






1.前言
在我们进行实际的应用开发时,都会随着对一款产品或者AI芯片的了解加深,大家都会想到有什么可以加速预处理啊或者后处理的手段?常见的不同厂家对于应用开发的时候,都会提供一个硬件解码和硬件编码的能力,这也是抛弃了传统的opencv或者pl等在cpu上话费多的时间进行视频解码和编码,而对于昇腾产品,310一系列产品来说,他也会有自己的数据媒体处理单元,如下图所示:参考学习链接:
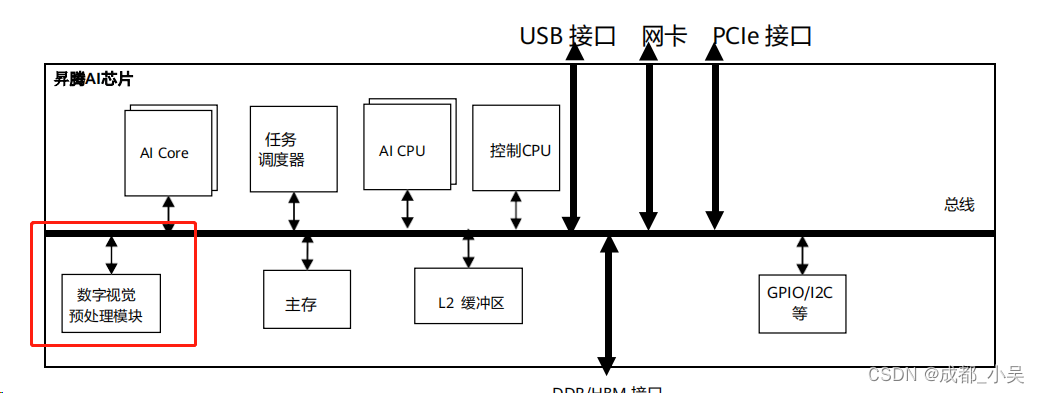
硬件产品结构示意图,内置的有dvpp模块用于数据预处理,AI core用于矩阵、向量等计算;不会占用cpu的资源,刚了解昇腾框架的伙伴可能会用下面的开发顺序进行编写代码:
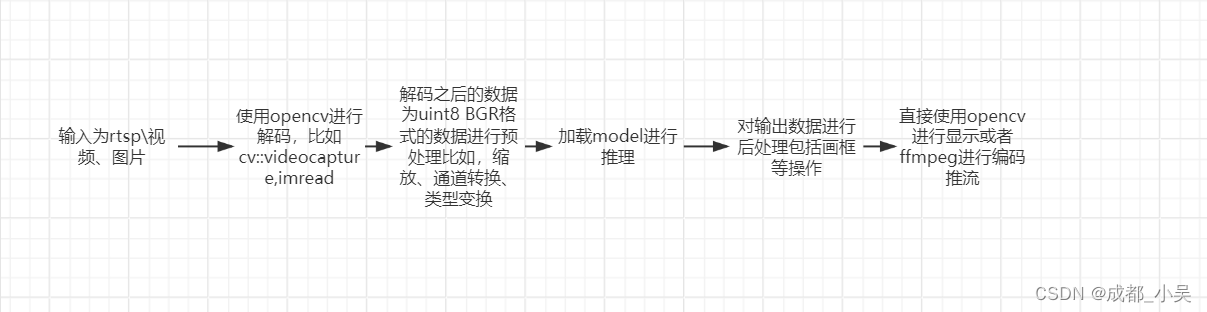
(1)首先输入视频源的选择:rtsp流、视频、图片等
(2)直接使用opencv的api进行读取,也就是解码,其实opencv读取视频还是蛮快的,读取rtsp确实有一些慢,而且还占用cpu的资源,
(3)使用opencv解码出来之后的图片是,bgr,uint8,NHWC格式的图片,对于不同的模型输入,需要进行转换为模型需要的输入,比如resize缩放图片指定大小,数据格式转换从uint8 到float32 16\以及通道的变换,这一步也是大家的预处理。
(4)送入模型进行推理,大家可以做int8量化之类的操作
(5)模型后处理,对输出的数据进行筛选,获取最终的目标。
(6)opencv直接显示或者数据编码使用ffmpeg或者其他工具进行推流
以下是使用ACL我在整个端到端应用开发时总结的比较优选方案:
(1)使用dvpp进行rtsp和视频的解码,dvpp解码之后的数据为yuv420sp,是在device中的数据,无需内存拷贝,这个过程是将h264/h265的码流解码为yuv的数据,这一过程会在npu硬件执行,但是底层的实现是先通过ffmpeg进行解封装,再进行dvpp解码,内部实现了多线程:参考样例如下:
g_cap_ = new AclLiteVideoProc(g_streamName_);stream是视频路径或者rtsp
ImageData testPic;
AclLiteError ret = g_cap_->Read(testPic);将解码数据传送到testpic结构体中:
这个ImageDATA 结构体如下:
struct ImageData {
acldvppPixelFormat format;
uint32_t width = 0;
uint32_t height = 0;
uint32_t alignWidth = 0;
uint32_t alignHeight = 0;
uint32_t size = 0;
std::shared_ptr<uint8_t> data = nullptr;
};(2)解码之后通过VPC进行图像缩放,由于dvpp解码之后的数据为YUV格式,所以模型转换的时候需要配合aipp,将模型的输入改为yuv输入与模型对齐。
ImageData resizedImage;
ret = g_dvpp_.Resize(resizedImage, testPic, g_modelInputWidth, g_modelInputHeight);(3)将数据直接存入模型中进行推理:
(4)模型的后处理,怎么和原图进行画框,可以将原始的yuv图片转换为opencv的图片进行画框,或者使用frretype直接在yuv上进行画框,参考案例如下:
方法一:将device的原图拷贝到cpu测转换为cv::mat类型进行画框:
ImageData yuvImage;
ret = CopyImageToLocal(yuvImage, testPic, g_runMode_);
if (ret == ACLLITE_ERROR) {
ACLLITE_LOG_ERROR("Copy image to host failed");
return ACLLITE_ERROR;
}
cv::Mat yuvimg(yuvImage.height * 3 / 2, yuvImage.width, CV_8UC1, yuvImage.data.get());
cv::Mat origImage;
cv::cvtColor(yuvimg, origImage, CV_YUV2BGR_NV12);方法二;直接在yuv上进行绘制目标框图:参考案例如下:
samples: CANN Samples - Gitee.com
(5)将画框后的数据硬件编码为h264文件用于ffmpeg进行推流,编码代码流程参考案例:
samples: CANN Samples - Gitee.com
由于ACL仅支持编码yuv的图片到h264/265所以建议大家可以使用第二种方法进行编码,不需要再次使用ffmpeg进行软件编码,大大可以节约时间。
整个流程可以在原来的软件编码情况下快1.5倍左右。关于ffmpeg推流可以加我学习群或者网上找一些简单的源码推流工具,如果大家有兴趣可以加入a群:855986726
下一章我们继续讲解如何进行多模型串联推理,

















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









