








阅读了 https://zhuanlan.zhihu.com/p/662406460
张小白不禁打开了这个链接:GitHub - Tlntin/Qwen-7B-Chat-TensorRT-LLM
看了下环境:

貌似不难满足:

记住:16G显存可以用int8。
docker已经有了:

先根据 https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
安装nvidia-docker
切换到root用户:
sudo su -

贴这么长一段命令:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list \
&& \
sudo apt-get update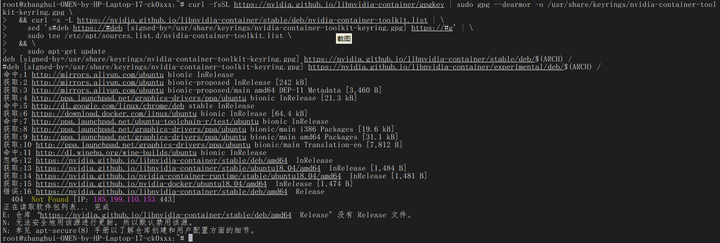
sudo apt-get install -y nvidia-container-toolkit

回到非root用户:
exit
cd ~
拉取项目代码:
git clone https://github.com/Tlntin/Qwen-7B-Chat-TensorRT-LLM.git -b release/0.5.0 cd Qwen-7B-Chat-TensorRT-LLM

编译docker镜像
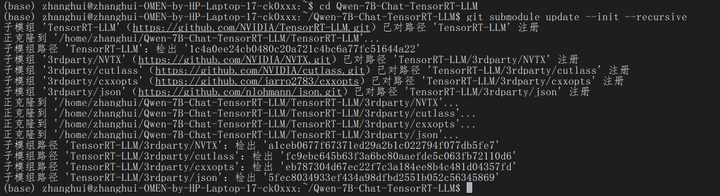
# 拉取TensorRT-LLM仓库 git submodule update --init --recursive
参考 急速安装git lfs_git lfs 安装_十寸清梦的博客-CSDN博客
安装Git的LFS版本:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
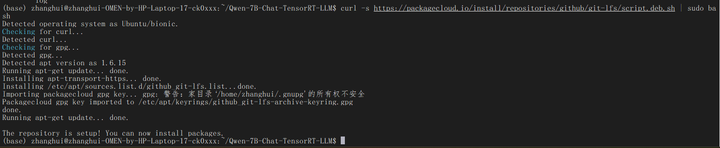
sudo apt-get install git-lfs
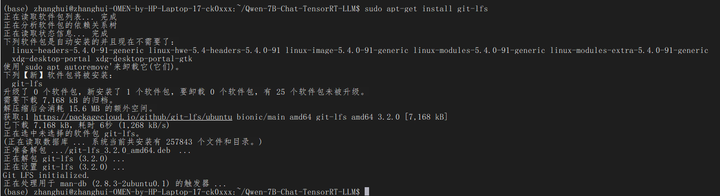
git lfs install

git lfs pull
这个步骤干了啥?(后来发现果然这步有问题)
# 编译docker cd TensorRT-LLM/docker make release_build
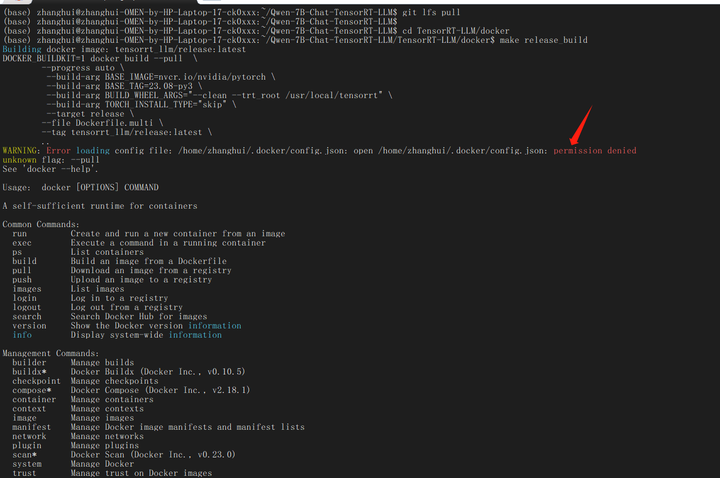
报权限错了,应该用root执行:
su
make release_build
网络不好的时候要重试几次。
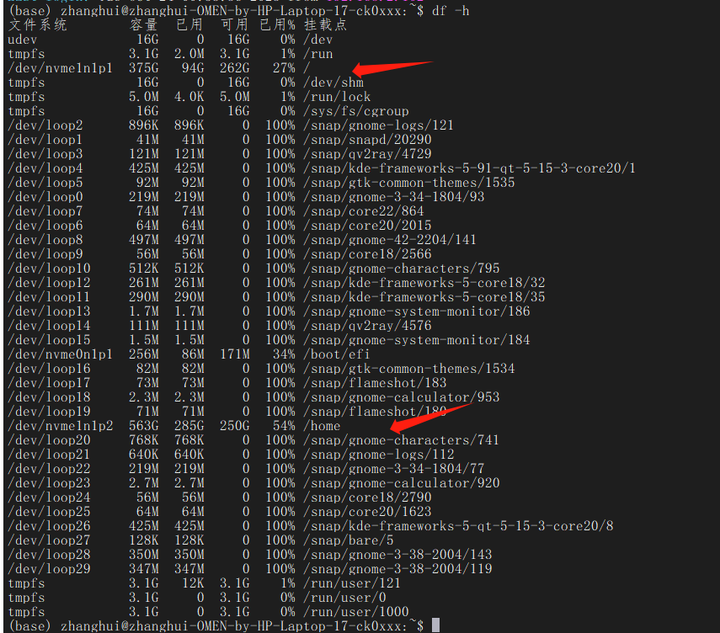
如何判断它还在下载?可以使用df看看剩余空间:


可以看到 / 的可用空间再不断的减少。。。
耐心等待到100%,然而并不是事事都能如愿:

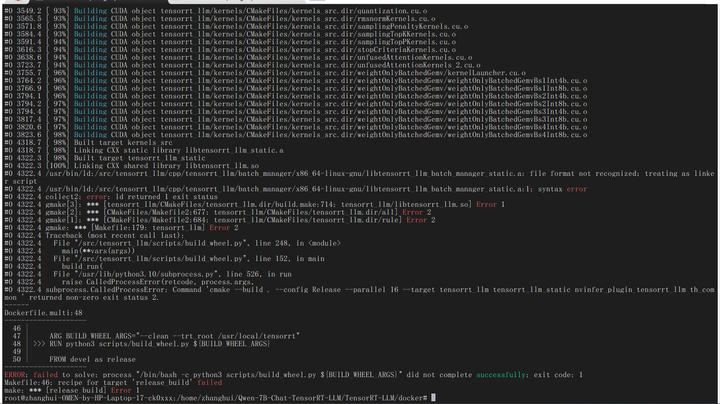
提了issue:镜像编译失败: · Issue #6 · Tlntin/Qwen-7B-Chat-TensorRT-LLM · GitHub
很快就得到了回复:应该是有几个文件不对。
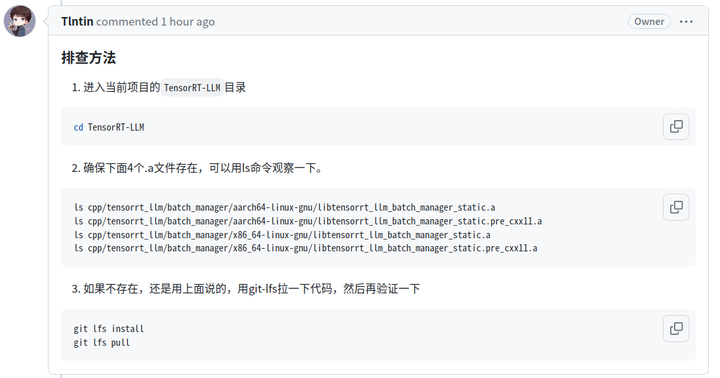
仔细比对了下,文件虽然都存在,但是大小不对:




文件应该是1点几兆,这里只有几百个字节。估计是前面git lfs安装异常,导致大文件没办法下载下来。
在没有修复git lfs 的情況下,直接从github下载文件,保存到相关目录:
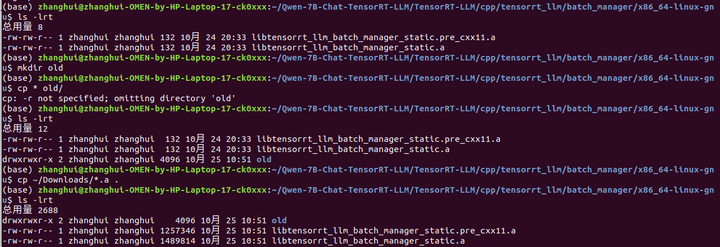
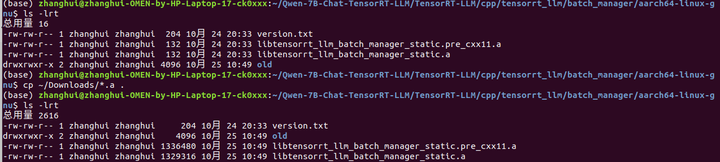
重新编译:
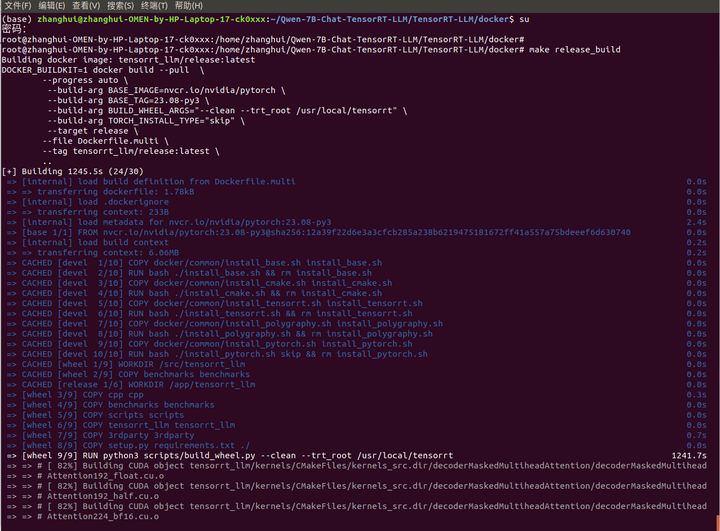
耐心等待编译结束。。。

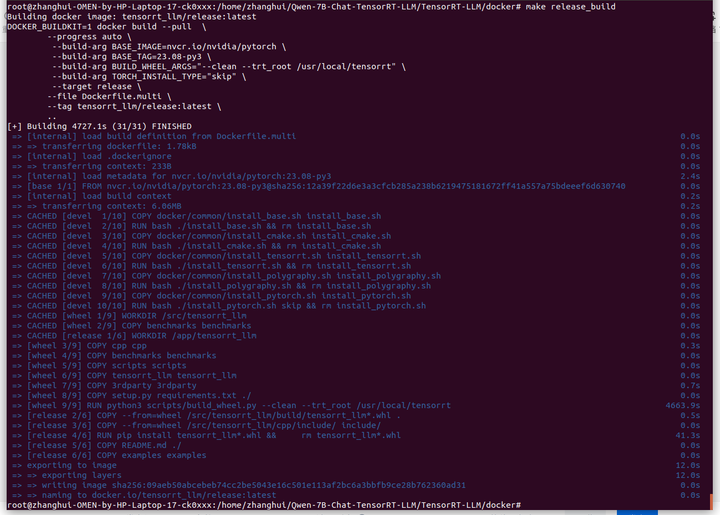
docker镜像编译完成。
使用docker images查看:

返回到项目路径 cd ../..
创建并启动容器,同时将本地qwen代码路径映射到/app/tensorrt_llm/examples/qwen路径
docker run --gpus all \
--name trt_llm \
-d \
--ipc=host \
--ulimit memlock=-1 \
--restart=always \
--ulimit stack=67108864 \
-v ${PWD}/qwen:/app/tensorrt_llm/examples/qwen \
tensorrt_llm/release sleep 8640000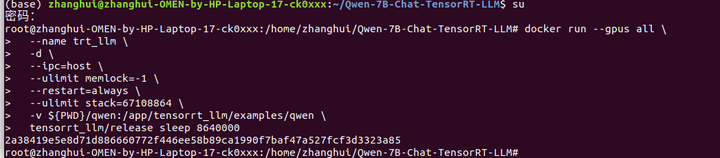
docker ps查看正在運行的docker容器:

將下載好的QWen-7B-Chat模型放到 qwen/路径下:
張小白採用了以下方法:先把QWen-7B-Chat模型拷貝到移動硬盤上,然後接入到ubuntu上,
sudo fdisk -l查看是哪塊盤:

使用root執行:

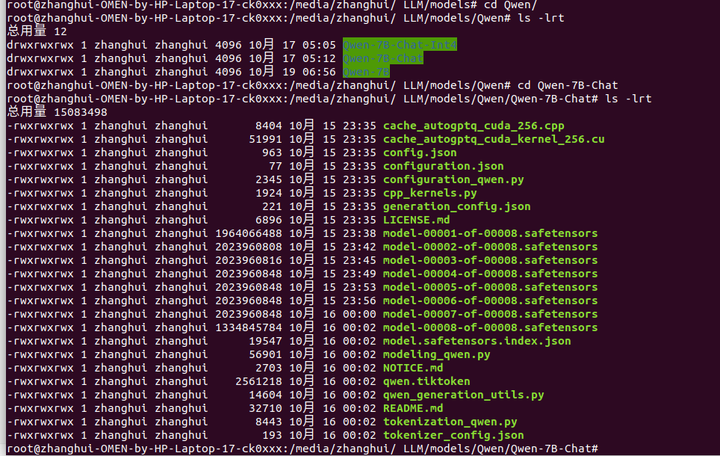
cd /home/zhanghui/Qwen-7B-Chat-TensorRT-LLM/qwen
cp -r "/media/zhanghui/ LLM/models/Qwen/Qwen-7B-Chat" Qwen-7B-Chat
chown -R zhanghui:zhanghui Qwen-7B-Chat

进入docker容器里面的qwen路径,安装提供的Python依赖
docker ps
root@zhanghui-OMEN-by-HP-Laptop-17-ck0xxx:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2a38419e5e8d tensorrt_llm/release "/opt/nvidia/nvidia_…" 23 minutes ago Up 23 minutes 6006/tcp, 8888/tcp trt_llmdocker exec -it 2a38419e5e8d /bin/bash

cd /app/tensorrt_llm/examples/qwen/

pip install -r requirements.txt
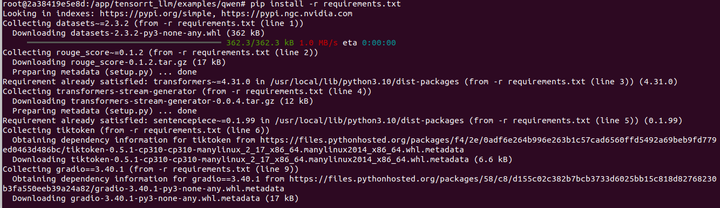
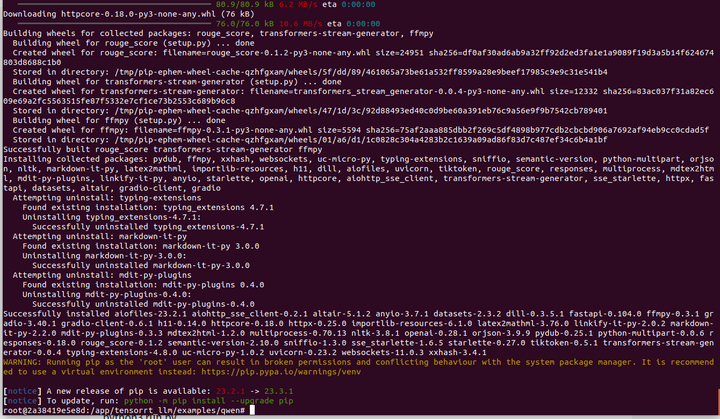
改一下目錄名稱
mv Qwen-7B-Chat qwen_7b_chat
修改编译参数
默认编译参数,包括batch_size, max_input_len, max_new_tokens, seq_length都存放在default_config.py中
vi default_config.py
max_batch_size=1
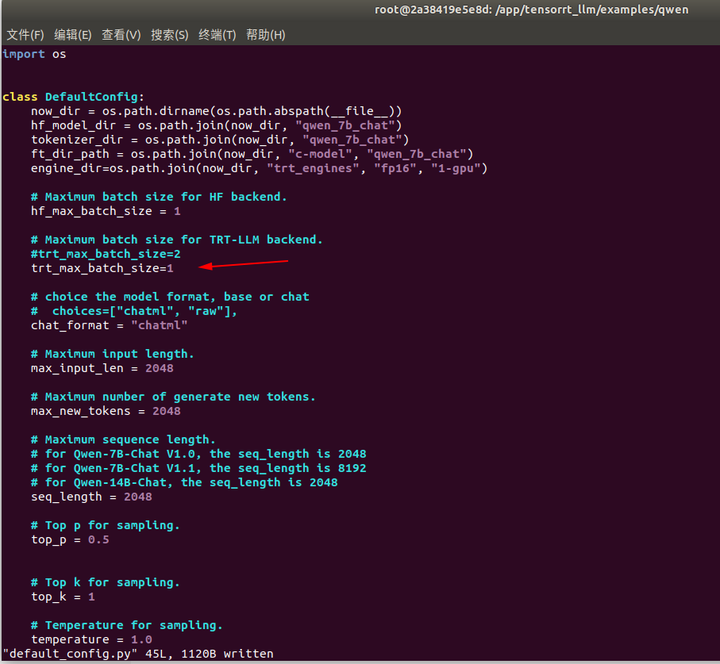
对于16G显存用户,可以试试int8 (weight only)
python3 build.py --use_weight_only --weight_only_precision=int8
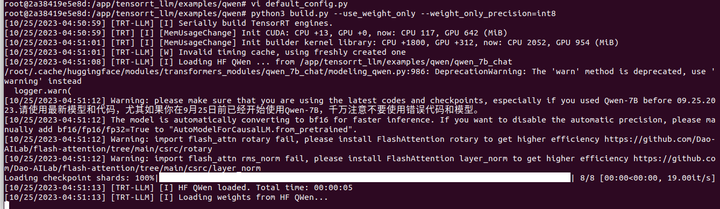
好像有點問題,它不会在连HF吧?
先保存下鏡像:
docker commit 2a38419e5e8d qwen-tensorrt-llm:v20231025
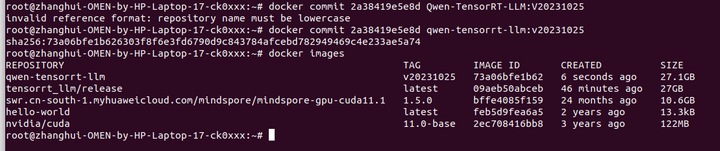
因爲張小白要重啓下電腦。
打开新的镜像,这样就不需要重新在镜像里面重装依赖包了。
cd /home/zhanghui/Qwen-7B-Chat-TensorRT-LLM/qwen

su 切换到root
删除前面所有的容器
docker stop 2a38419e5e8d
docker rm 2a38419e5e8d
docker stop 267281c60965
docker rm 267281c60965
cd /home/zhanghui/Qwen-7B-Chat-TensorRT-LLM
docker run --gpus all \
--name trt_llm_20231025 \
-d \
--ipc=host \
--ulimit memlock=-1 \
--restart=always \
--ulimit stack=67108864 \
-p 8000:8000 \
-p 7860:7860 \
-v ${PWD}/qwen:/app/tensorrt_llm/examples/qwen \
qwen-tensorrt-llm:v20231025 sleep 8640000docker ps
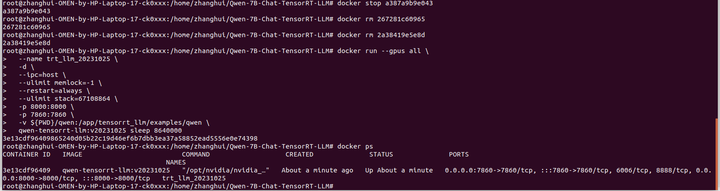
进入新的容器:
docker exec -it 42687772b437 /bin/bash
cd /app/tensorrt_llm/examples/qwen/
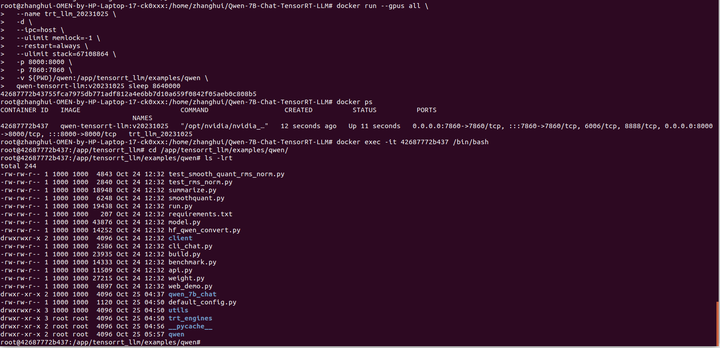
python3 build.py --use_weight_only --weight_only_precision=int8
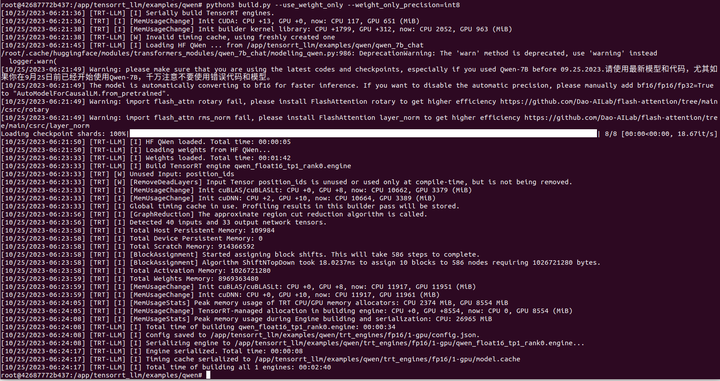
编译完成,试跑一下:
python3 run.py
如果输出Output: "您好,我是来自达摩院的大规模语言模型,我叫通义千问。<|im_end|>"说明成功

尝试终端对话
python3 cli_chat.py

可能输入了什么不可见字符。
再试一次:
python3 cli_chat.py
树上10只鸟,打死一只,还剩几只?
剩下的鸟不会跑吗?
那么,树上10只鸟,打死一只,到底还剩几只?
你怎么不知道变通呢?
你这个模型是怎么训练出来的?
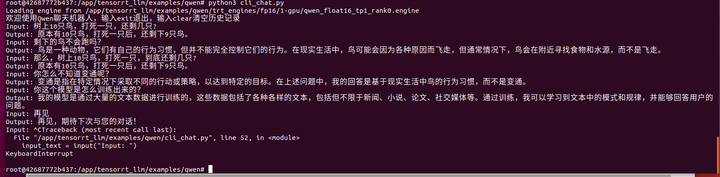
言尽于此。。。老千,你耗子尾汁。
部署api,并调用api进行对话
python3 api.py

另开一个终端,进入qwen/client目录
cd ~/Qwen-7B-Chat-TensorRT-LLM/qwen/client
执行以下四种方式中的任意一种:
-
async_client.py,通过异步的方式调用api,通过SSE协议来支持流式输出。
-
normal_client.py,通过同步的方式调用api,为常规的HTTP协议,Post请求,不支持流式输出,请求一次需要等模型生成完所有文字后,才能返回。
-
openai_normal_client.py,通过openai模块直接调用自己部署的api,该示例为非流式调用,请求一次需要等模型生成完所有文字后,才能返回。。
-
openai_stream_client.py,通过openai模块直接调用自己部署的api,该示例为流式调用。
另外一个新的终端,在容器外面调用:
python normal_client.py
写一首赞美祖国的诗


好像没啥问题。其他的暂时不试了。
最后,尝试网页对话,回到容器里面:
将web_demo.py最后一行改为:
demo.queue().launch(server_name="0.0.0.0", share=False, inbrowser=False)

运行
python3 web_demo.py
浏览器打开 127.0.0.1:7860
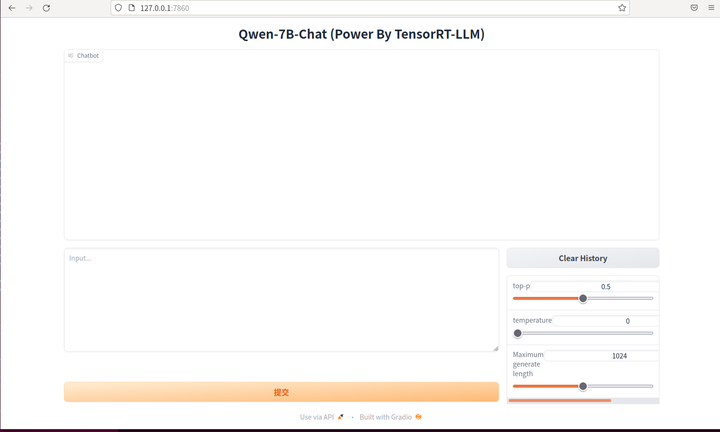
这个很熟悉的界面,我们再玩玩:
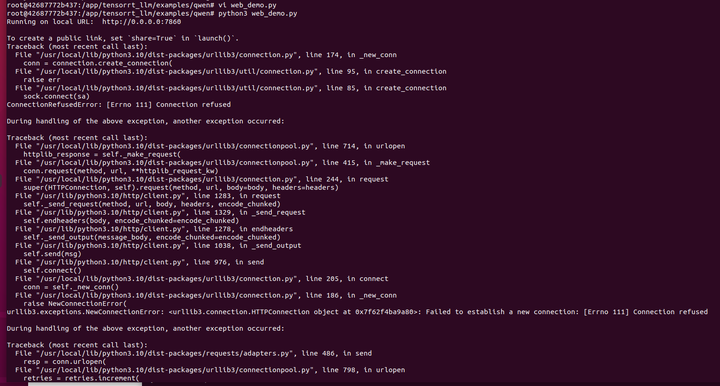
貌似要连后台服务?难道前面的命令不能停?
打开新的终端进入容器
docker exec -it 42687772b437 /bin/bash
cd /app/tensorrt_llm/examples/qwen/

执行:
python3 api.py

切回到浏览器,继续聊!

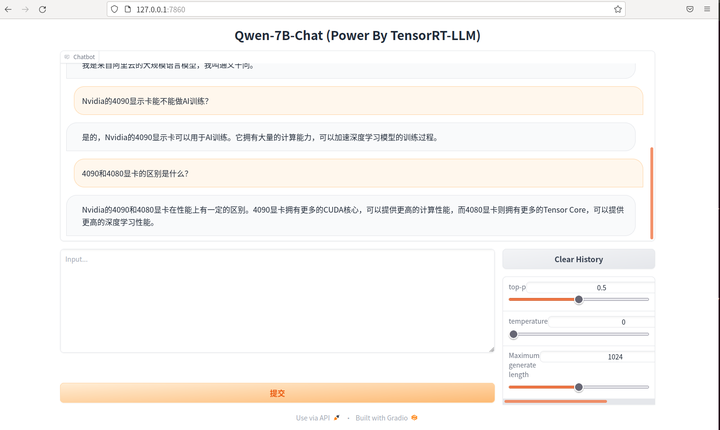
好了,这次体验 TensorRT-LLM+通义千问 的过程差不多了。让我们期待下一次的体验。
BTW:对了,目前的容器要保存成镜像。
docker commit 42687772b437 qwen-tensorrt-llm:v20231025_02
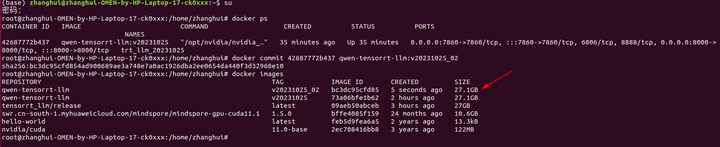
(全文完,谢谢阅读)
















 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











