







笔者按:
最近接了一个项目,要把别人训练的YOLOv7-tiny模型,移植到华为Atlas平台,利用Ascend昇腾NPU做推理,同时实现了python和c++的应用。由于笔者是第一次接触华为这个平台,移植过程中还是踩了不少坑的,这里开一篇文章,介绍整个移植的流程、踩过的坑和debug的思路。
整个项目大约花费了我2周时间,这是在我有一定的python、c++和工程经验的基础上。另外当然生成式AI在这个过程中也帮我做了不少事情,不得不感慨科技的进步。
这里不得不吐槽一下,华为Ascend平台的文档和Sample虽然很全面,但是作为一个初上手的人,真的很难知道从哪入手。直接啃API文档肯定不现实,所以肯定还是要找一个和自己的应用比较类似的Sample,从这个sample入手,修改代码,实现自己的目的。但Sample也各有不同,在硬件文档中、cann文档中,都有各自的sample;在官方sample中,有python的、c++的,c++中还有基于acl的和acllite的,这acllite和acl有啥区别?真的很难弄懂……
开这篇文章主要是记录一下我的历程,所以比较偏向记录,不喜勿喷……
Ascend的Sample地址:https://gitee.com/Ascend/samples
本文参考的Sample:
samples/inference/modelInference/sampleYOLOV7
samples/inference/modelInference/sampleResnetQuickStart
samples/inference/modelInference/sampleResnetAIPP
samples/inference/acllite/cplusplus
以及Atlas 200i DK A2文档中的目标检测sample
目录
0 Start Up
拿到项目,我首先确定了Python移植 -> C++移植的路线,这肯定是出于Python的debug易用性考量的。
基础的配环境的部分就不讲了,主要安装了CANN(对应CUDA)和MindStudio(IDE),配了环境变量,还装了如OpenCV等一系列库。注意为了避免错误,这些库我都是下载的源码,然后手动编译的。Atlas平台的cpu架构是ARM指令集的,所以各种包编译的时候也要编译ARM的版本。
最后是选择一个可以快速启动的sample。在Atlas A200i DK平台的官方文档中就有一个目标检测的sample,这里自然是以它为基础,开始我们的移植。
1 Python移植和模型转换
这个sample是以YOLOV5为基础的一个例子。简单阅读代码,发现主要需要操作的部分都在YOLOV5.infer()这个函数里面。
def infer(self, img_bgr):
labels_dict = get_labels_from_txt('./coco_names.txt') # 得到类别信息,返回序号与类别对应的字典
# 数据前处理
img, scale_ratio, pad_size = letterbox(img_bgr, new_shape=[640, 640]) # 对图像进行缩放与填充
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, HWC to CHW
img = np.ascontiguousarray(img, dtype=np.float32) / 255.0 # 转换为内存连续存储的数组
# 模型推理, 得到模型输出
output = self.execute([img, ])[0]
# 后处理
boxout = nms(torch.tensor(output), conf_thres=0.4, iou_thres=0.5) # 利用非极大值抑制处理模型输出,conf_thres 为置信度阈值,iou_thres 为iou阈值
pred_all = boxout[0].numpy() # 转换为numpy数组
scale_coords([640, 640], pred_all[:, :4], img_bgr.shape, ratio_pad=(scale_ratio, pad_size)) # 将推理结果缩放到原始图片大小
img_dw = draw_bbox(pred_all, img_bgr, (0, 255, 0), 2, labels_dict) # 画出检测框、类别、概率
return img_dw整个流程就是:读图像,重整,推理,后处理,就这么简单。
那就好说了,在主程序中把模型换成自己的模型,修改输入长宽……等等,输入的模型是.om格式的?没见过啊?
赶紧在文档里翻了翻,看到了.om模型是Atlas平台的acl推理工具支持的输入模型。好在华为提供了官方的工具来将模型转换为.om模型。但蛋疼的是,这个模型支持caffee,tensorflow,onnx等等,却唯独不支持pytorch……
所以我们唯一的方法就是,将pytorch模型转换到onnx,再用Atlas平台的ATC工具,将onnx模型转换到om格式。
好在YOLO模型的仓库中都提供了export.py的脚本文件,可以将YOLO模型转换到ONNX格式输出,于是运行
python3 export.py当然,模型转换没这么容易成功。要不就是导出onnx不能成功,要不就是onnx转换om不能成功,要么就是转换都成功了推理输出不对。
这个时候,要仔细观察两边的代码。在yolo的推理代码中,可以看到,是先通过模型执行了推理,然后再进行了nms操作:
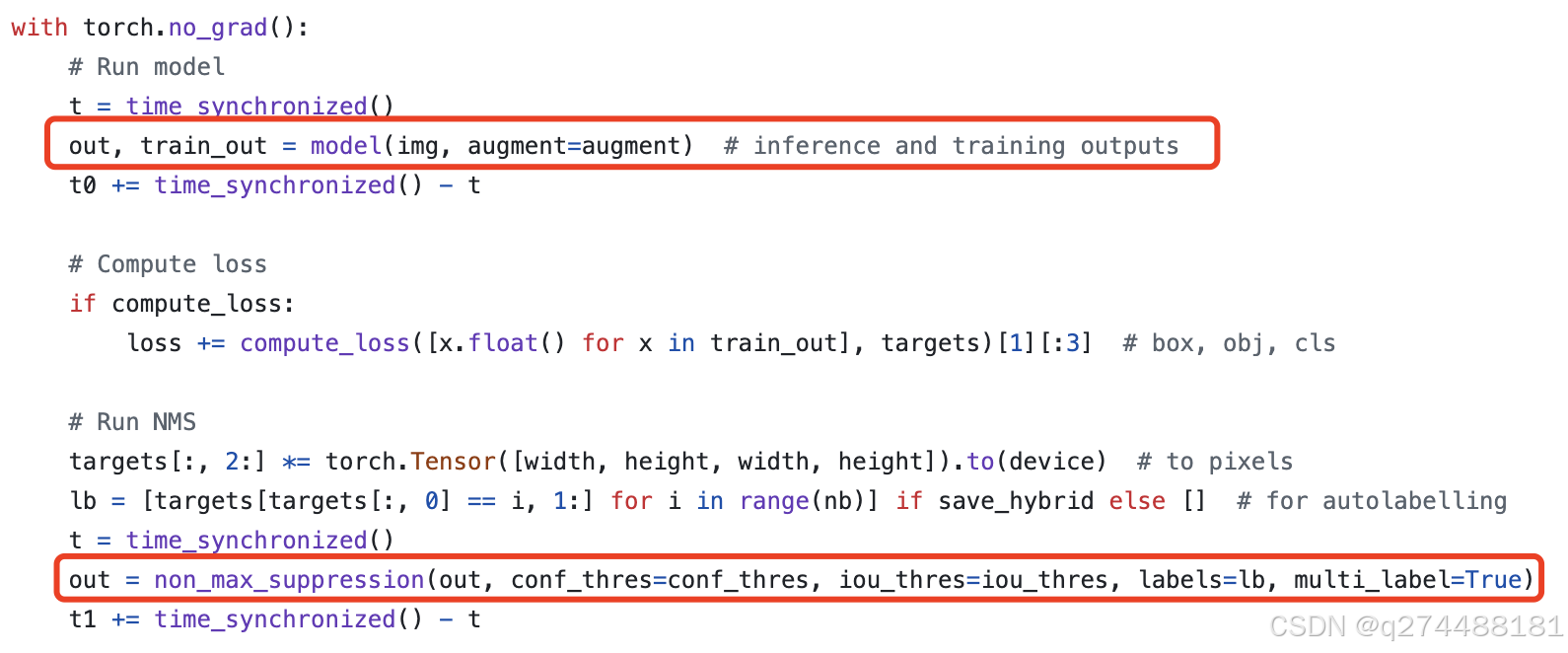
而在我们的sample中,也是这么个流程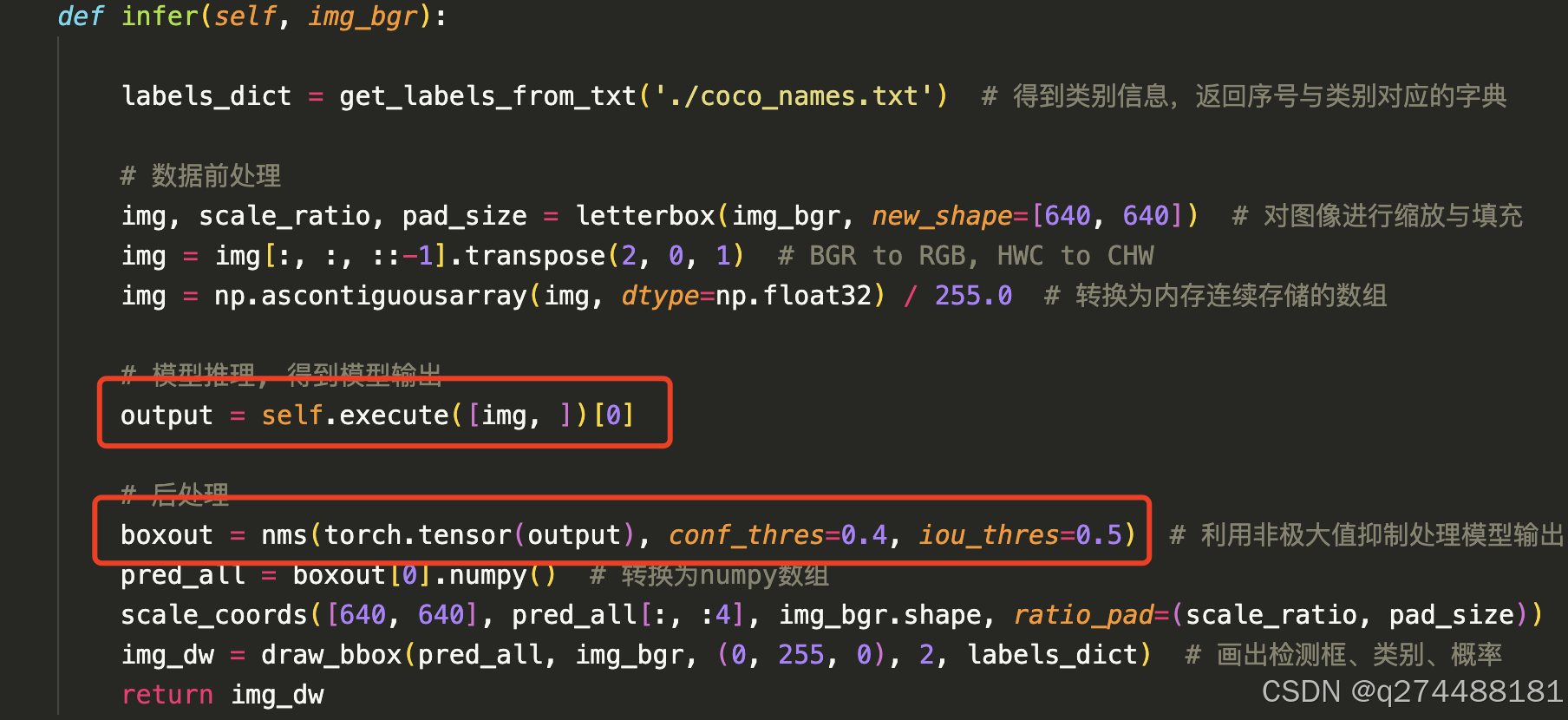
那我们只要保证模型的输出out和output的shape一致,基本上就对了。
通过对原模型的推理脚本设置断点,我们可以看到,out.shape=(batch, 25200, cls+5)
那么,我们要在export.py的脚本中,逐步去debug,要到在这个脚本找到,哪个步骤输出的tensor,是和上述形状一致的。
export.py脚本的输入参数非常多:

部分参数的说明也不太清楚,这里呢就是一个不断尝试的过程了。具体的方法就是在test.py脚本和export.py脚本中同时设置断点,要将test.py中的模型输出和export.py中的模型输出对齐。
上面说过,由于我们
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4015
4015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









