







@[toc](GAN学习笔记-KL散度(Kullback-Leibler Divergence)、JS散度(Jensen–Shannon divergence)、Wasserstein Distance)
参考
相对熵(KL散度)
JS散度)
GAN:两者分布不重合JS散度为log2的数学证明
【数学】Wasserstein Distance
1.KL散度(Kullback-Leibler Divergence)
相对熵,又被称为KL散度或信息散度,是两个概率分布间差异的非对称性度量 。在信息论中,相对熵等价于两个概率分布的信息熵的差值,若其中一个概率分布为真实分布,另一个为理论(拟合)分布,则此时相对熵等于交叉熵与真实分布的信息熵之差,表示使用理论分布拟合真实分布时产生的信息损耗 。

上面的p(xi)为真实事件的概率分布,q(xi)为理论拟合出来的该事件的概率分布。也就是在理论拟合出来的事件概率分布跟真实的一模一样的时候,相对熵等于0。而拟合出来不太一样的时候,相对熵大于0。这个性质很关键,因为它正是深度学习梯度下降法需要的特性。假设神经网络拟合完美了,那么它就不再梯度下降,而不完美则因为它大于0而继续下降。
但它有不好的地方,就是它是不对称的。比如随机变量X ∼ P取值为1,2,3时的概率分别为[0.1,0.4,0.5],随机变量Y ∼ Q 取值为1,2,3时的概率分别为[0.4,0.2,0.4],则:
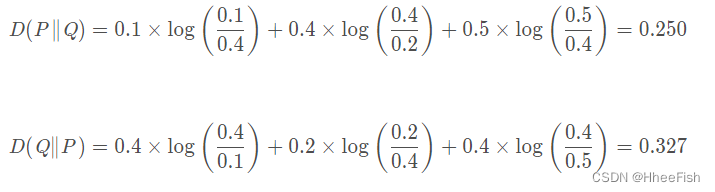
也就是用P来拟合Q和用Q来拟合P的相对熵居然不一样,而他们的距离是一样的。这也就是说,相对熵的大小并不跟距离有一一对应的关系。
既然如此,那为什么现在还是很多人用相对熵衍生出来的交叉熵作为损失函数来训练神经网络呢?
假设神经网络的最后一层激活函数为sigmoid,它长这样:
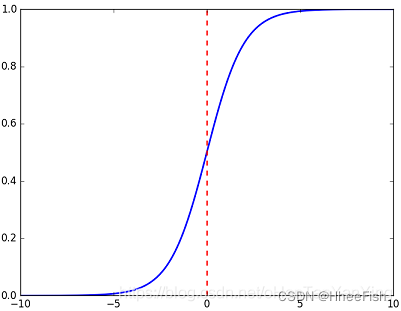
可以看到它的两头异常的平,也就是说在那些地方的导数接近于0。而反向传播是需要求导的,这在y接近于0或者1的时候都趋于0,会导致梯度消失,网络训练不下去。但如果用相对熵衍生出来的交叉熵作为损失函数则没有这个问题。因此虽然相对熵的距离特性不是特别好,但总归好过直接梯度消失玩不下去,因此很多用sigmoid作为激活函数的神经网络还是选择了用相对熵衍生出来的交叉熵作为损失函数。
当然如果你选用的不是sigmoid激活函数,则不需要考虑这些。
相对熵公式只有在p(xi))等于q(xi)的时候等于0,其他时候大于0。
2.JS散度(Jensen–Shannon divergence)
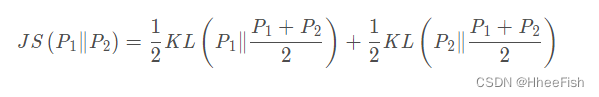
可以轻易看出这个公式对于P1和P~2 ~是对称的,而且因为是两个KL的叠加,由相对熵的文章我们知道KL的值一定是大于等于0的,因此这个公式也一定大于等于0,当满足:

JS散度等于0.
那么JS散度有什么缺陷呢,以下面这个分布图为例:
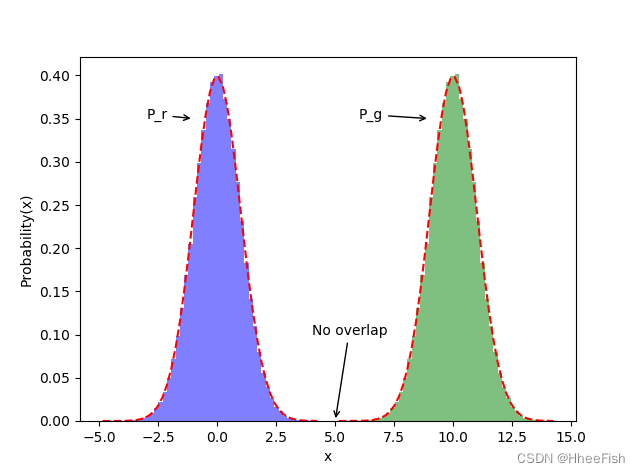
在这张图里,我们令Pr和Pg都是服从正态分布,并且不妨令(x)p(x)为Pr取得x xx时的概率,q(x)为Pg取得x时的概率。可以发现,在两个分布之间,几乎不存在重叠(Probability(x)表示取得x xx的概率值)
接下来,我们回到上式
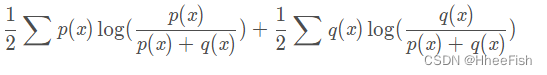
可以发现,当x ≥ 5≥5时,p(x)≈0,则上式变为
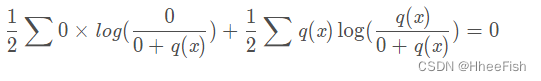
当x5时,q(x)≈0,则上式变为
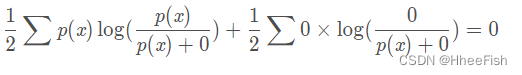
所以可以得出,
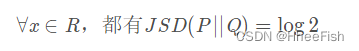
当两个分布完全不重叠时,即便两个分布的中心距离有多近,其JS散度都是一个常数,以至于梯度为0,无法更新。
3.Wasserstein Distance

Π(P1,P2)是 P1和 P2 分布组合起来的所有可能的联合分布的集合。对于每一个可能的联合分布γ,可以从中采样 (x,y)∼γ得到一个样本 x和y,并计算出这对样本的距离 ||x−y||,所以可以计算该联合分布 γ 下,样本对距离的期望值 E(x,y)∼γ[||x−y||],在所有可能的联合分布中能够对这个期望值取到的下界就是Wasserstein距离。
Wasserstein距离我们可以简单的理解为‘代价距离’,那如何理解‘代价距离’呢?
我们现在存在两个离散分布
P1=0 P2=5 P3=10
Q1=5 Q2=9 Q3=4
我们如何衡量两者分布差异? 我们可以理解为 P分布要花多大代价才能和Q保持一致?
对于P1而言,P1需要+5才能和Q1保持一致,那这个5哪儿来呢? 我们可以从P2处偷5个代价过来,那么P1就是5,P2就是0了,以此类推


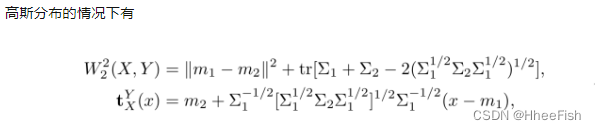















 3128
3128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









