







政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
目录
本篇我们将借助DiffRhythm 是一种基于潜扩散模型(Latent Diffusion Model)的AI音乐生成技术,基于ComfyUI工作流生成原创音乐。
DiffRhythm以其快速生成完整歌曲(最长4分45秒,仅需不到10秒)而著称。现在,我们就借助ComfyUI 强大的开源节点式界面,通过插件扩展支持音乐生成。两者融合的最新成果是 ComfyUI_DiffRhythm,它将 DiffRhythm 的音乐生成能力集成到 ComfyUI 的工作流中,提供灵活的参数调整和可视化操作体验。
开启ComfyUI
我们的ComfyUI是在Ubuntu系统中的,不会安装的小伙伴查看我以前的文章。
硬件配置我就不推荐了,玩了这么长时间AI的小伙伴都懂的。
最低配置:NVIDIA GPU(至少 4GB VRAM),支持 CUDA;或 CPU(速度较慢)。
推荐配置:8GB+ VRAM GPU,以支持完整歌曲生成和高保真输出。
安装ComfyUI_DiffRhythm 插件
这是一个快速而简单的端到端全长歌曲生成的DiffRhythm 的 ComfyUI 节点。
项目地址:
cd ComfyUI/custom_nodes
git clone git@github.com:billwuhao/ComfyUI_DiffRhythm.git
项目下载需要等待一些时间。

进入插件目录准备安装依赖:
cd ComfyUI_DiffRhythm
启动comfyui虚拟环境:

pip install -r requirements.txt 
需要一些时间:

启动工作流
安装完成后,启动comfyUI并加载工作流(该插件在第一次运行时会自动加载模型,如果失败,我们再尝试手动下载):
python main.py --listen 0.0.0.0 --port 8188注意:
启动comfy工作流的时候,需要在comfyUI项目根目录执行命令
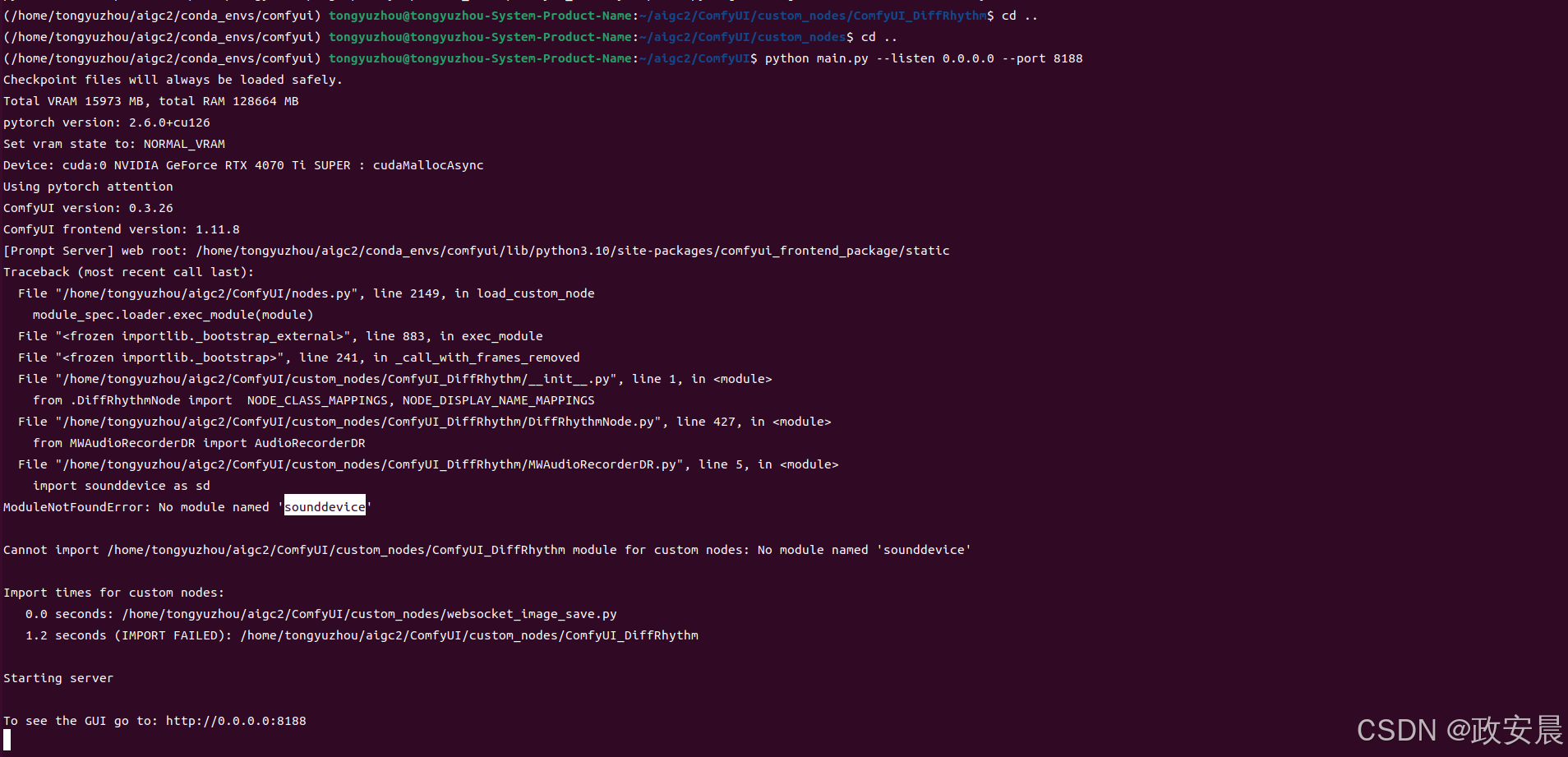
启动时,该插件报了一些错,我们先手动装一个模型,再告诉大家为什么错。
手动下载:
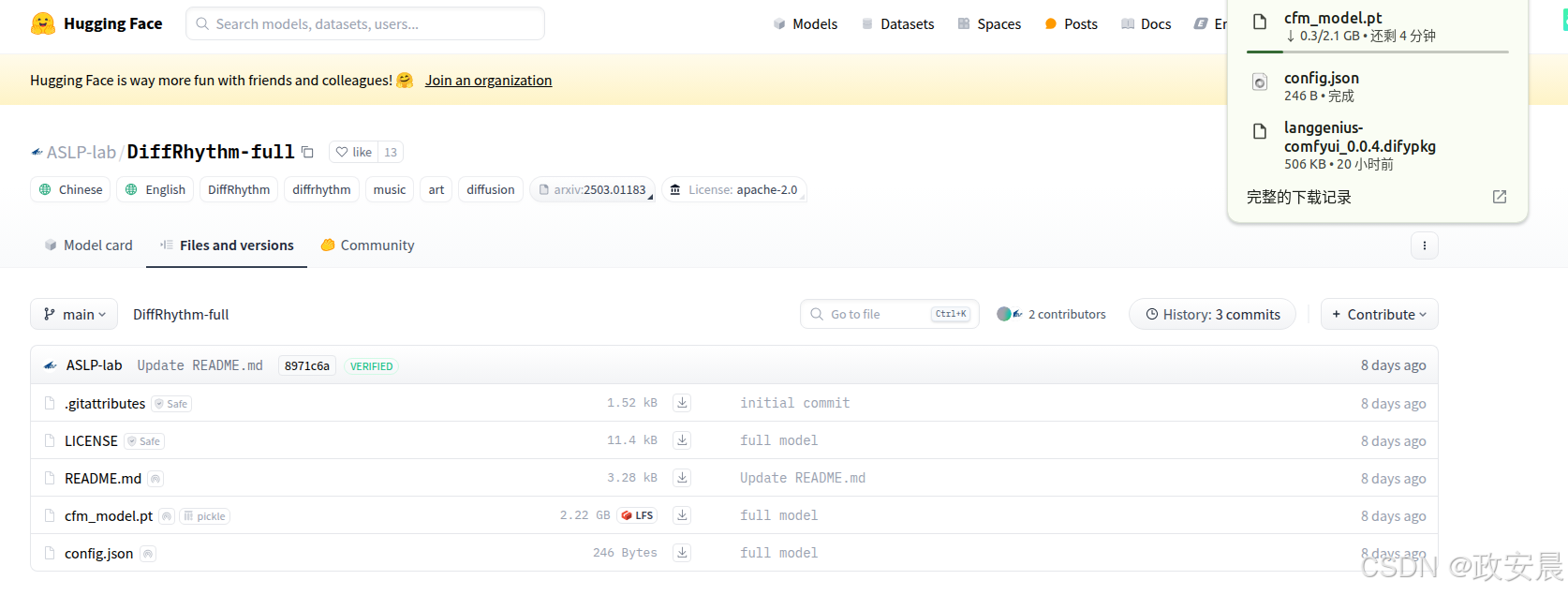
下载模型放到 ComfyUI\models\TTS\DiffRhythm 文件夹下:
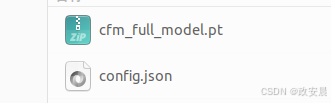
- DiffRhythm-full 模型重命名为
cfm_full_model.pt, 同时下载 comfig.json 放到一起.
这里有个小坑,在ubuntu系统中,需要手动安装Portaudio库来进行音频处理:
sudo apt update
sudo apt -y install libportaudio2
安装完库之后,再次启动comfyUI,你会发现一切都安静了,不会报错:
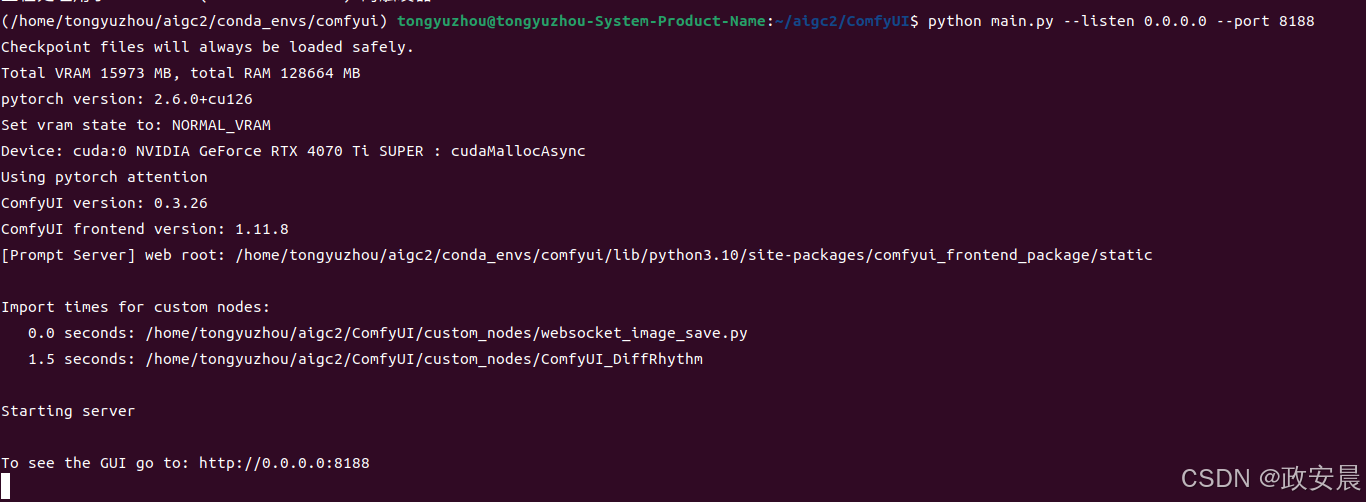
节点出来啦
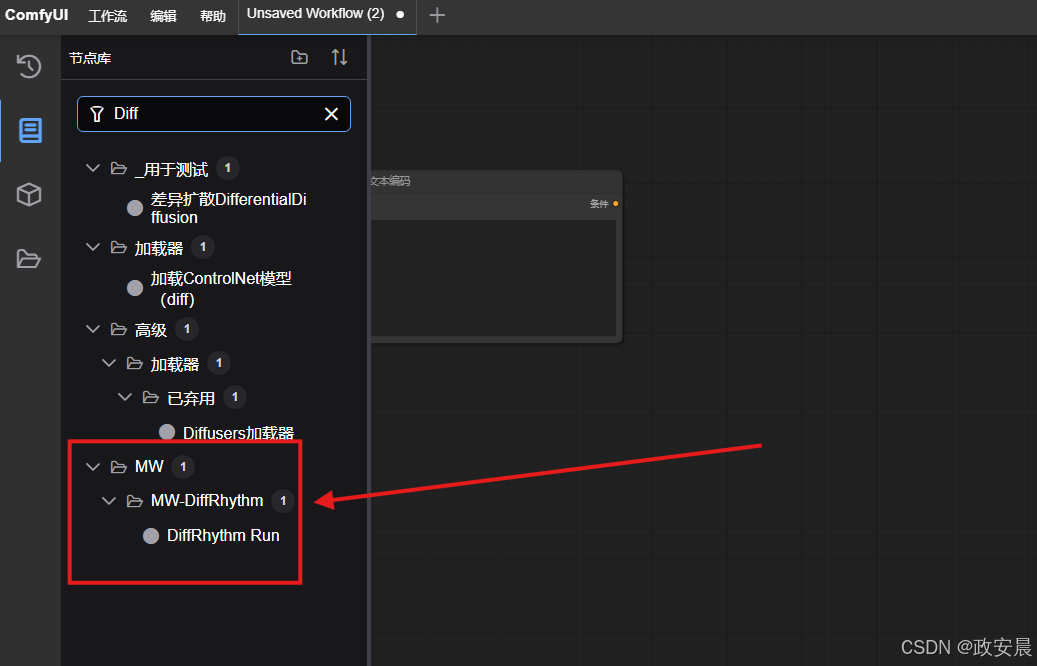
应用插件
安装辅助插件
其实想要顺利使用这个插件,咱们还要安装一个辅助插件:
cd custom_nodes
git clone git@github.com:WASasquatch/was-node-suite-comfyui.git
cd was-node-suite-comfyui
pip install -r requirements.txt我把我的操作过程贴出来,大家用的时候分别执行:
(我写博客都会累吐血,因为太实在了,手把手为大家实现,嘻嘻。)

你可以看到我的安装成功,重启comfyUI。
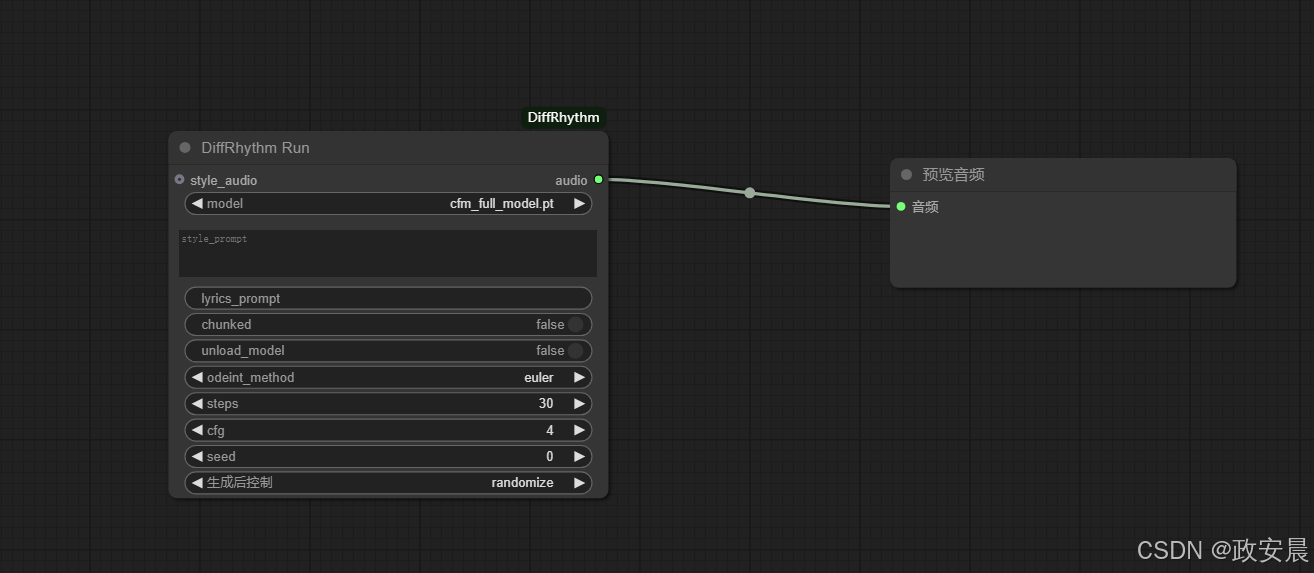
工作流完成
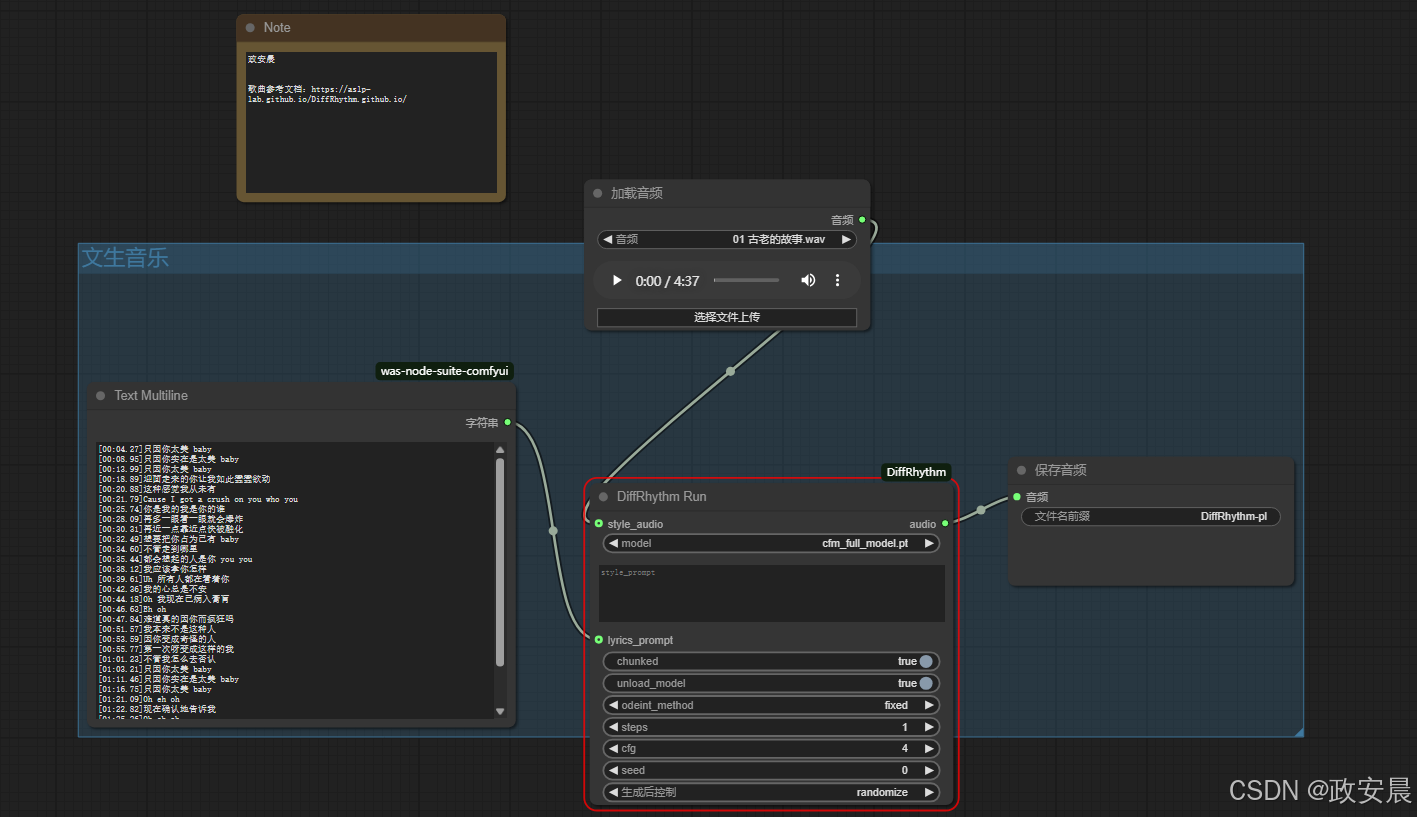
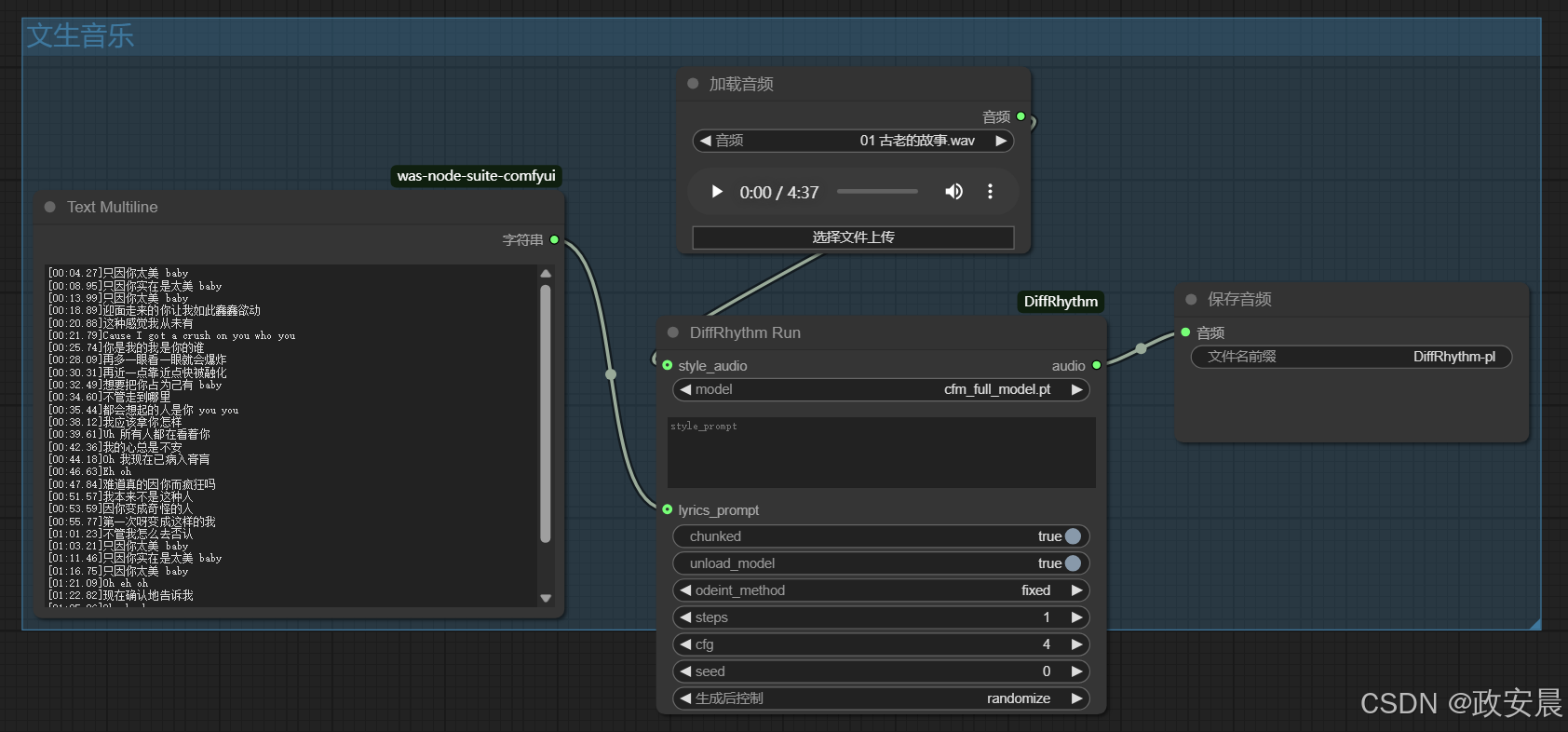
放大一点:
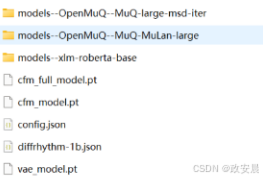
如果无法运行成功的话,请检查一下你的模型存在的位置(类似这样):
就到这里吧,祝大家玩得开心,都可以创造出自己喜欢的歌曲世界!



















 2013
2013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











