







 本文介绍了一种基于场景动态的视频生成方法,该方法利用大量未标注视频数据来获取关于场景动态的先验信息,并提出了一个生成模型来合成动态场景视频。通过对视频帧中的静态背景和动态前景进行分离和建模,可以有效地生成新的视频片段。
本文介绍了一种基于场景动态的视频生成方法,该方法利用大量未标注视频数据来获取关于场景动态的先验信息,并提出了一个生成模型来合成动态场景视频。通过对视频帧中的静态背景和动态前景进行分离和建模,可以有效地生成新的视频片段。
视频生成与视频识别是视频分析的两大任务,前者侧重于对下一帧的预测,而前者则侧重于视频内容的理解。由于视频是由一系列的视频帧组成的,那么如果有大量的视频数据,通过分析视频中动态场景的变化情况,就可以合成出一些小的动态场景视频。这也是论文Generating Videos with Scene Dynamics(http://carlvondrick.com/tinyvideo/paper.pdf)的主要思想。
1、论文原理
The primary contribution of this paper is showing how to leverage large amounts of unlabeled video in order to acquire priors about scene dynamics. The secondary contribution is the development of a generative model for video.
从论文中可以看出,论文主要有两大贡献:
(1)从海量的未标记视频数据获取动态场景的先验信息;
(2)提出一种视频的生成模型。
视频生成的原理框架如下图所示:
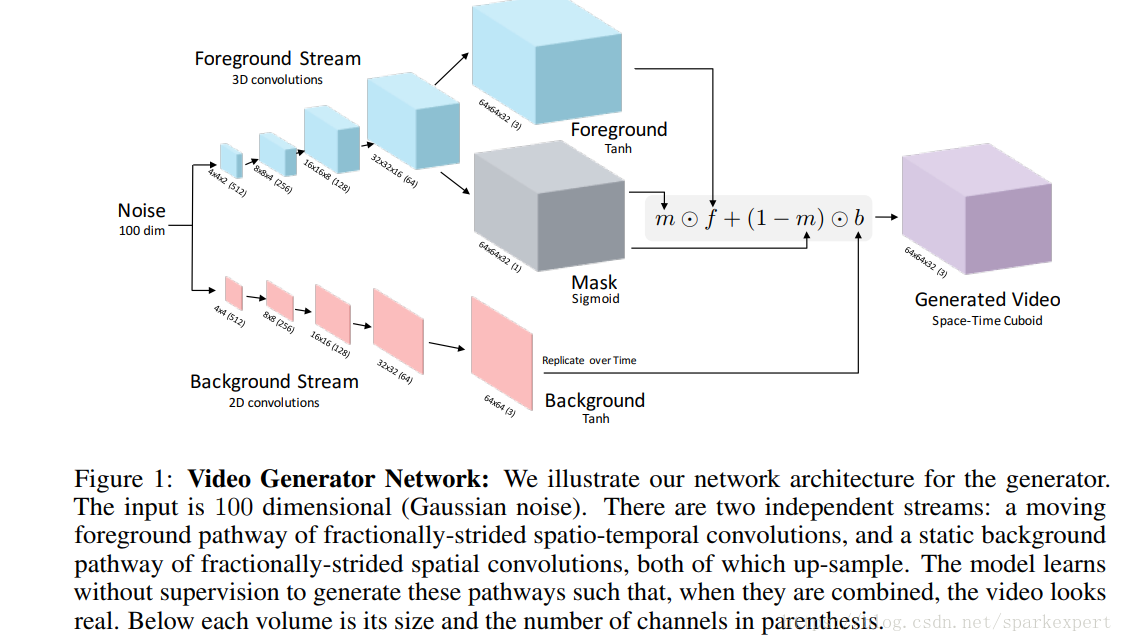
由于视频通常由静态的背景和动态的前景构成。论文根据这一常识设计了双路的生成模型分别用来生成静态背景 Background 和前景动态Foreground。其合成方式见foregroud, mask 和background的公式。其合成过程的可视化如下图所示:

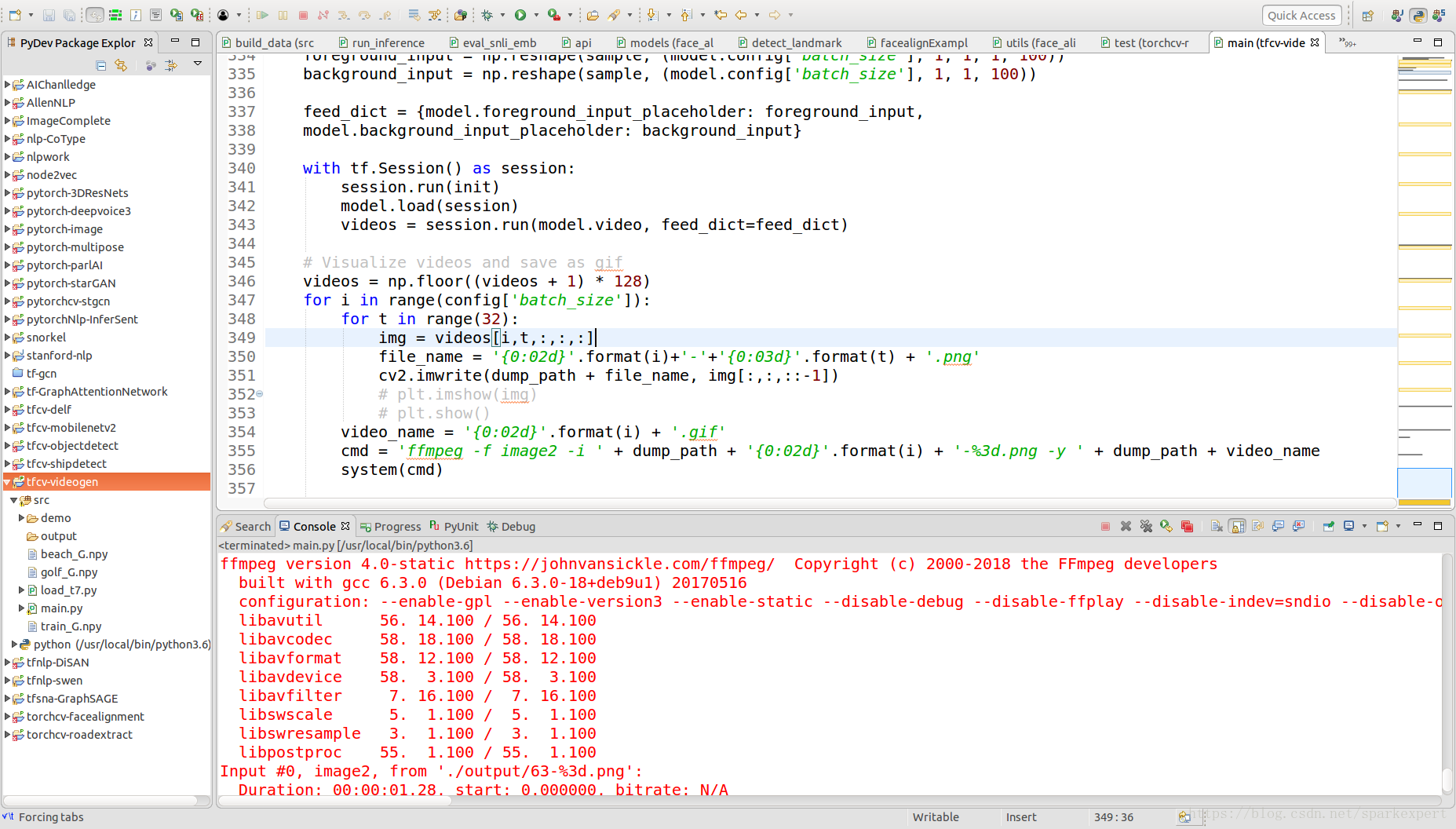
2、论文实践
发现公开代码非常简单,很快就测试通过,其截图如下所示:
结果如下所示:(沙滩上视频生成)

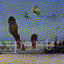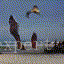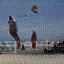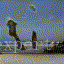
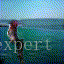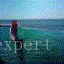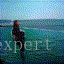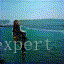



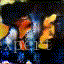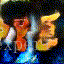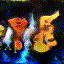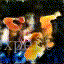






















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









