







拒绝繁琐概念 | 零基础基于pytorch手写一个神经网络
零基础小白在学习完基础的python语法,想入门深度学习,机器学习等人工智能领域,常常会因为网上一搜就是几十个小时的课程和一堆几千几万字的繁琐概念而望而却步。本文抛开这些复杂的概念,从程序入手,带你跑通一个简单的手写数字识别的项目来快速入门pytorch。
什么是pytorch?
PYTORCH框架是一个机器学习工具,具有上手快、代码简洁的特点。与其他框架相比,它更符合人类思维,使得机器学习任务的实现变得简单。
说人话:一个让我们干活更简单的工具。
数据集用什么?

在项目中使用MINNEST手写数字数据集,它包含7万张图片,训练集6万张,测试集1万张。训练集用于调整神经网络参数,而测试集则评估网络的性能。
说人话:采用公开的一个数据集来训练我们项目对手写数字的精确识别能力。
怎么用数据集来训练?
这里以单个的一张手写的数字“7”来举例,先讲理论实现,再讲代码实现,不要看到理论就害怕,实际实现非常简单。
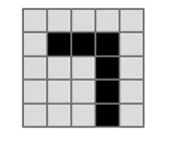
假设我们有一个5×5像素的图片(手写数字7),如何设计神经网络识别这个信息呢?
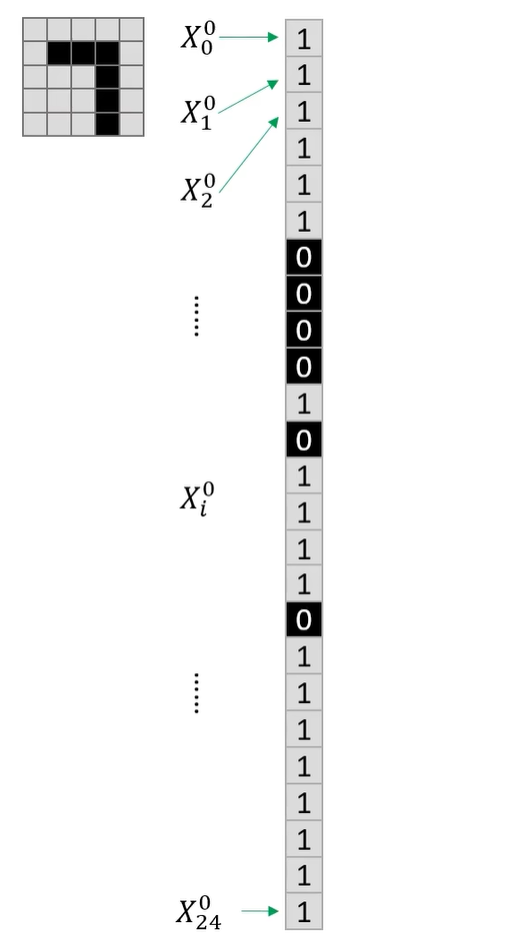
首先我们把这25个像素如图重新排列成一维,黑色的是0,白色的是1,同时按照图中方式进行编号(注意从0开始)。
这样我们就构成了神经网络的第0层信息(X的上角标)。

接着我们神经网络第一层节点(如图中四个黑点),这一层的节点值是由上一层的节点值计算得到的,如图中节点计算公式,至于a,b参数,我们稍后再谈。(这里公式看不懂没关系,知道“这一层的节点值是由上一层的节点值计算得到的”就行)
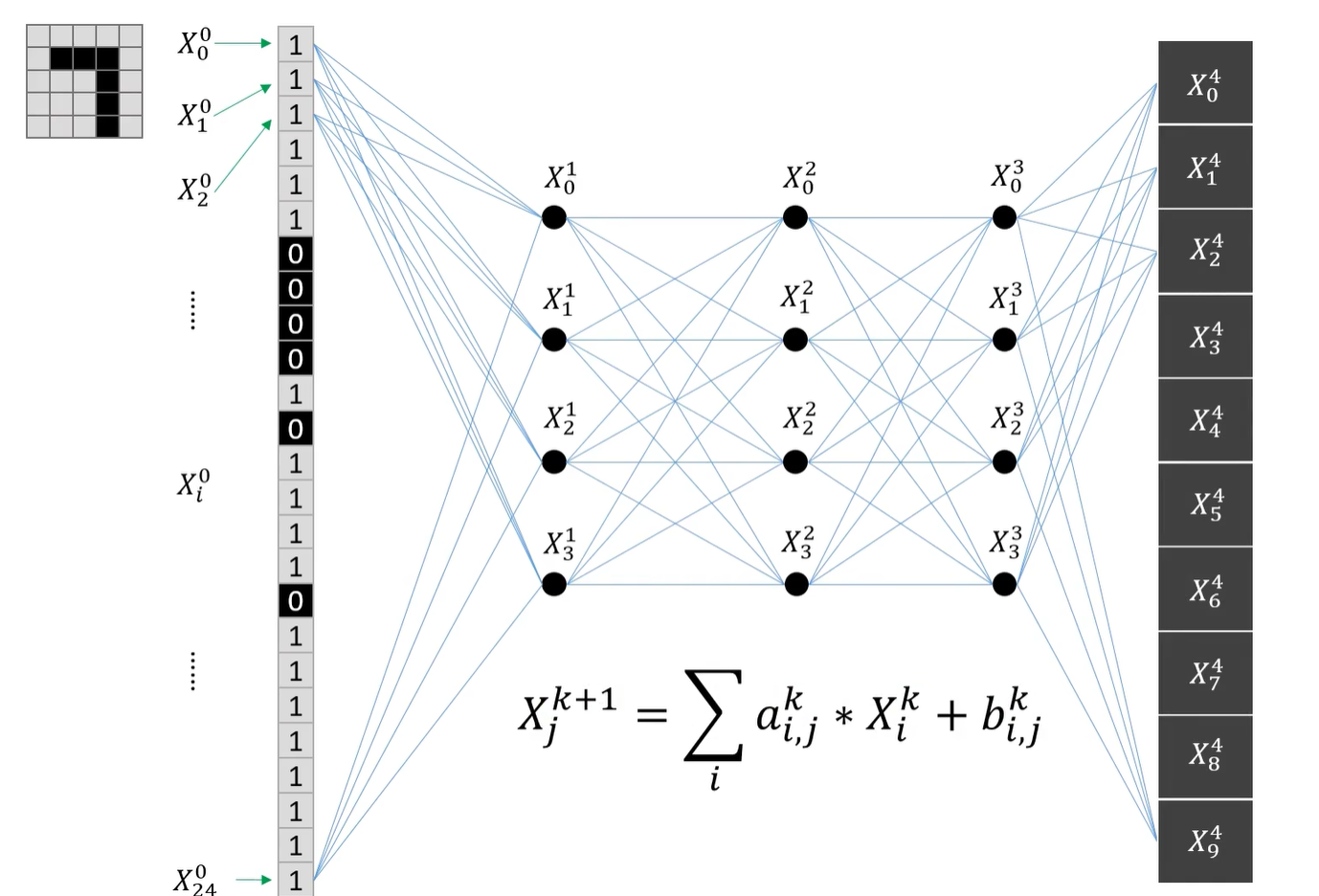
同理,我们可以这样计算出神经网络接下来每层的节点,但要注意,我们要在最后一层节点输出结果。
这里我们的项目是用于识别数字,那么对于单个数字,它只可能有0到9这10种可能,我们也就有10个节点。具体的值就是每个数的P(概率)。
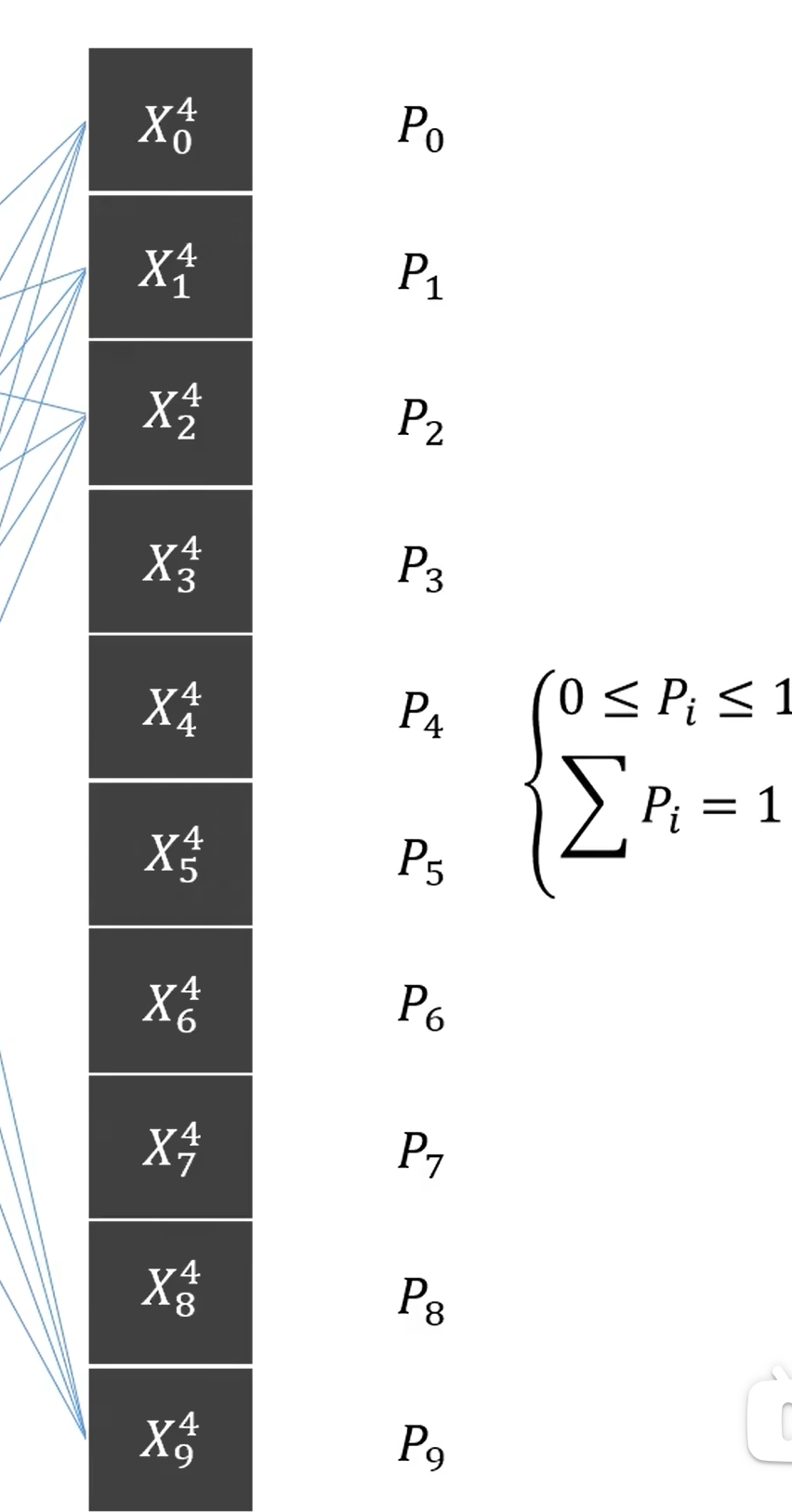
总结:神经网络的设计基于将图片像素重新排列为一维阵列。通过计算不同层节点的数值,神经网络能够有效识别和处理图像信息,实现数字识别的功能。
补充:为了使得P都为正数并且和为1,我们会对其做归一化处理。

总结:神经网络的层数和节点传播公式是设计网络结构的基础,节点通过公式传播信息,最终到达输出层以进行分类。每个节点的数值表示特定类别的概率。在输出层中,节点的值需要经过数学变换才能满足概率的特性。通过soft max归一化处理,可以确保节点的值大于零且小于一,并且所有节点的总和为一。
接下来呢?
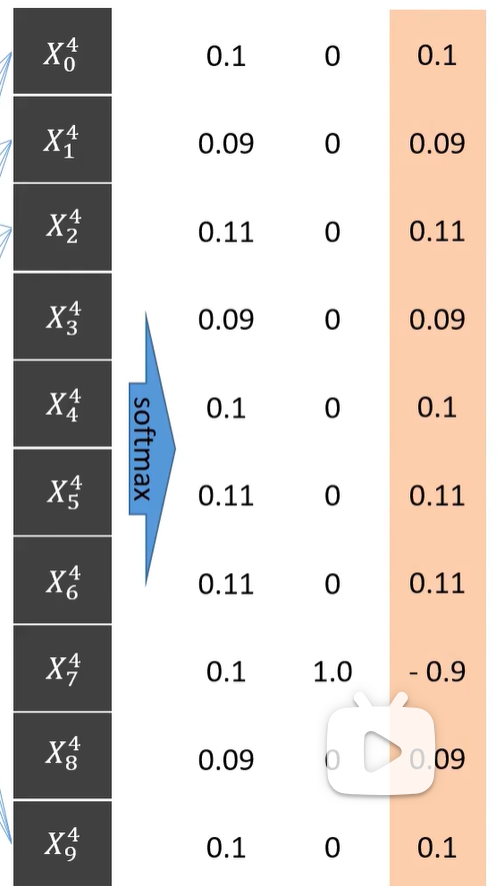
训练!我们构建了一个基础的神经网络,但是这样的识别很可能是随机且不准确的,为了提高准确率,我们就需要大量训练,还记得前面公式的a,b参数吗?我们需要根据每次训练输出的概率结果来与实际情况做比较(如图),来调整ab的值,重复这个过程很多次,从而达到目的。(当然,实际过程中我们会调整每次输入的图片的数量,将几张图片打包成一个批次进行处理。这样可以在训练过程中更快地调整网络参数,提升整体训练速度。)
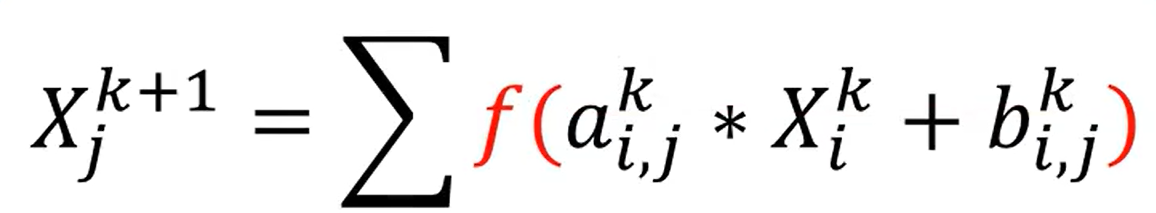
同时有些时候,对于原来公式,我们怎么调整都不会使ab的值达到预期效果,就需要在外面套一个f函数了,我们称作“激活函数”。
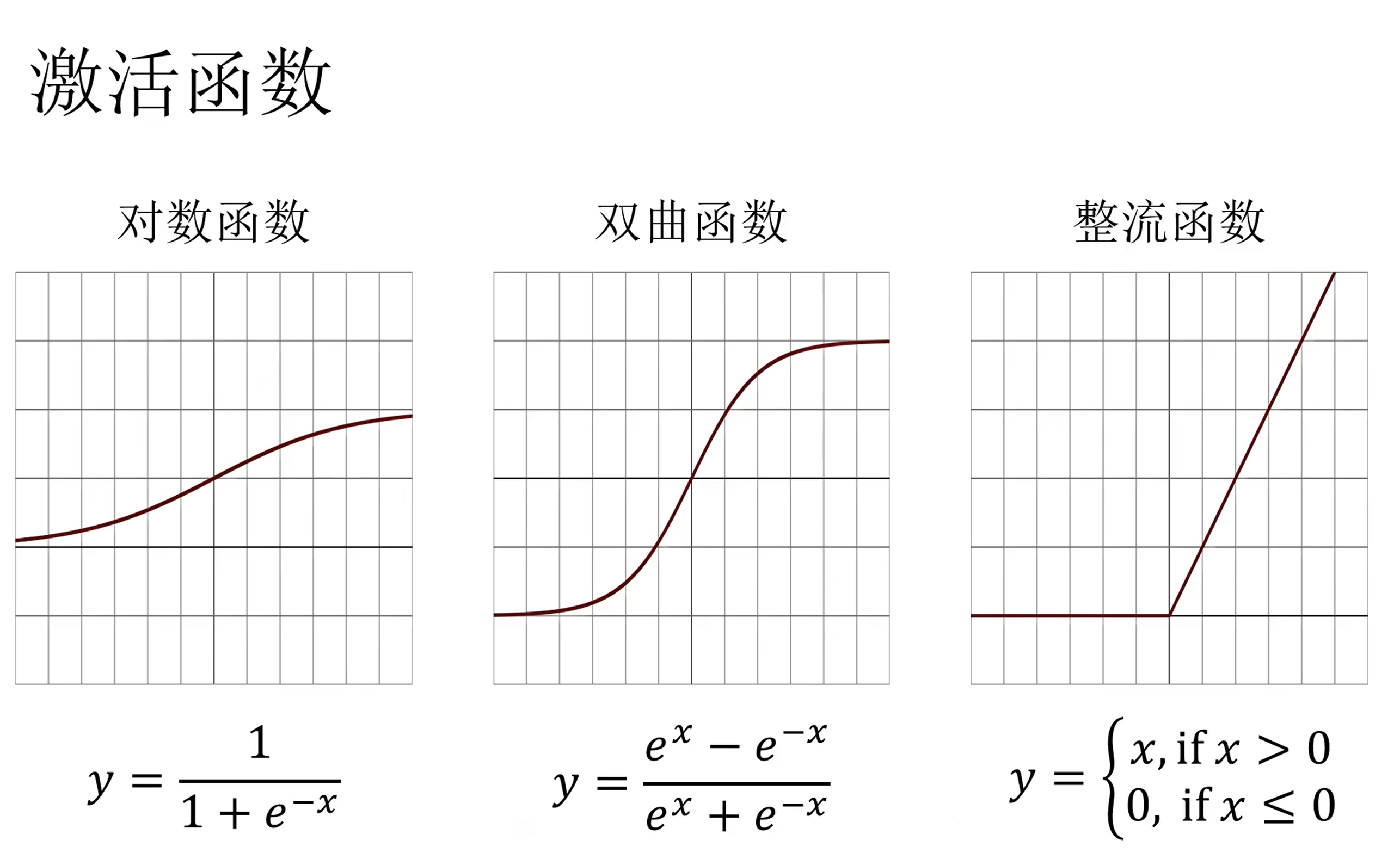
常见的激活函数如图所示。
该到代码讲解了吧?
首先我们需要将项目跑起来,调出你的cmd,运行
pip install numpy torch torchvision matplotlib
来下载必要依赖。
(当然,使用虚拟环境是更好的方案,推荐conda,要比venv稳定,但考虑到阅读文章的人可能比较小白,我们选择直接跑)
然后创建test.py文件,代码如下
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc1 = torch.nn.Linear(28*28, 64)
self.fc2 = torch.nn.Linear(64, 64)
self.fc3 = torch.nn.Linear(64, 64)
self.fc4 = torch.nn.Linear(64, 10)
def forward(self, x):
x = torch.nn.functional.relu(self.fc1(x))
x = torch.nn.functional.relu(self.fc2(x))
x = torch.nn.functional.relu(self.fc3(x))
x = torch.nn.functional.log_softmax(self.fc4(x), dim=1)
return x
def get_data_loader(is_train):
to_tensor = transforms.Compose([transforms.ToTensor()])
data_set = MNIST("", is_train, transform=to_tensor, download=True)
return DataLoader(data_set, batch_size=15, shuffle=True)
def evaluate(test_data, net):
n_correct = 0
n_total = 0
with torch.no_grad():
for (x, y) in test_data:
outputs = net.forward(x.view(-1, 28*28))
for i, output in enumerate(outputs):
if torch.argmax(output) == y[i]:
n_correct += 1
n_total += 1
return n_correct / n_total
def main():
train_data = get_data_loader(is_train=True)
test_data = get_data_loader(is_train=False)
net = Net()
print("initial accuracy:", evaluate(test_data, net))
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
for epoch in range(2):
for (x, y) in train_data:
net.zero_grad()
output = net.forward(x.view(-1, 28*28))
loss = torch.nn.functional.nll_loss(output, y)
loss.backward()
optimizer.step()
print("epoch", epoch, "accuracy:", evaluate(test_data, net))
for (n, (x, _)) in enumerate(test_data):
if n > 3:
break
predict = torch.argmax(net.forward(x[0].view(-1, 28*28)))
plt.figure(n)
plt.imshow(x[0].view(28, 28))
plt.title("prediction: " + str(int(predict)))
plt.show()
if __name__ == "__main__":
main()
然后进入你的test.py所在目录,点击上方路径框框,删掉原来的,输入cmd,回车。

然后运行 python test.py,注意,首次运行会下载训练用的MNIST数据集,请保持网络畅通。

可以看到,网络初始正确率仅仅0.08,经过一个轮次正确率就达到了0.95。
下面解析代码。
一、导入必要的库(你可以理解为“工具包”):
import torch # PyTorch 主库,处理张量、模型、训练等
from torch.utils.data import DataLoader # 用于把数据整理成一批一批
from torchvision import transforms # 用来做图像的预处理(比如转成张量)
from torchvision.datasets import MNIST # 直接导入MNIST数据集
import matplotlib.pyplot as plt # 用于显示图像
二、定义神经网络模型(核心部分)
class Net(torch.nn.Module): # 我们的模型继承自 PyTorch 提供的标准模型类
torch.nn.Module 是 PyTorch 中所有神经网络的爸爸,我们自己写的网络也要继承它。
def __init__(self):
super().__init__() # 调用父类的初始化方法
# 输入层到第一层:28*28=784,表示图像展平成一个长向量
self.fc1 = torch.nn.Linear(28*28, 64) # 输入784个数字,输出64个
# 第二层,全连接,输入64个神经元,输出64个
self.fc2 = torch.nn.Linear(64, 64)
# 第三层,全连接
self.fc3 = torch.nn.Linear(64, 64)
# 输出层:输出10个结果,对应数字0~9的分类概率
self.fc4 = torch.nn.Linear(64, 10)
补充概念:
- 全连接层(Linear) :每个神经元都与上一层所有神经元相连。
- 输入28×28:因为MNIST实际图像大小是28x28。
- 输出10:因为数字有10类。
def forward(self, x): # 定义前向传播(输入如何一步一步流过网络)
x = torch.nn.functional.relu(self.fc1(x)) # 第一层 + ReLU激活
x = torch.nn.functional.relu(self.fc2(x)) # 第二层 + ReLU激活
x = torch.nn.functional.relu(self.fc3(x)) # 第三层 + ReLU激活
# 最后一层输出,使用log_softmax(对数 + 概率归一化)
x = torch.nn.functional.log_softmax(self.fc4(x), dim=1)
return x
补充概念:
- ReLU 是激活函数的一种,它的作用是:让正数保留,负数变成0。
- log_softmax:表示“预测每一类的概率”,并对结果取对数,配合
nll_loss 用。
三、准备训练/测试数据
def get_data_loader(is_train):
# 把图片转成张量(Tensor),同时自动把像素缩放到0~1之间
to_tensor = transforms.Compose([transforms.ToTensor()])
# 下载 MNIST 数据集(is_train=True 表示是训练集,否则是测试集)
data_set = MNIST("", is_train, transform=to_tensor, download=True)
# 把数据分成小批次,每次给15张图片给模型训练/测试
return DataLoader(data_set, batch_size=15, shuffle=True)
补充概念:
- Tensor:PyTorch 里的一种“张量”对象,类似于 Numpy 的多维数组。
- batch_size:每次训练用多少张图,太小训练慢,太大显存不够。
四、模型评估函数(测试准确率)
def evaluate(test_data, net):
n_correct = 0 # 正确预测的数量
n_total = 0 # 总预测数
with torch.no_grad(): # 不计算梯度,节省内存和加速
for (x, y) in test_data: # 遍历所有测试图片和标签
# 展平图像,再传入网络中得到预测
outputs = net.forward(x.view(-1, 28*28))
# 遍历每个预测结果
for i, output in enumerate(outputs):
if torch.argmax(output) == y[i]: # 如果预测的数字等于真实数字
n_correct += 1
n_total += 1 # 总数 +1
return n_correct / n_total # 返回准确率
补充概念:
- torch.argmax:找到预测结果中概率最大的那一类,认为就是模型的预测结果。
五、主函数:训练 + 评估 + 可视化
def main():
# 加载训练和测试数据
train_data = get_data_loader(is_train=True)
test_data = get_data_loader(is_train=False)
# 初始化我们的神经网络
net = Net()
# 看看一开始(没训练前)准确率有多低
print("initial accuracy:", evaluate(test_data, net))
开始训练!
# Adam 是一种智能优化器,比传统方法更快收敛
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
for epoch in range(2): # 训练2轮(可以改成更多)
for (x, y) in train_data:
net.zero_grad() # 每次先清空旧梯度
# 把图像展平成一行,送入网络得到预测
output = net.forward(x.view(-1, 28*28))
# 计算损失:实际值 y 和预测值 output 的差距
loss = torch.nn.functional.nll_loss(output, y)
loss.backward() # 反向传播:计算每层误差
optimizer.step() # 调整每层权重
# 每轮训练完就评估一次准确率
print("epoch", epoch, "accuracy:", evaluate(test_data, net))
六、展示前4张预测图像(可视化结果)
for (n, (x, _)) in enumerate(test_data): # 从测试集中取前4张图片
if n > 3:
break
# 预测这张图属于哪个数字(注意只取一张图 x[0])
predict = torch.argmax(net.forward(x[0].view(-1, 28*28)))
# 显示图像
plt.figure(n)
plt.imshow(x[0].view(28, 28)) # 转换成 28x28 的二维图像显示
plt.title("prediction: " + str(int(predict))) # 标题显示预测数字
plt.show()
七、程序启动点
if __name__ == "__main__":
main()
含义:
只有当你直接运行这个文件时,才会执行 main()。如果被别的文件导入,则不会执行。
结语:
代码方面看懂个大概就好,主要是原理,相信通过这篇文章,你已经进行了基础入门啦!

















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









