







目录
2.5 将Excel/csv文件转换为Pandas DataFrame
1、DataFrame和Series
1.1 什么是DataFrame?
DataFrame:一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
1.2 什么是Series?
Series 是一个一维数组对象 ,类似于 NumPy 的一维 array。它除了包含一组数据还包含一组索引,所以可以把它理解为一组带索引的数组。
2、DataFrame的创建
2.1 创建空的Dataframe
df = pd.DataFrame(columns=['A', 'B', 'C'], index=[0,1,2])columns参数用来定义列名,index参数用来定义行号。上面的代码创建了一个3行3列的二维数据表,结果看起来是这样:
嗯,所有数据项都是NaN。
2.2 字典类型→DataFrame
方法1:直接使用pd.DataFrame(data=test_dict),具体如下:
import pandas as pd
# 用传入等长列表组成的字典来创建(用DataFrame自带索引) 自带列名
test_dict = {
'id':[1,2,3,4,5,6],
'name':['Alice','Bob',
'Cindy','Eric','Helen','Grace '],
'math':[90,89,99,78,97,93],
'english':[89,94,80,94,94,90]
}
test_dict_df = pd.DataFrame(test_dict)
# 传入嵌套字典(字典的值也是字典)创建DataFrame (使用字典内嵌索引) 自带列名
nest_dict = {
'shanghai': {2015: 100, 2016: 101},
'beijing': {2015: 102, 2016: 103}}
test_dict_df2 = pd.DataFrame(nest_dict)
就得到了一个DataFrame,如下


方法2:使用from_dict方法:
test_dict_df = pd.DataFrame.from_dict(test_dict)2.3 列表类型→DataFrame
import pandas as pd
test_list = [[1,2,3],['a','b','c']]
test_list_df = pd.DataFrame(test_list)其结果如下:

2.4 用numpy中的array生成→DataFrame
import numpy as np
import pandas as pd
data_arr = np.arange(15).reshape(3,5)
data_arr_df = pd.DataFrame (data_arr)
2.5 将Excel/csv文件转换为Pandas DataFrame
如读取“excel.xlsx" 文件 ,那么可以使用下面的代码将其转换为Pandas DataFrame:
import pandas as pd
# 文件路径
excel_path = r'E:\users\xuebf\Desktop\excel.xlsx'
csv_path = r'E:\users\xuebf\Desktop\csv.csv'
excel_df = pd.read_excel(excel_path) # 读取excel文件
csv_df = pd.read_csv(excel_path) # 读取csv文件
另外读取excel或者csv文件有时候注意编码格式,可以指定encoding参数。否则容易出现乱码。
3、DataFrame取值:
| 取值内容 | 使用值属性 | |
| data['w'] | 选择表格中的'w'列,使用类字典属性 | 返回的是Series类型,多列不能采用此种方法 |
| data.w | 选择表格中的'w'列,使用点属性 | 返回的是Series类型 |
| data[['w']] | 选择表格中的'w'列 | 返回的是DataFrame属性 |
| data[['w','z']] | 选择表格中的'w'、'z'列 | 返回的是DataFrame属性 |
| data[0:2] | 返回第1行到第2行的所有行,前闭后开 | 返回的是DataFrame属性 |
| data[1:2] | 返回第2行,从0开始计,返回的是单行,通过有前后值的索引形式 | 返回的是DataFrame属性 |
| data.ix[1:2] | 返回第2行的第三种方法 | 返回的是DataFrame属性 |
| data['a':'b'] | 利用index值进行切片,前闭后闭 | 返回的是DataFrame属性 |
| data.head() | 取data的前几行数据,默认为前五行 | 返回的是DataFrame属性 |
| data.tail() | 取data的后几行数据,默认为后五行 | 返回的是DataFrame属性 |
| data.iloc[-1] | 选取DataFrame最后一行 | 返回的是Series类型 |
| data.iloc[-1:] | 选取DataFrame最后一行 | 返回的是DataFrame |
| data.iloc[:,-1] | 选取DataFrame最后一列 | 返回的是Series类型 |
| data.iloc[:,[-1]] | 选取Dataframe最后一列 | 返回的是DataFrame属性 |
| data.iloc[-1,-1] | 选取DataFrame最后一行最后一列 | 返回的是str或数字 |
| data.loc['a',['w','x']] | 返回‘a’行'w'、'x'列 | 返回的是DataFrame属性 |
| data.iat[1,1] | 取第二行第二列,用于已知行、列位置的选取 | 返回的是str或数字 |
4、区别.loc[[i]]与iloc[[i]]:
.loc[[i]]与iloc[[i]]都是选取某一行的数据,loc按照标签进行索引,iloc按照位置进行索引。 loc[1]和iloc[1]取出data的第二行的数据,返回的结果是Series类型。
以excel_df举例如下:为了便于说明修改excel_df的索引为全整数
4.1 loc:
在index的标签上进行索引(即是在index上寻找相应的标签,不是下标),范围包括start和end。
# 重新定义excel_df的行索引
re_index = [-5,1,3,0,10,11,16,18,5,19,21,23,28]
excel_df.index = re_index
excel_df_loc = excel_df.loc[:10]修改过索引之后的excel_df


即是在excel_df的index上寻找相应的标签为10的index,返回结果包含开始和结尾的部分。
excel_df.loc[1:10]在excel_df的index寻找开始标签为1,结束标签为10的index,返回结果包含开始和结尾的部分。
4.2 iloc:
在index的位置上进行索引(即是按照普通的下标寻找),不包括end.
excel_df_iloc = excel_df.iloc[:10]
excel_df.iloc[:10]即是在excel_df.从下标0开始进行位置的索引,返回不包括下标为10的标签。
4.3 ix
先在index的标签上索引,索引不到就在index的位置上索引(如果index非全整数),不包括end。
修改excel_df的索引为非全整数
re_index=[-5,1,3,0,10,'c','g','r','o','i','k','u','t']
excel_df.index = re_index
excel_df_ix = excel_df.ix[:9]
excel_df.ix[:9] # 这里不会报错,因为index的标签是非全整数,但是不建议这样使用,
会有这样的警告FutureWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
See the documentation here:
http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#ix-indexer-is-deprecated
4.4 iat[,]
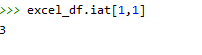
返回某一个单元格的值,用于已知行、列位置的选取。
如excel.iat[1,1]取第二行第二列的值,返回3
以上是个人对DataFrame的理解之总结,欢迎有不同方法见解评论、交流。
它山之石,可以攻玉;
良知之学,知行合一。















 5511
5511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









