







刚好最近在找场景分类精度更高的模型,因此将会对近年来精度更高的模型(tensorflow slim中集成的模型除外)进行逐一测试。
Xception: Deep Learning with Depthwise Separable Convolutions ,谷歌去年推出的一篇论文。
看了下这篇论文,它是在inceptionVX的基础上演变过来的。
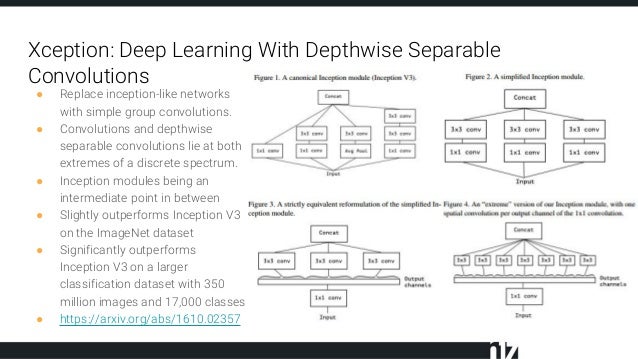
上面右侧四个图刚好也是论文中思路阐述的重要部分。这些都要追溯到inception相关的结构。
当时提出Inception的初衷可以认为是:特征的提取和传递可以通过1*1卷积,3*3卷积,5*5卷积,pooling等,到底哪种才是最好的提取特征方式呢? Inception结构将这个疑问留给网络自己训练,也就是将一个输入同时输给这几种提取特征方式,然后做concat。经典的Inception v3主要是将5*5卷积换成两个3*3卷积层的叠加。
Figure3表示对于一个输入,先用一个统一的1*1卷积核卷积,然后连接3个3*3的卷积,这3个卷积操作只将前面1*1卷积结果中的一部分作为自己的输入(这里是将1/3channel作为每个3*3卷积的输入)。
之后,论文又讨论了下inception的极限,这也构成了xception的架构。

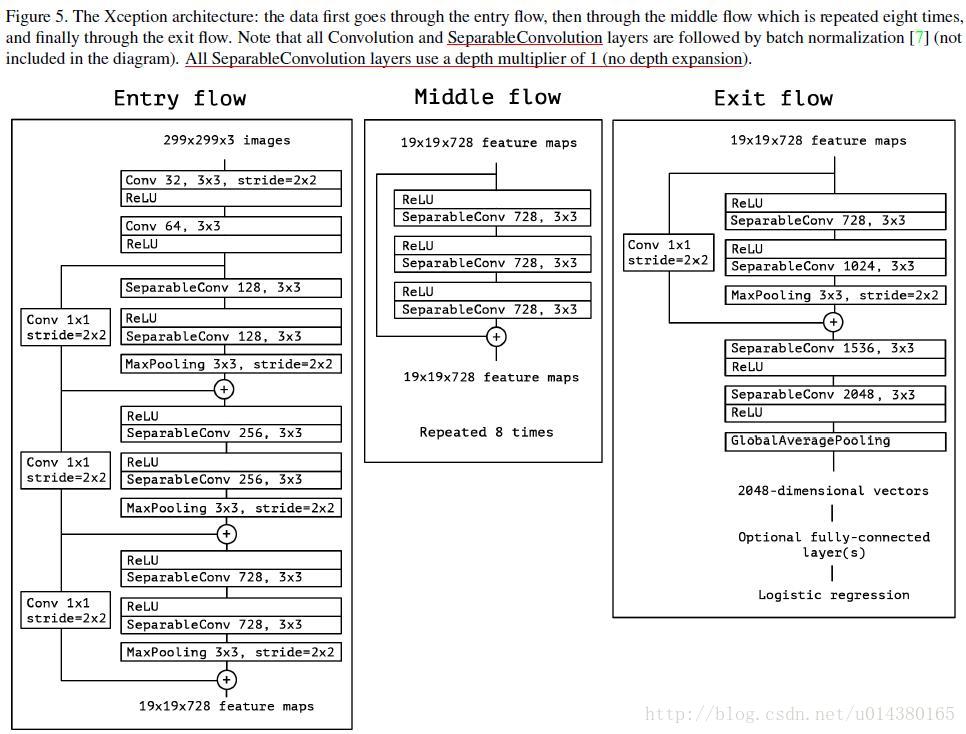
论文中指出:In short, the Xception architecture is a linear stack of depthwise separable convolution layers with residual connections.This makes the architecture very easy to defineand modify; 这种方法原理如下图:
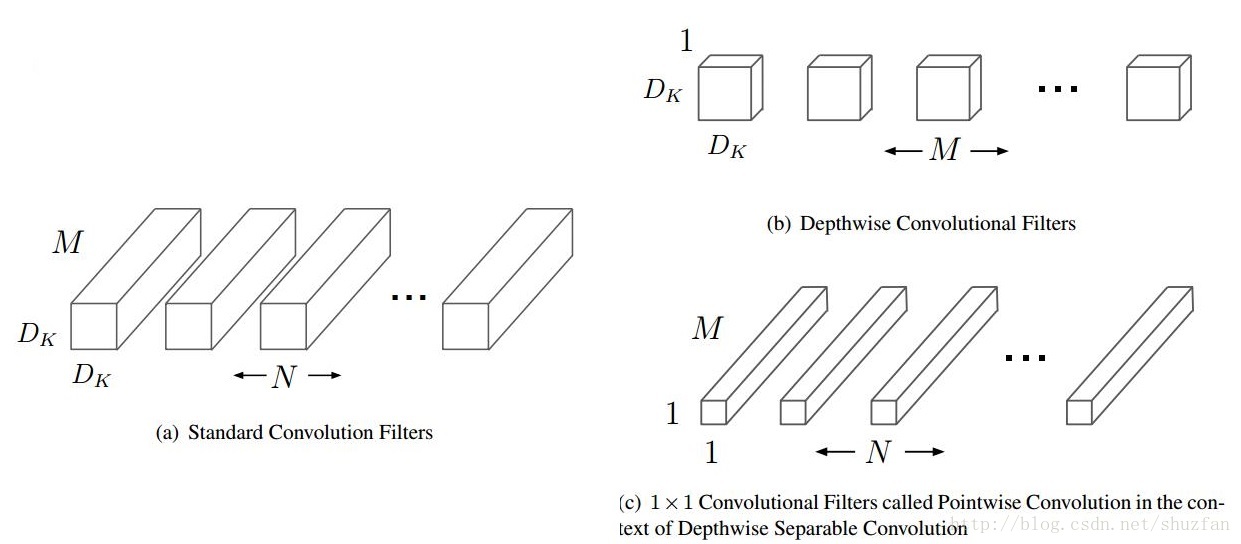
在depthwise separable convolution中是先进行一个channel-wise的spatial convolution,也就是上图的(b),然后是1*1的卷积。而在Figure4中是先进行1*1的卷积,再进行channel-wise的spatial convolution,最后concat。在Figure4中,每个操作后都有一个ReLU的非线性激活,但是在depthwise separable convolution中没有。
论文还给出了实验结果:

明显地看,比V3是有很大的提升。由于xception已经集成到KERAS,因此利用KERAS进行实验,还是对之前反复测试的多场景分类图来进行测试:

对tensorflow slim中的模型,其测试结果为:
使用预训练模型:InceptionV4 进行训练后的效果比较:
Probability 94.92% => [alp]
Probability 1.09% => [valley, vale]
Probability 0.80% => [monastery]
Probability 0.51% => [church, church building]
Probability 0.19% => [bell cote, bell cot]
使用预训练模型:inception_resnet_v2 进行训练后的效果比较:
Probability 78.76% => [alp]
Probability 6.80% => [church, church building]
Probability 1.50% => [bell cote, bell cot]
Probability 1.50% => [monastery]
Probability 1.33% => [valley, vale]
使用xception的预测结果为:

图片../imgs/lussari.jpg 的预测结果如下:
('n09193705', 'alp', 0.88302344)
('n02980441', 'castle', 0.018367991)
('n09468604', 'valley', 0.016518271)
('n03781244', 'monastery', 0.015572131)
('n03028079', 'church', 0.013273265)















 1898
1898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









