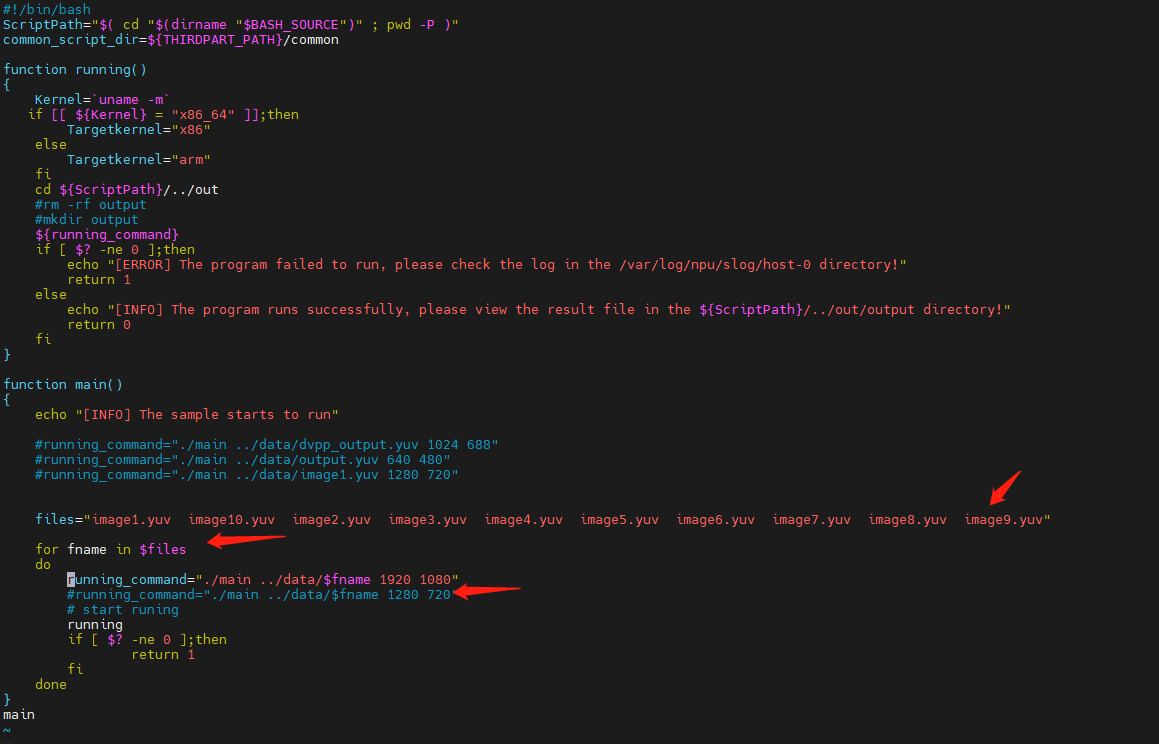
切换到 ../data目录,清除当前目录下的yuv文件:

并将 前面vdec生成的文件拷贝到这里:
cp ~/samples/cplusplus/level2_simple_inference/0_data_process/vdec/out/output/*.yuv .
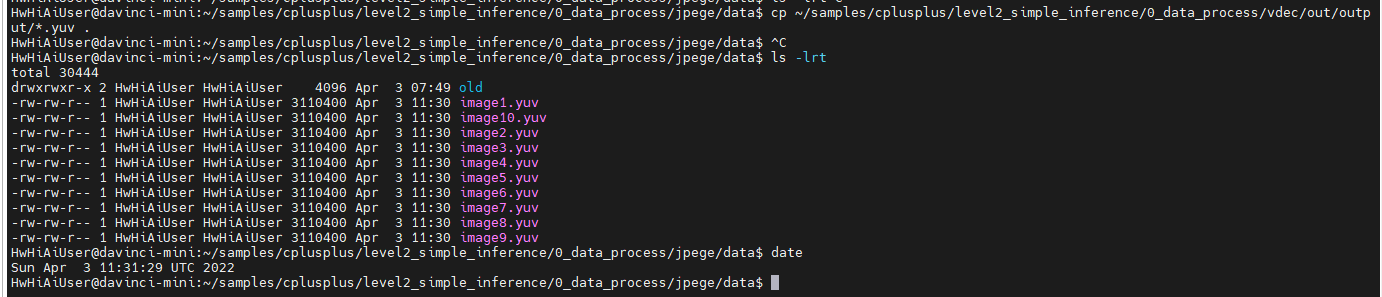
检查文件时间,已保证拷贝到了最新的文件。
清空jpege/out/output下的结果文件
cd ../out/output
rm -f *.jpg

切换回../../scripts目录,开始运行:
bash ./sample_run.sh
...
代码会循环10次进行JPEGE编码。

检查最新的JPEG文件已经生成。
使用MobaXterm将这10个文件下载到本地:
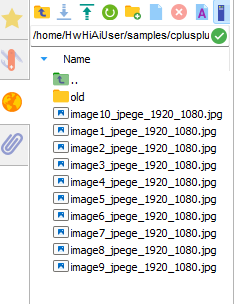

发现10个一模一样的文件:

打开其中一个文件:

看来my.h264文件已经成功解析出了第一帧。但是后面似乎还不对头。但是万里长征总算走了第一步了。。
六、VDEC解析后的图片10张一模一样的分析与VENC解决方案的尝试
关于那10张图片为啥都一模一样的问题,张小白仔细看了下vdec的sample代码,发现在主程序部分:
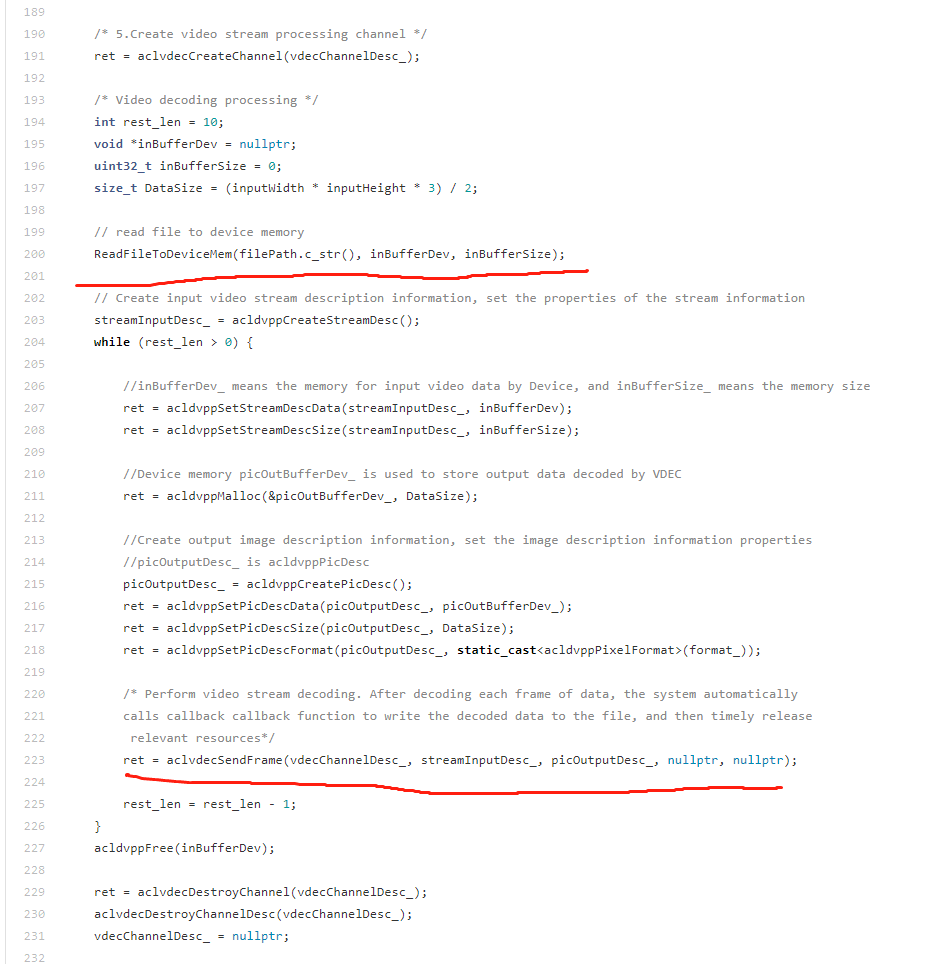
尽管是循环了10次,但是每次aclvdecSendFrame送的都是一模一样的东西。这样子肯定是图片一模一样的了。
张小白曾经将10改为100,结果就生成了100张一模一样的图片。

张小白以为在这个代码上,通过帧的偏移进行计算,循环的时候送下一帧的内容就行了,后来咨询后才知道:每帧的大小是不一样的。
毛老师是这么解释的:
那么,这种情形下,应该怎么去处理呢?毛老师建议使用 ffmpeg切帧。切完帧后,可以得到帧数据和帧大小,送给dvpp的vdec就行了。
张小白询问:ffmpeg如果可以直接将含有多帧的h264的文件保存成文件,那么又何必使用dvpp呢?dvpp能不能也具备切帧能力呢?
大毛老师在这里进行了详尽的解释:
背景知识:
mp4是封装格式(里面可能包括视频、音频或者多个音频、中英文字幕等等);
h264/h265是视频编码(主要是压缩)格式,注意仅仅是视频编码格式;
对于视频场景:
切帧:从视频流或者视频文件中找出视频的那个流,并抽出一帧一帧的视频数据,并为每一帧添加解码头信息(用于后面解码,否则解码时不知道该怎么解);这时候的每一帧数据还是按照压缩标准(h264或者h265)压缩着的数据,所以这时还叫h264或者h265数据。
解码:将h264/h265数据解码,实质上就是按照压缩标准逆向恢复原始数据的过程,例如恢复到yuv444、RGB888等;
VPC: resize、抠图、贴图、批量抠图、贴图等等,是真正为了匹配你的神经网络推理需要而做的处理;
再编码:编码成JPEG或者H264/H265.
上面这么些过程中,除了切帧建议用ffmpeg外,其他过程都可以使用dvpp加速;因为切帧速度很快,用ffmpeg在cpu上完成切帧过程也完全不是瓶颈,但是其他过程cpu上是比较慢的,一般情况下是跟不上NPU上的推理速度的,所以建议使用dvpp。
当然,dvpp目前也没有切帧能力,个人认为当前也没有必要,毕竟,cpu如果能行,为何要选择用dvpp呢?西瓜哥也追加说道:
我也觉得确实没必要dvpp切帧数据,这基本上就是个普通的数据读取加载的过程,并不是那种高密度计算的任务类型;而且尤其是对于AI推理芯片的使用场景来说,310通常的使用场景很可能是直接接收了一个摄像头的码流,或者rtmp协议的推流服务推过来的码流,都不需要这种切帧操作,实际场景很少会丢一个mp4视频文件到服务器的磁盘上,让310芯片去做处理的至此,解开了张小白的疑问。
既然这样,那么下面就去好好考虑切帧的问题吧!
张小白仔细研究了下 samples代码仓数据处理相关案例的代码:
samples: CANN Samples - Gitee.com
发现,ffmpegdecode的切帧案例,好像不大适用本作业。倒是venc的处理方式吸引了我。
venc输入是mp4,输出是.h264/h265码流。
先运行一下试试:
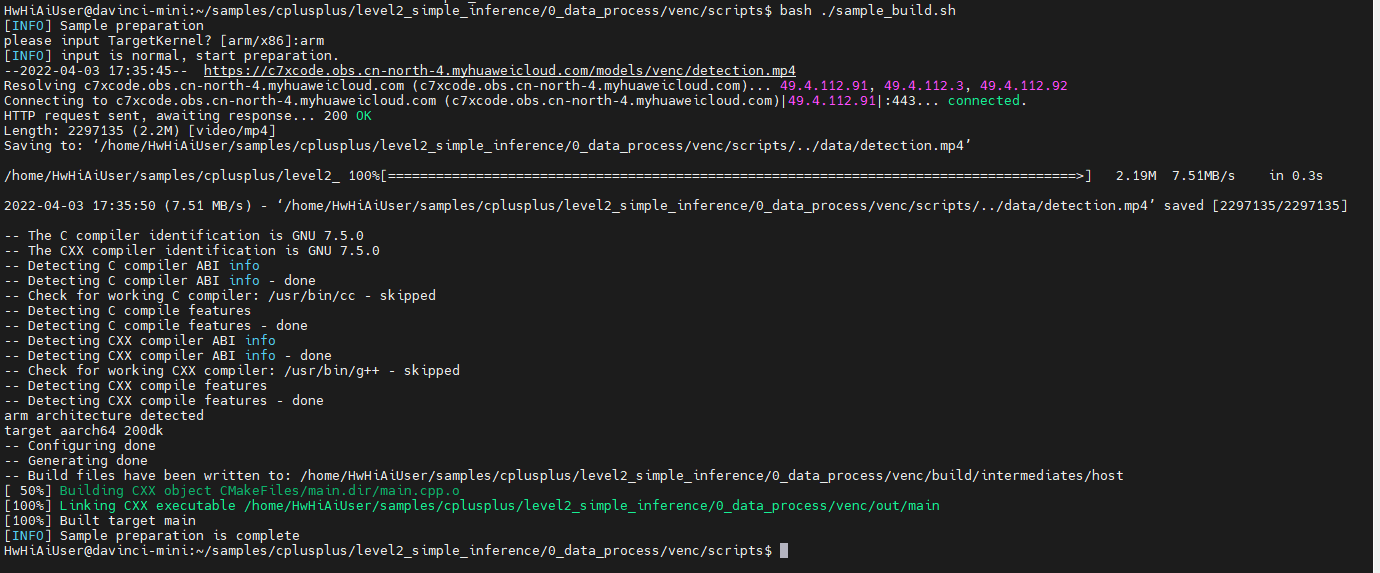
cd /home/HwHiAiUser/samples/cplusplus/level2_simple_inference/0_data_process/venc
cd scripts
bash ./sample_build.sh
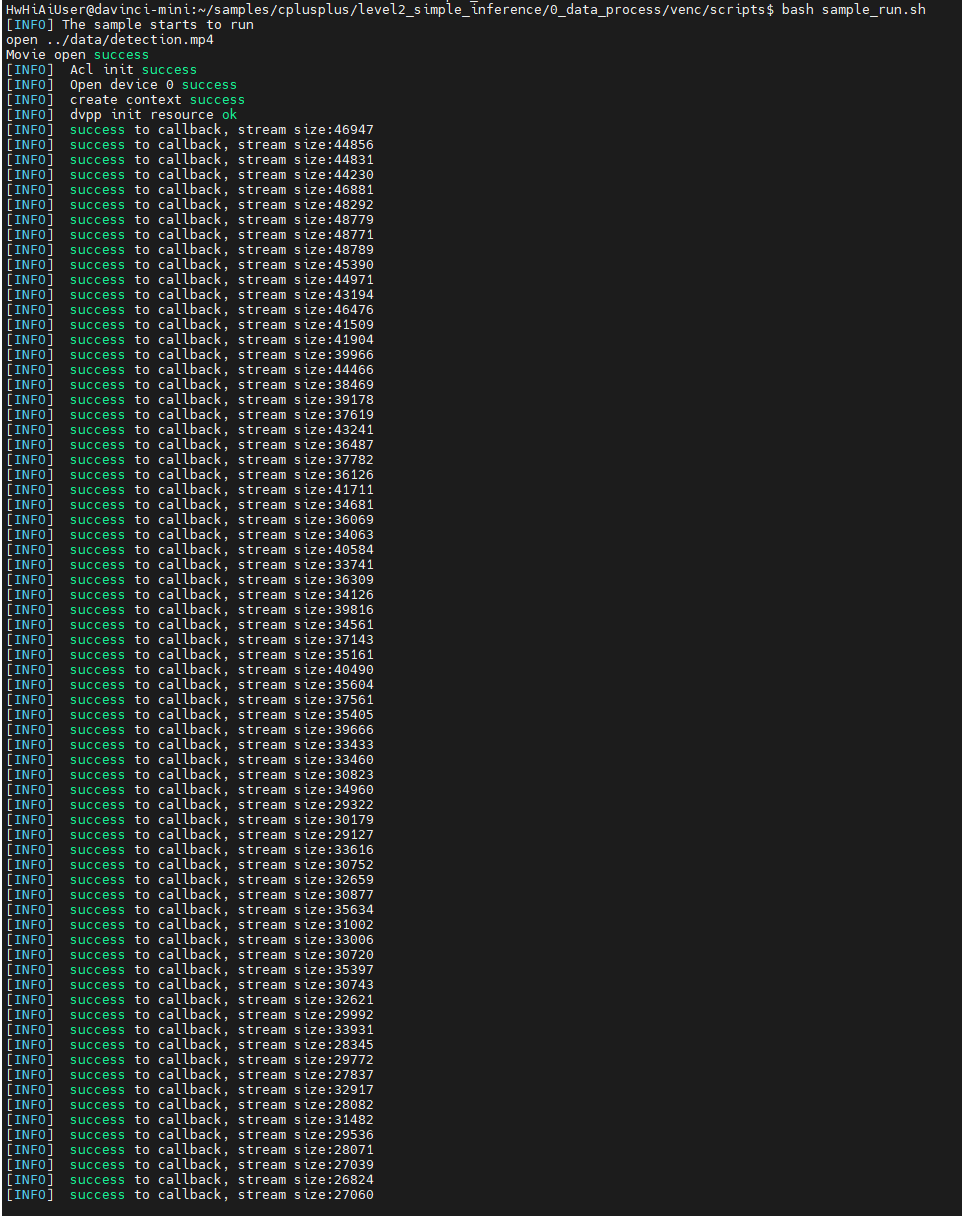
bash ./sample_run.sh
...
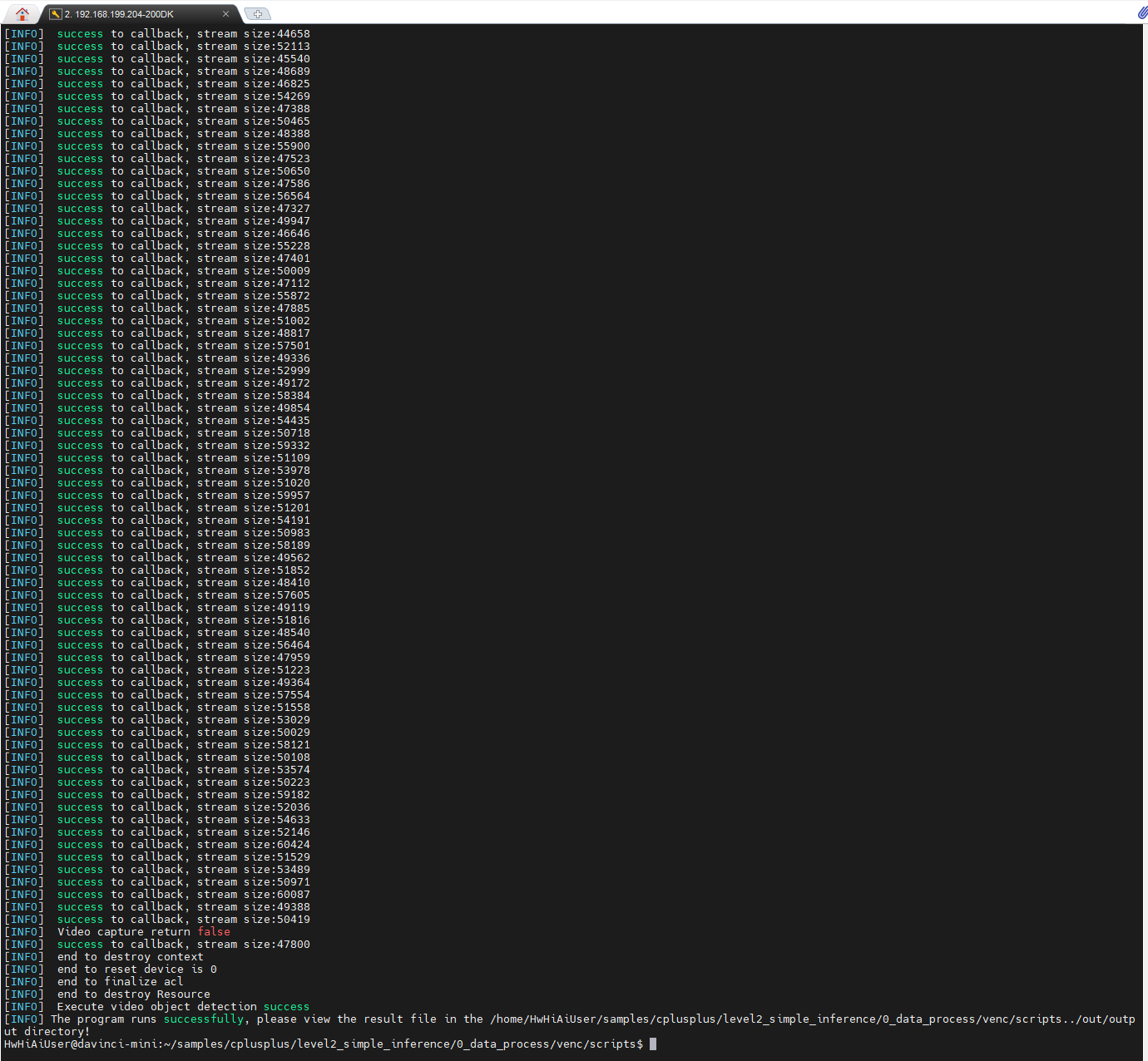
从打印出来的内容来看,似乎每帧都在解析中。张小白很是欣喜,觉得如果是这样,那么MP4文件被解析成一帧一个的.H264文件,那就非常棒了。
于是切换到out/output目录下一看:

还是生成了一个H264文件。
但既然有源码,就难不倒张小白。
张小白又开始了他的魔改代码之旅。
七、视频编码VENC的正式处理
看下图:

在原来的回调程序中,venc一直在写一个文件。所以即便是它每帧都解了,但是依然是往outfileFp去写。既然这样,我们就找个办法,每次回调写不同的文件就行了。
于是,张小白这样写:

每次回调的时候都生成一个新的文件名,然后打开这个文件写入,写完后立即关闭。
改完之后编译、运行下试试:(一样的过程就不细写命令了,全是 bash ./sample_build.sh, bash ./sample_run.sh)
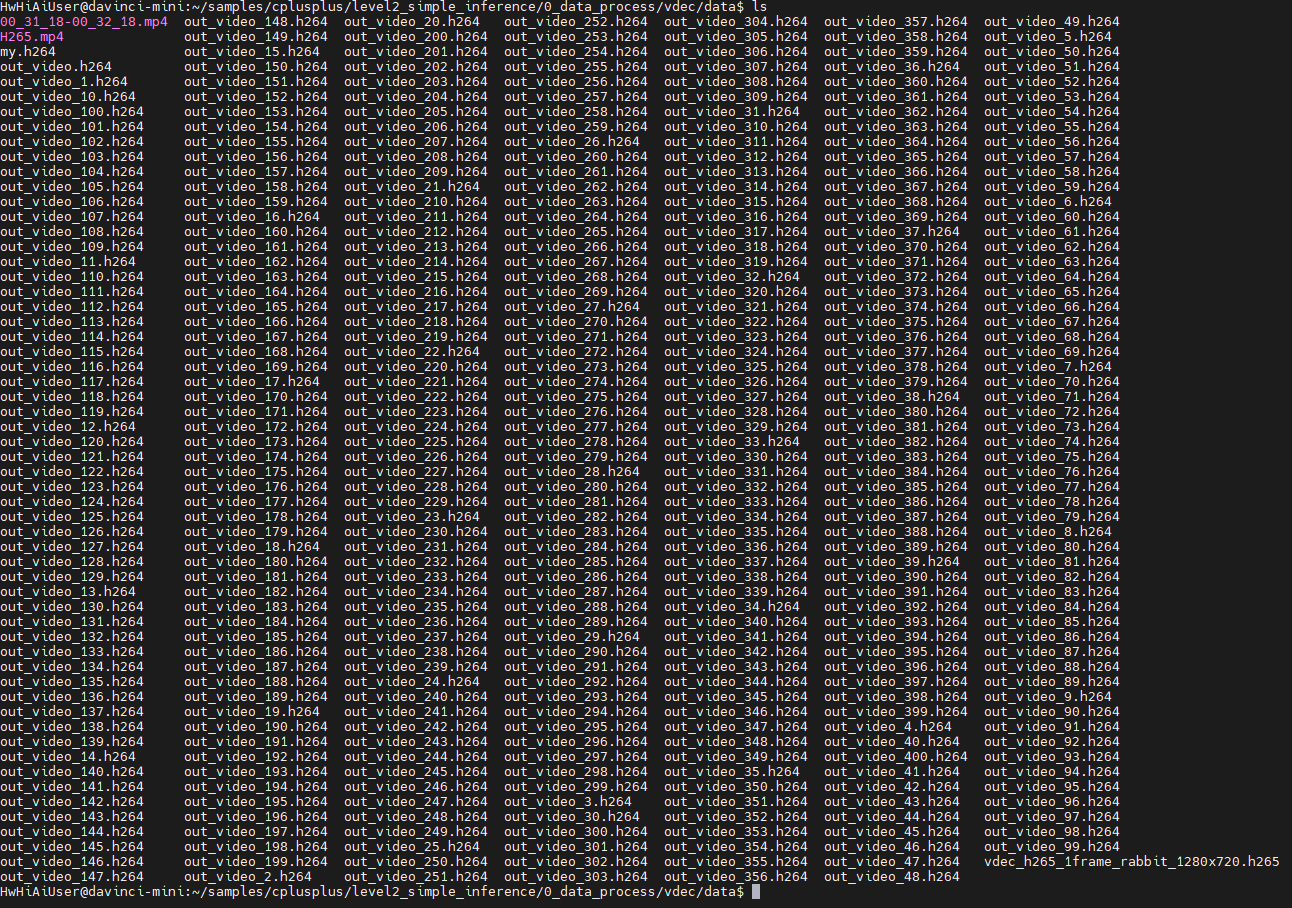
这次居然能生成不同的文件了。(其实不用居然,就是张小白努力的结果)
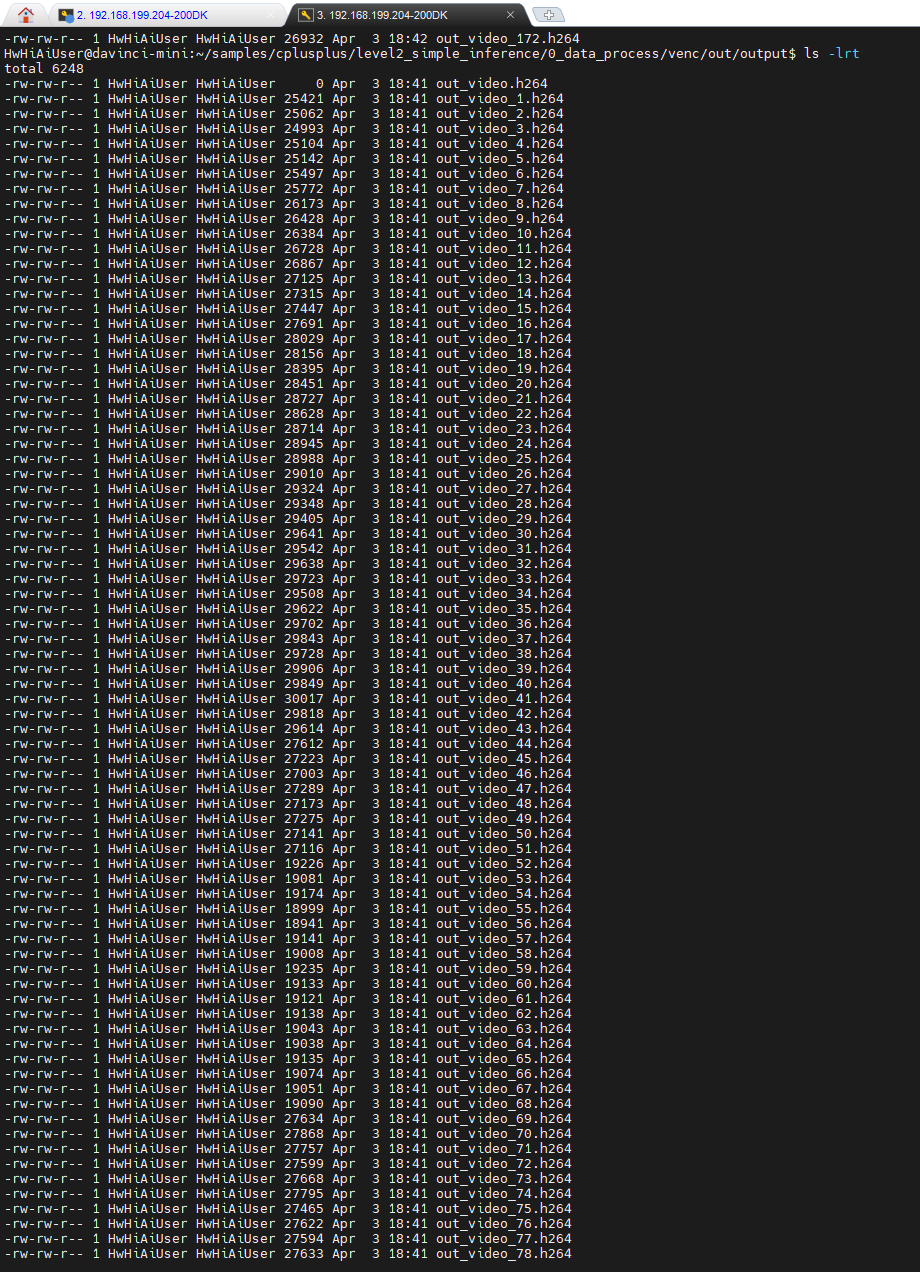
而且,通过文件的大小可以看到,每一帧是不一样的。
那么,我们更换一下前面的解题思路:
(1)修改venc代码,打开MP4文件,将每一帧保存成一个 xx.h264文件。
(2)改造vdec代码,打开不同的 xx.h264文件,对于不同的文件都转换成yuv图片
(3)改造resize代码,打开不同的1080p的 yuv文件,进行缩放:1920X1080-》1280X720 生成不同的 720p的yuv文件。
(4)改造jpege代码,打开不同的 720p的yuv文件,生成不同的720p的jpg文件。
现在只是将第一步基本实现了,但是尚未读取 张小白自制的 1分钟黑寡妇的MP4。
下面开始操作:
将 H264的文件拷贝到 ~/samples/cplusplus/level2_simple_inference/0_data_process/venc/data 目录:

修改 sample_run.sh 让其读取这个MP4:
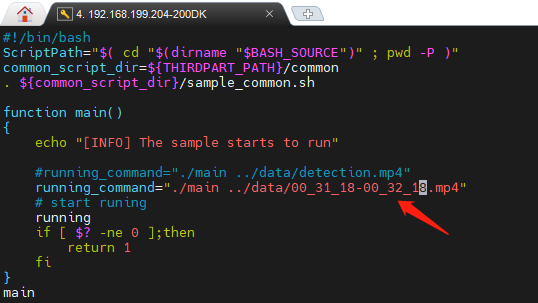
运行:

...
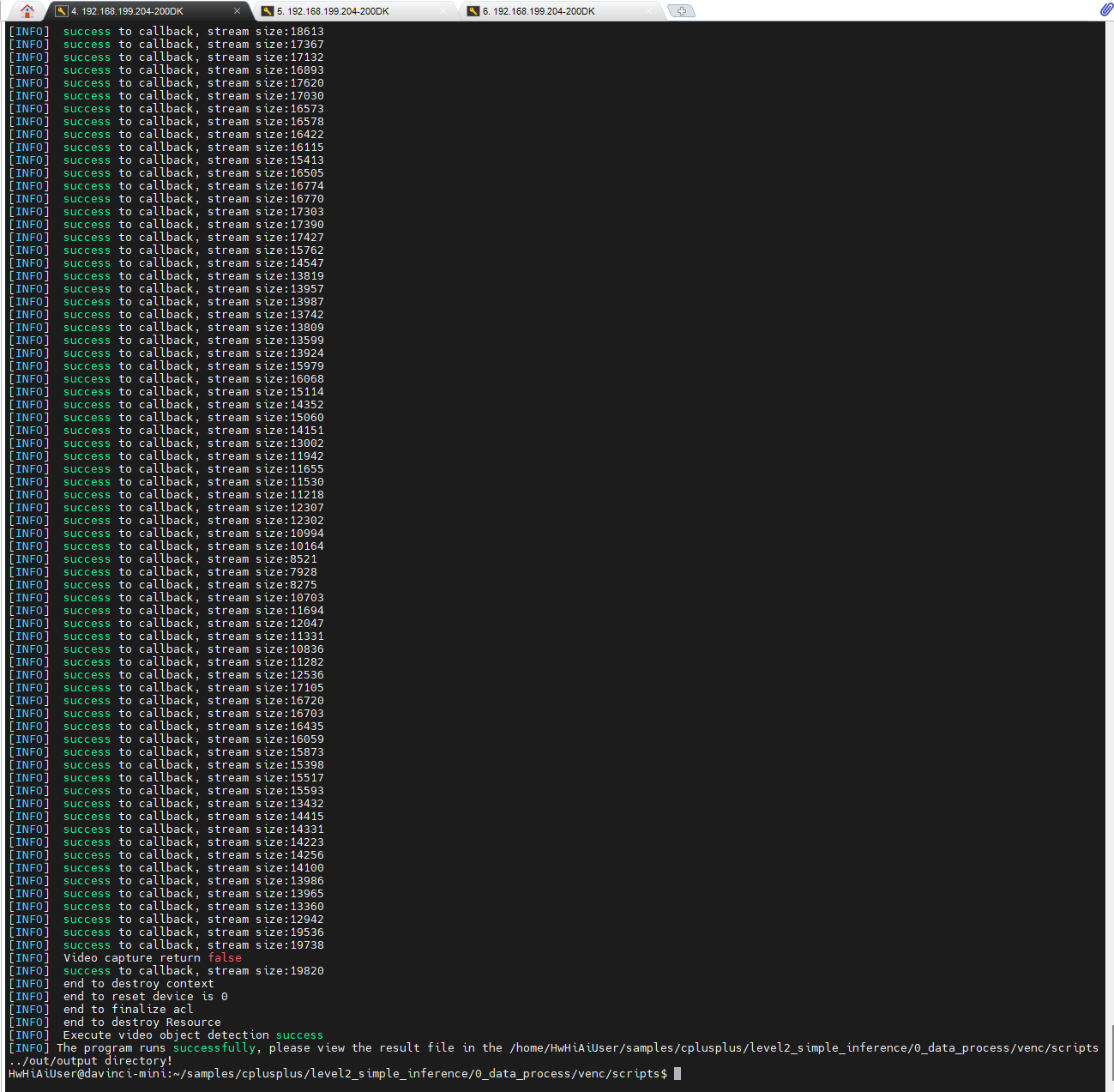
耐心等待,一共会生成1439多个H264文件(从0到1438),其中out_video.h264 0个字节,是原来的文件,张小白没有把代码删掉,所以还会有个空文件。
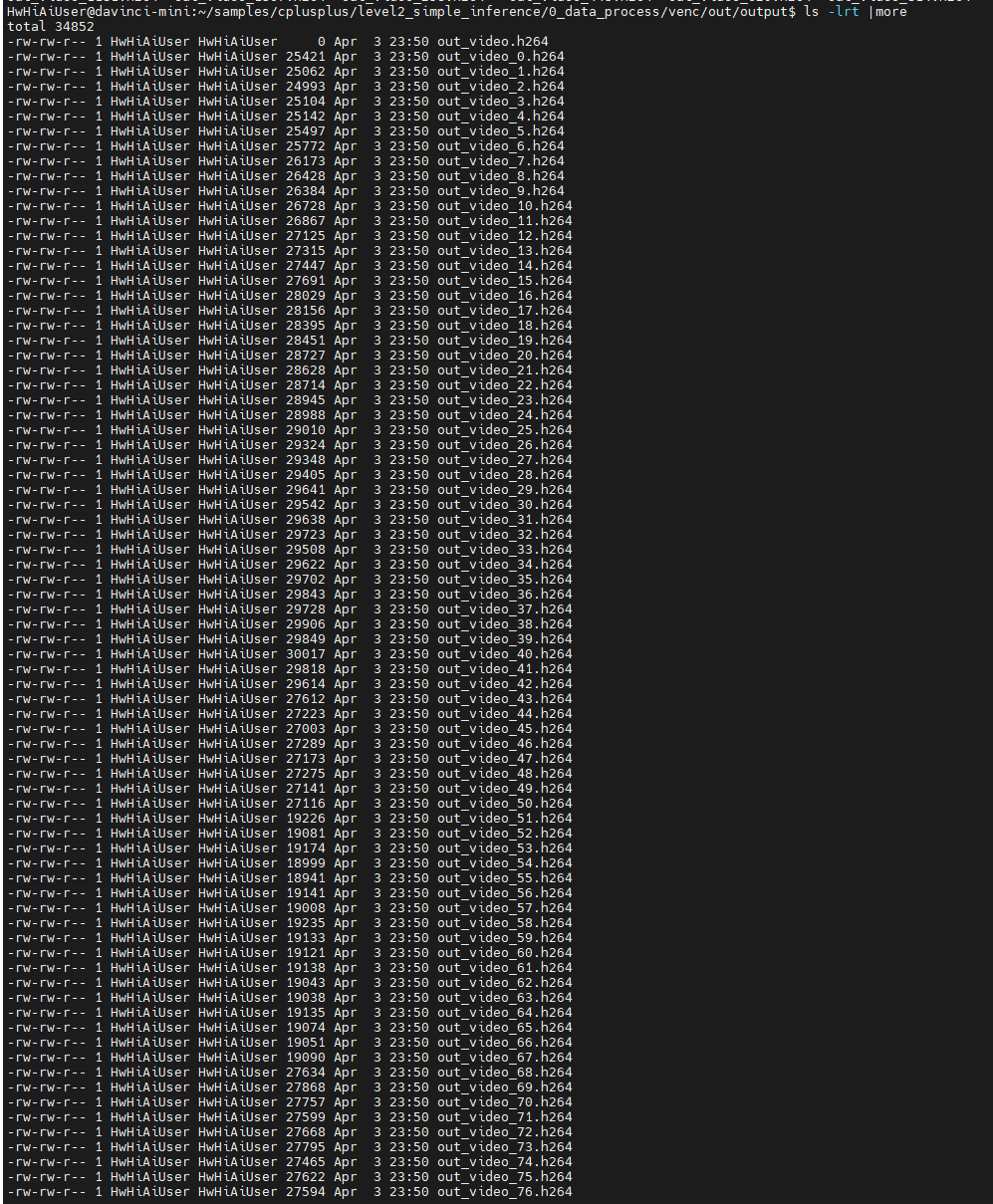
。。。
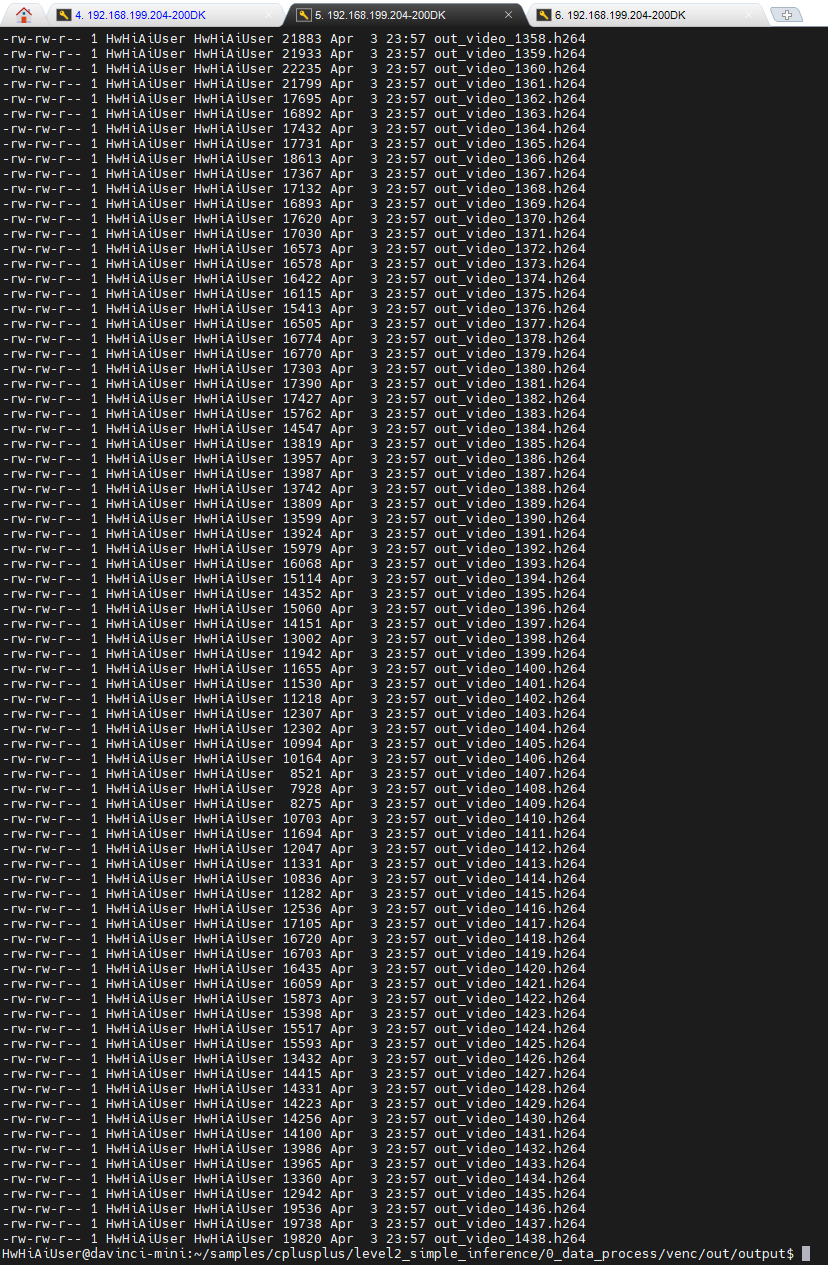
这1439个文件各不相同,保证了不会出现像前面那样图片都一样的情况。
八、视频解码VDEC的正式处理
切换到 vdec目录下:
cd /home/HwHiAiUser/samples/cplusplus/level2_simple_inference/0_data_process/vdec/data
将前面的输出拷贝到vdec的输入目录data:
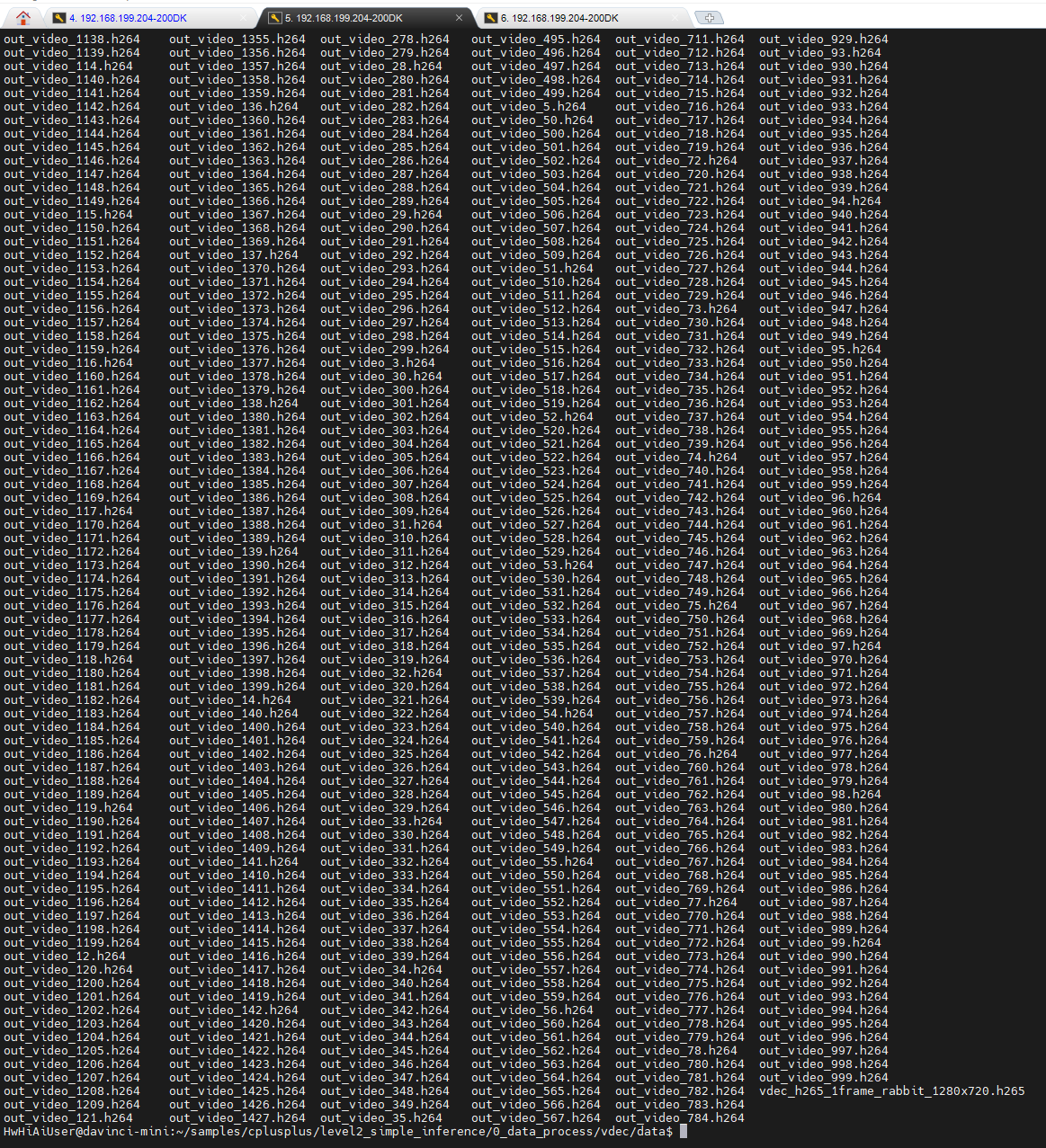
cp /home/HwHiAiUser/samples/cplusplus/level2_simple_inference/0_data_process/venc/out/output/*.h264 .
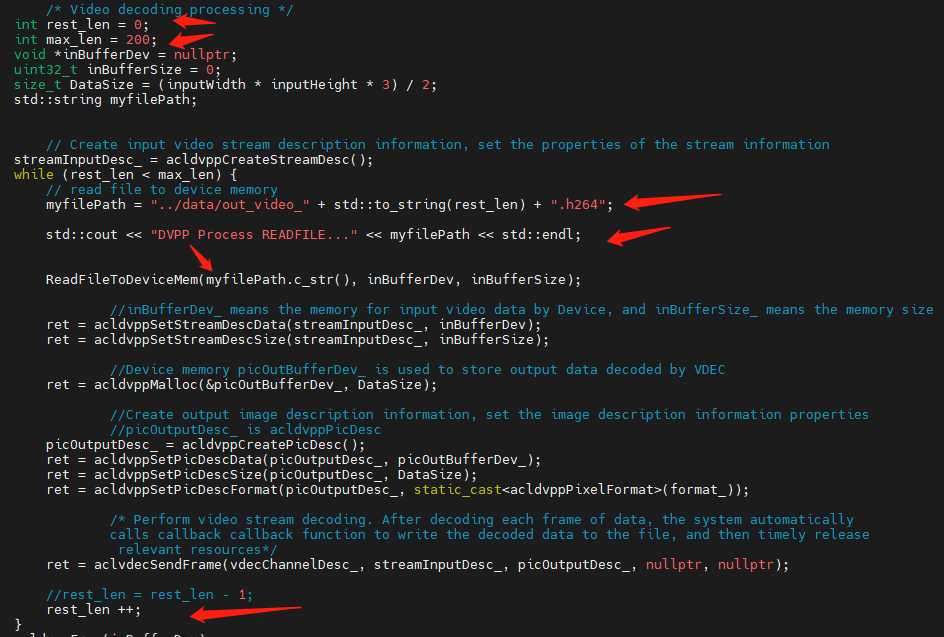
修改vdec的源码,让其在aclvdecSendFrame的时候送 不同的H264文件对应的不同帧:
因为有1000多个文件,为了容量和时间考虑,暂时处理200个H264文件吧:
编译venc代码

清空 vdec/out/output目录:

运行vdec代码:
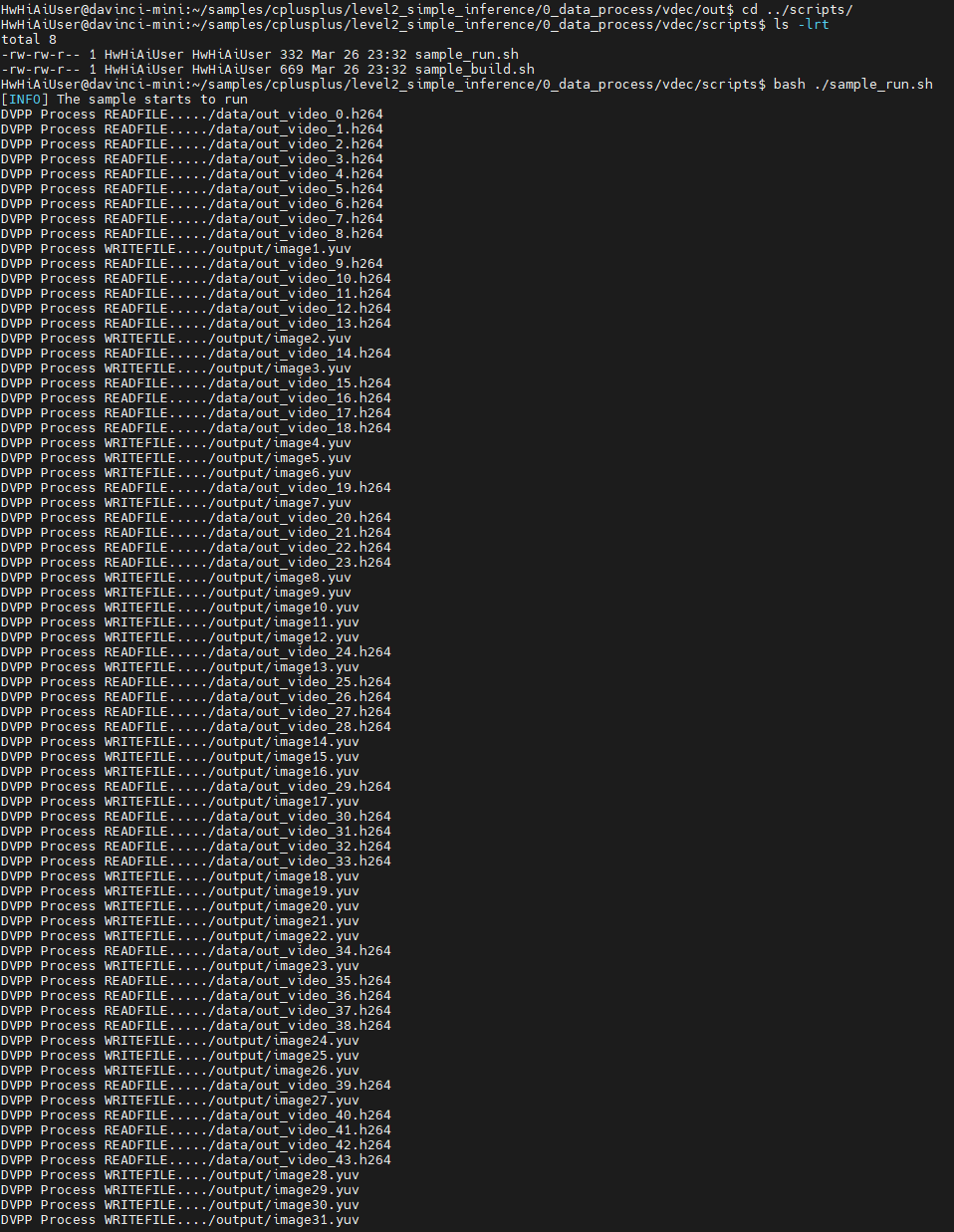
打出的日志标明了读取哪个H264文件,写入哪个yuv文件。。。
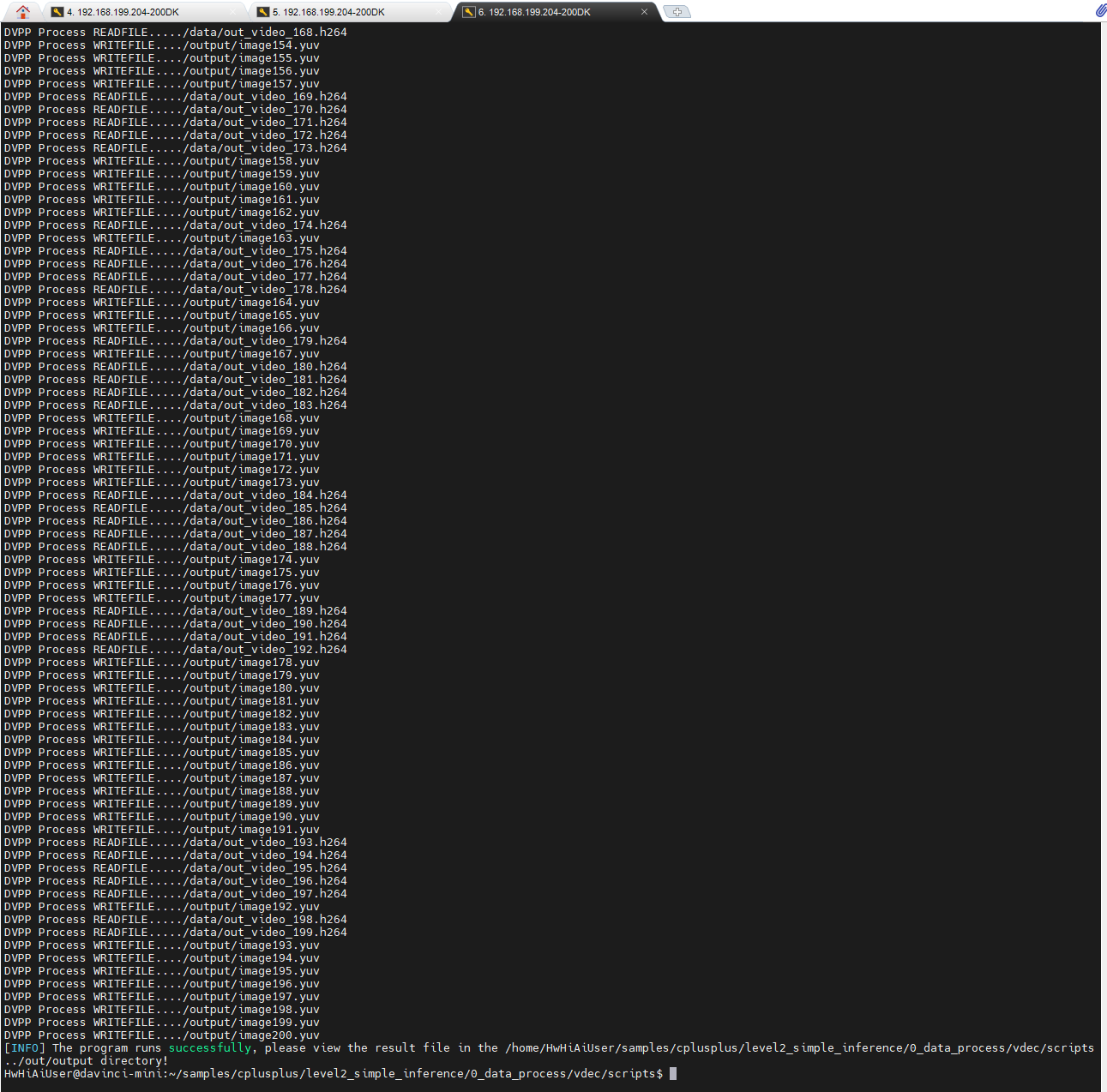
执行完毕后,在vdec/out/output目录下生成了200个imagexxx.yuv文件:
但是,由于都是1920X1080的size,所以yuv文件倒变成了一样的大小:

九、YUV图片缩放RESIZE的正式处理
进入resize的data目录,将上一步的200个yuv文件拷贝过来:
cd /home/HwHiAiUser/samples/cplusplus/level2_simple_inference/0_data_process/resize/data
cp /home/HwHiAiUser/samples/cplusplus/level2_simple_inference/0_data_process/vdec/out/output/image*.yuv .
resize的main.cpp代码需要打印一下输出的文件名:
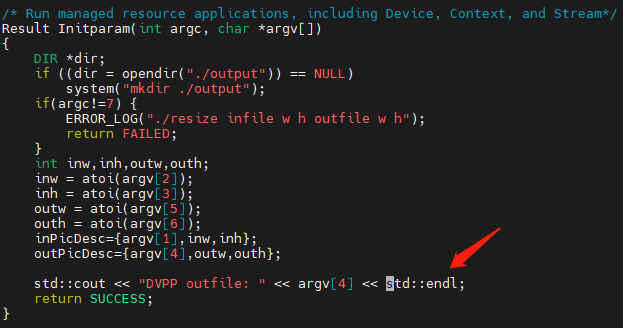
编译:
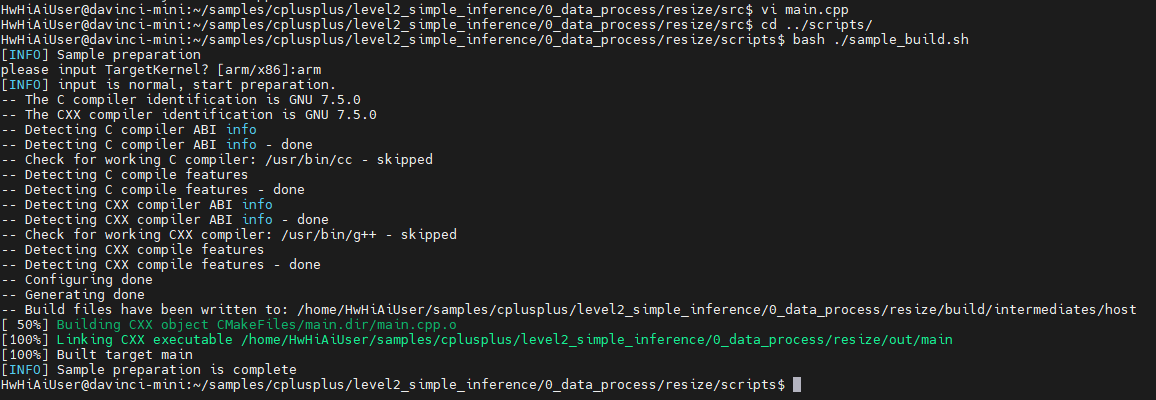
resize的sample_run.sh 需要把现在的处理单个yuv文件变成一个循环:
去 resize的out/output目录下清空文件:

回来运行 bash ./sample_run.sh

...
耐心等待200个文件resize完毕:

生成的文件查看一下:
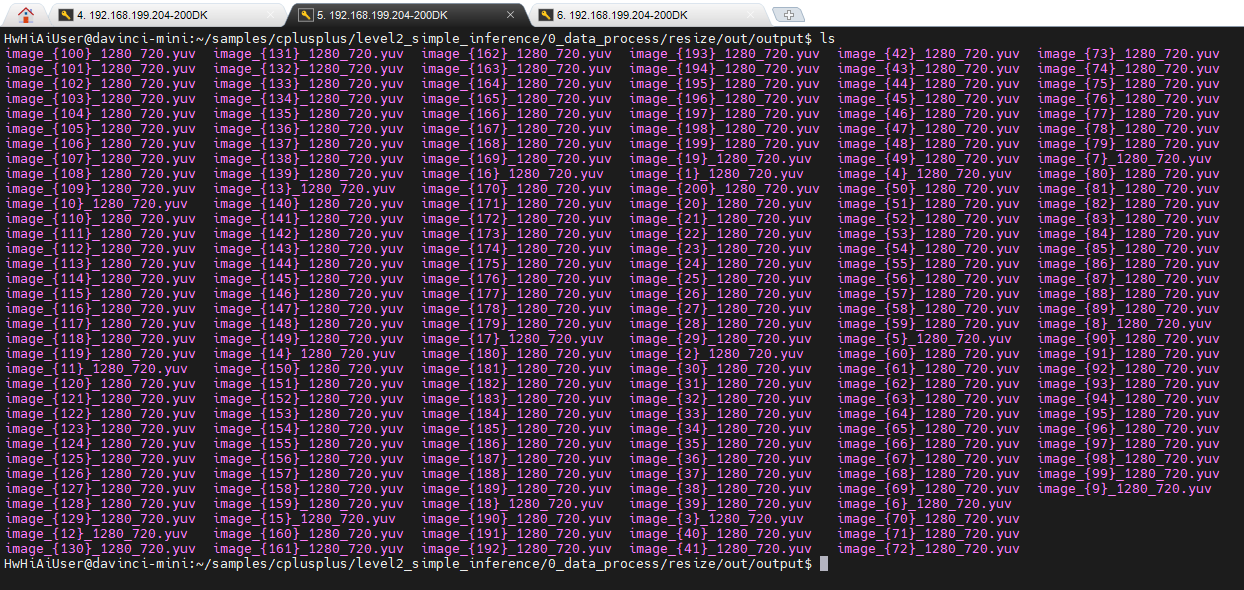
生成了200个yuv文件,大小均为:1382400.

前面data下的文件大小均为:3110400
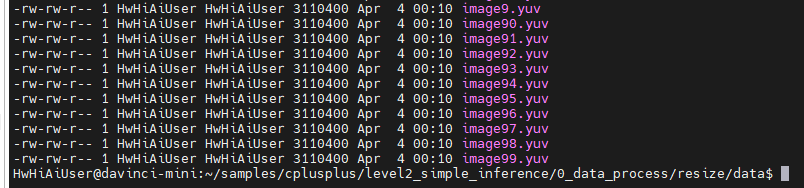
可见应该是被缩小了的。
十、图片编码JPEGE的正式处理
切换到 jpege目录
cd /home/HwHiAiUser/samples/cplusplus/level2_simple_inference/0_data_process/jpege
cd data
将resize的结果yuv文件拷贝过来:
cp /home/HwHiAiUser/samples/cplusplus/level2_simple_inference/0_data_process/resize/out/output/image*.yuv .
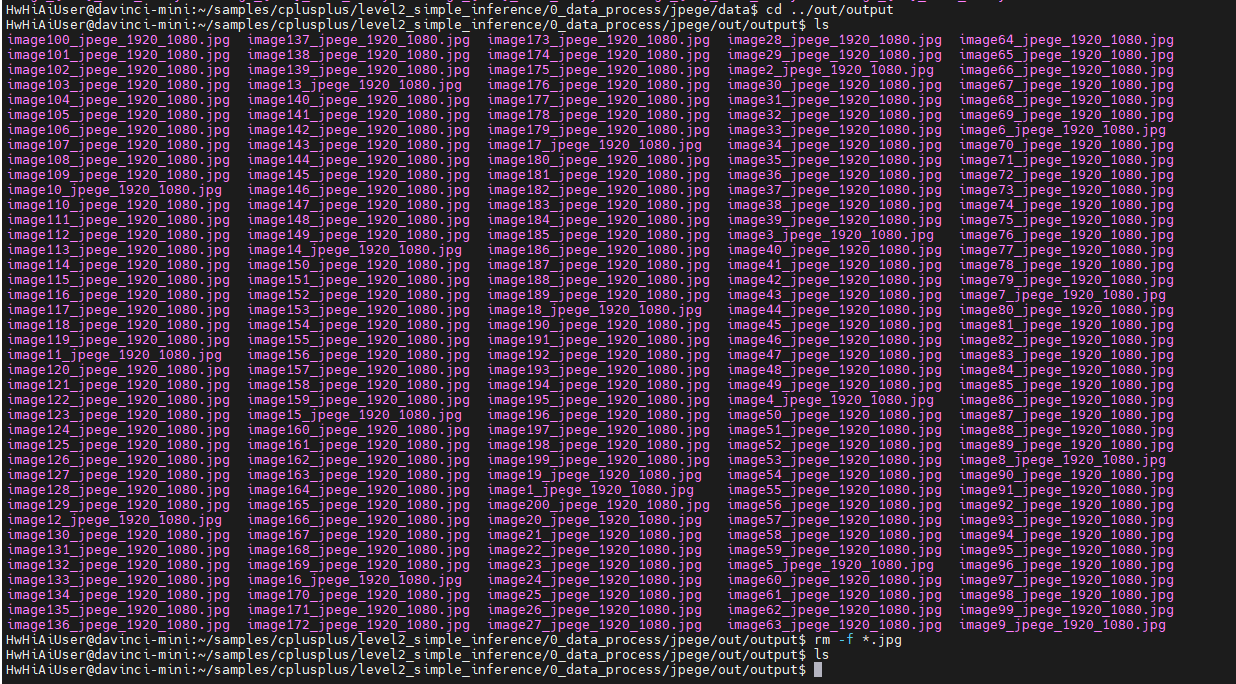
清空jpege的output目录
修改sample_run.sh
执行jpege编码的编译:
执行:
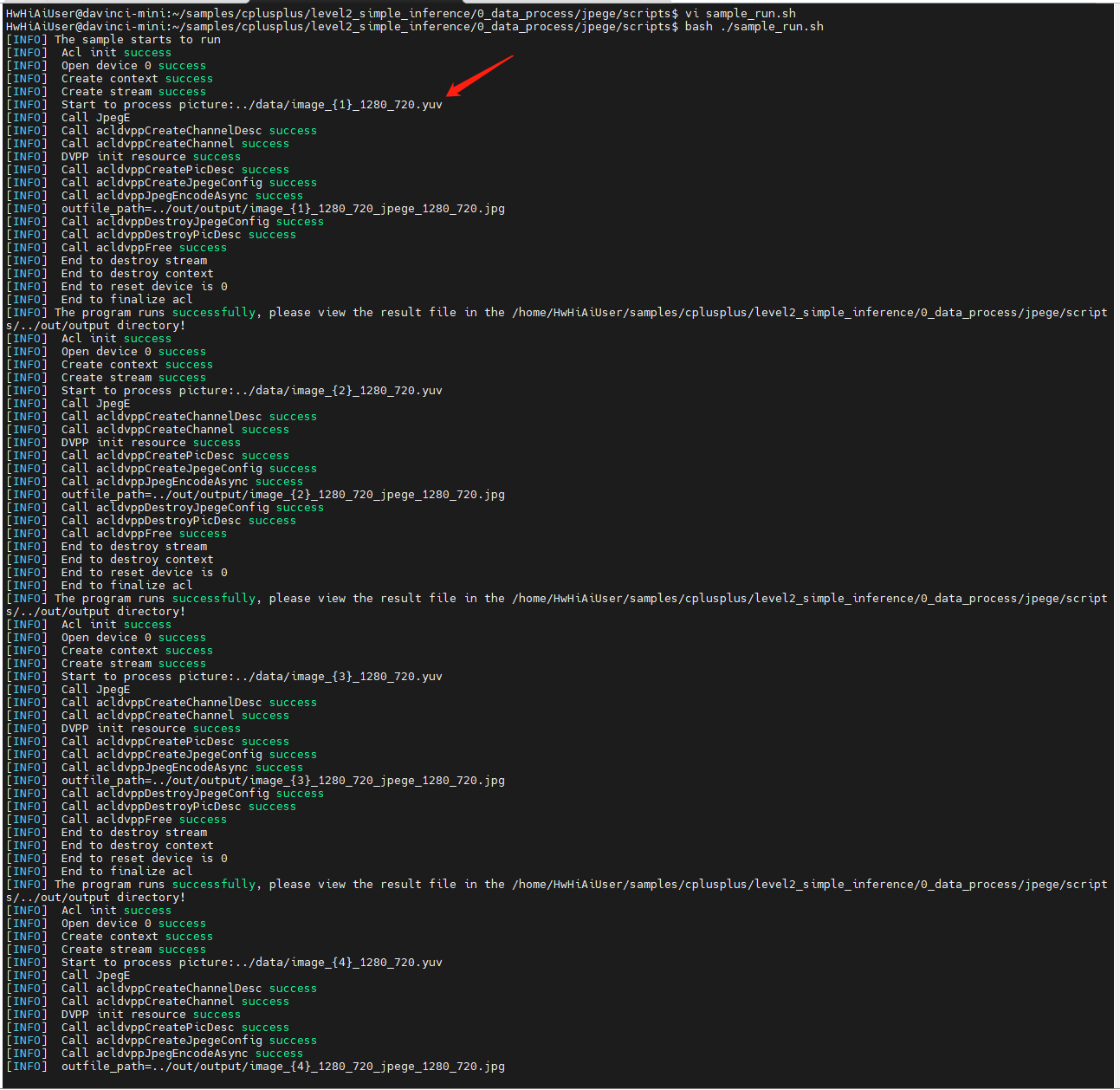
耐心等待200个文件执行结束:
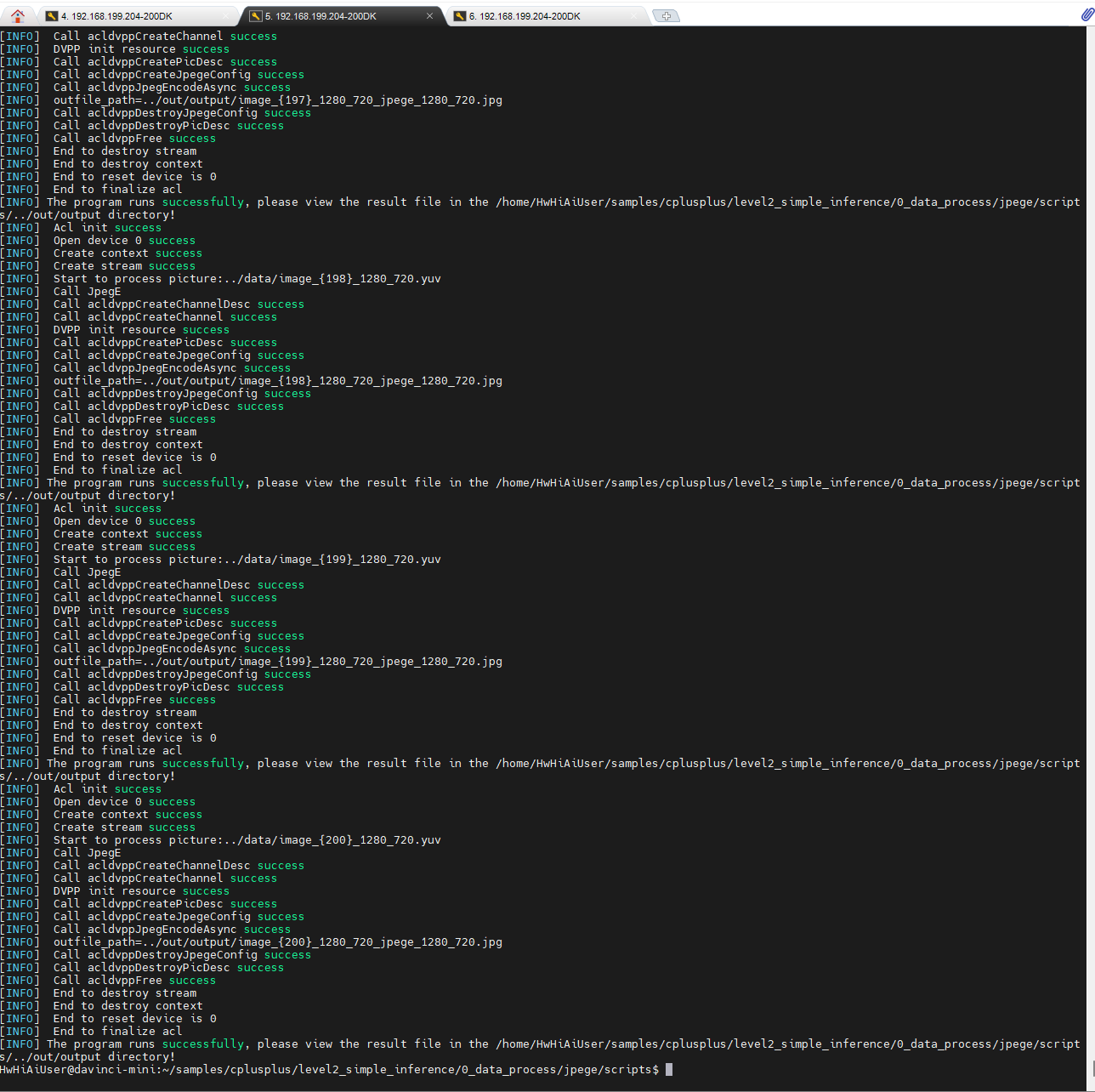
去output目录下查看结果的jpg文件:

可见,这200个文件都不一样。
十一、运行结果的检查
使用MobaXterm将其下载下来仔细看看:

可以看到文件各不相同:

随便打开几个看看:
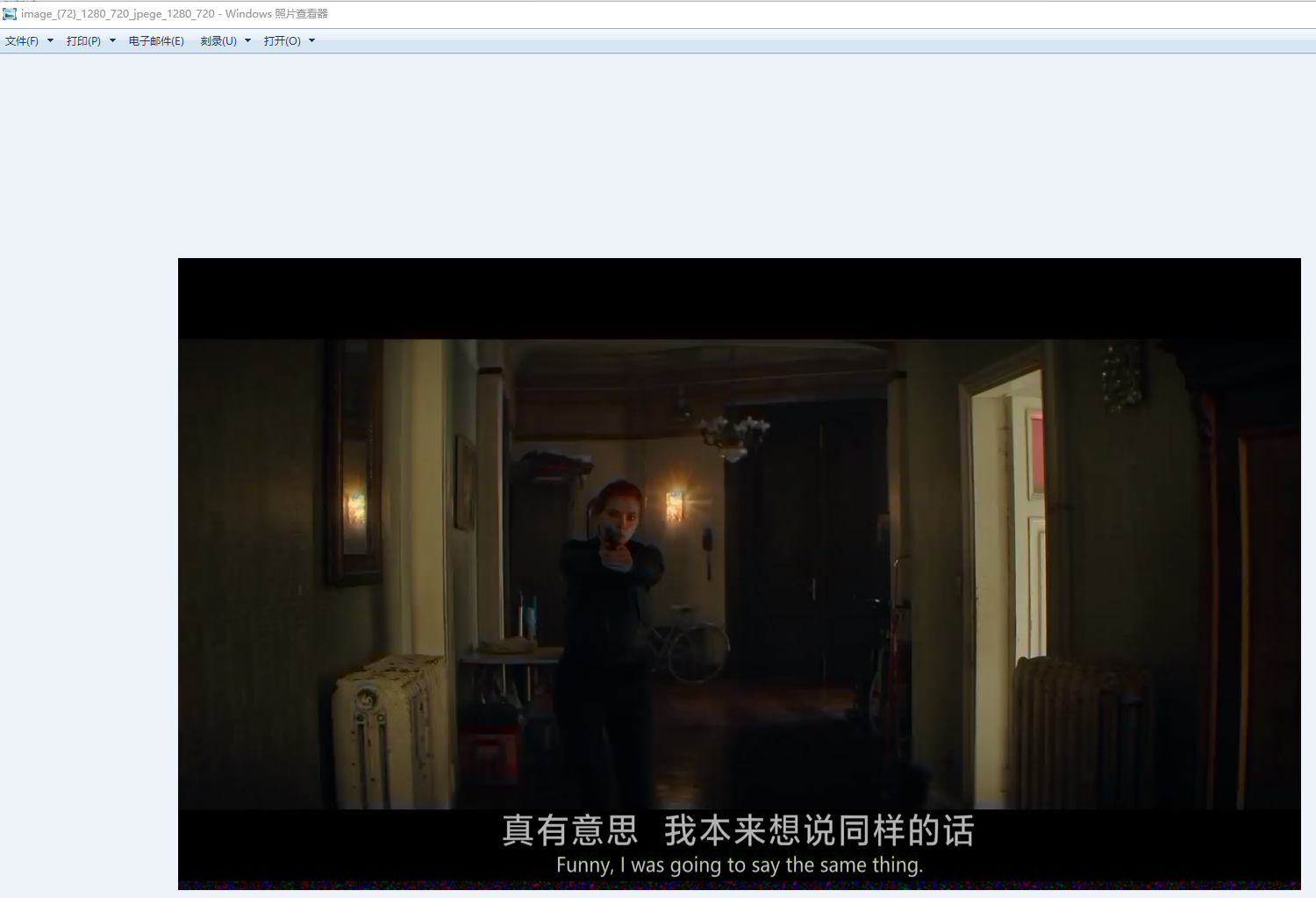
恩,我们能像成年人一样谈谈吗?
这就完成了本次的大作业2。
(全文完,谢谢阅读)


















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











