









Human Semantic Parsing for Person Re-identification
论文:Human Semantic Parsing for Person Re-identification,cvpr,2018
链接:paper
代码:github
摘要
背景:现有方法都是利用检测框来对局部特征进行提取,这样的框精度较低,并且现有的方法涉及很多模块,相对比较复杂,通过大量实验证明使用简单且有效的训练方法效果是非常好的;
贡献:文中提出了SPReID,利用human semantic parsing来处理局部视觉线索;训练了自己的分割模型,并在human分割任务上超过了SOTA方法;本文的方法大幅度提升了在Market-1501、CUHK03、DukeMTMC-reID上的性能。
引言
近年来,行人重识别的研究主题从image-level的全局特征转向part-level 的局部特征,但是低分辨率往往会造成Part detection 的不准确,同时现有的part-level 方法都过于复杂。
针对上述两个问题,本文表明简单的基于Inception-V3使用一个简单的训练策略仅在全图上进行处理性能能够超过SOTA;利用具有像素级精度的语义分割来从身体部分提取局部特征。
网络结构
作者提出的SPReID如同下图所示,总共包含了一个卷积backbone和一个人体分割的branch,然后将两者的结果结合在一起。使用Inception-V3 作为行人语义分析和行人重识别模型的主干模型。Inception-V3有48层,和Resnet152有相当的精度,却有很小的计算量。特征图输出位32步长。
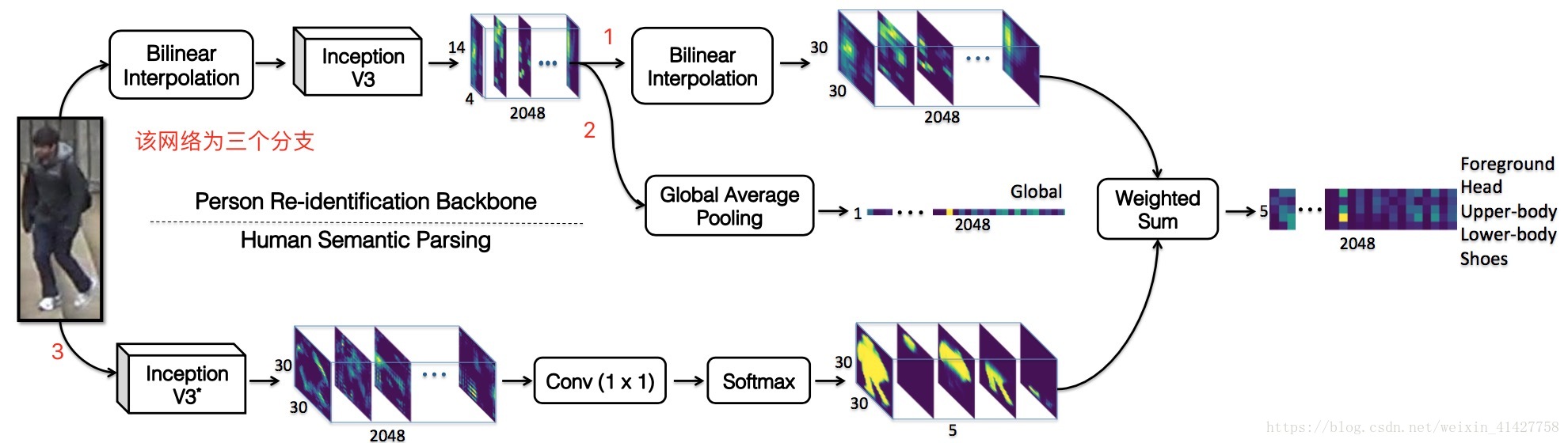
1、Human Semantic Parsing Model
人体语义解析模型可以更好的利用局部线索,像素级的semantic 具有更高的精度,相比bbox 对姿势的变化更加鲁棒。
Inception-V3 作为分割的backbone(两处修改):
- 将Inception-V3最后一层卷积stage中的stride由2改为了1,也就意味着经过一次网络前向以后这个降采样的倍率由32降到了16,最终的输出feature map分辨率提升了一倍;
- 同时为了使得计算量不增加,对于输出的feature map,论文移除了GAP并增加了ASPP(atrous spatial pyramid pooling)(rates=3,6,9,12),之后接入1x1的卷积层,最后对人体部件的类型进行分类输出。
2、Person Re-identification Model
- 在SPPReID中的Inception-V3移除了GAP,这样输出为2048通道的32 output stride.
- 文中的baseline person re-identification model 使用了GAP 汇聚了卷积输出的特征,产生了2048-dim的全局表示,softmax cross-entropy loss 训练。
- 局部视觉线索的使用:使用human semantic parsing model 产生的五个身体不同区域的概率图
- 在SPPReID 中,利用每个概率图对卷积backbone的输出进行了汇总得到了5x2048 的 特征图,每一行对应通过一个概率图汇总得到的特征向量,相比GAP,这样的方法对空间位置有一定可知性,也可以将概率图看成身体各部分的权重
- 实现细节:
- 将两个分支的输出特征图flatten 进行矩阵乘法。eg.对于一个身体部位概率图:30x30x2048 –> 900x2048;30x30x1 –> 900x1; 1x900 x 900x2048 –> 1x2048
- 将head、upper-body、lower-body、shoes的结果进行了元素间的max操作最终得到一个2048-D 矢量,并与前景矢量2048-dim以及global representation拼接起来,总共3x2048的特征被用于分类和特征检索。
- 语义分割模型通常需要较高分辨率的图片,对于送入re-identification backbone的图片先通过双线性插值缩小,再在最后的激活值处通过双线性插值放大来匹配human semantic parsing branch的分支
实验
1、本文方法主要在Market1501、CUHK03、DukeMTMC-reID上进行了评估,
2、实验结果:
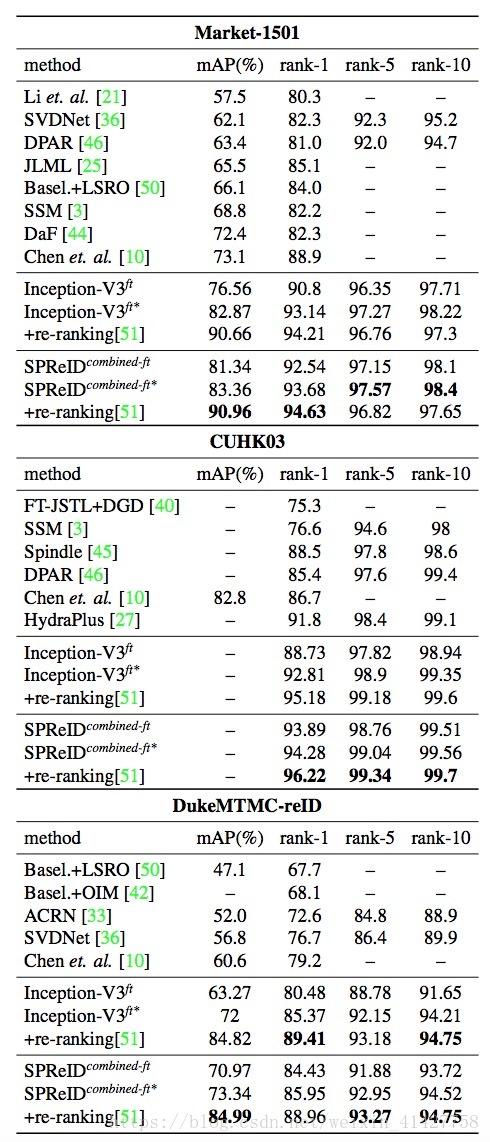
总结
- 本文提出的两个问题:
- 实现SOTA的model需要这么复杂吗?
- bbox是处理局部视觉线索最好的方法吗?
- 通过大量的实验解决上述问题:
- 仅使用简单的model在大量高分辨率的图片上训练即可超越SOTA
- 使用human sematic parsing来处理局部视觉线索可以进一步提高性能
本文实验丰富,但是应该再做一个和bbox 对比的实验呢?















 1207
1207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









