







此系列为 Coursera 网站机器学习课程个人学习笔记(仅供参考)
课程网址:https://www.coursera.org/learn/machine-learning
参考资料:http://blog.csdn.net/MajorDong100/article/details/51104784
一、降维的作用
1.1 数据压缩
数据压缩(Data Compression)不仅能减少数据的存储量,节省了内存和磁盘,还会大大加快学习算法的运行速度。
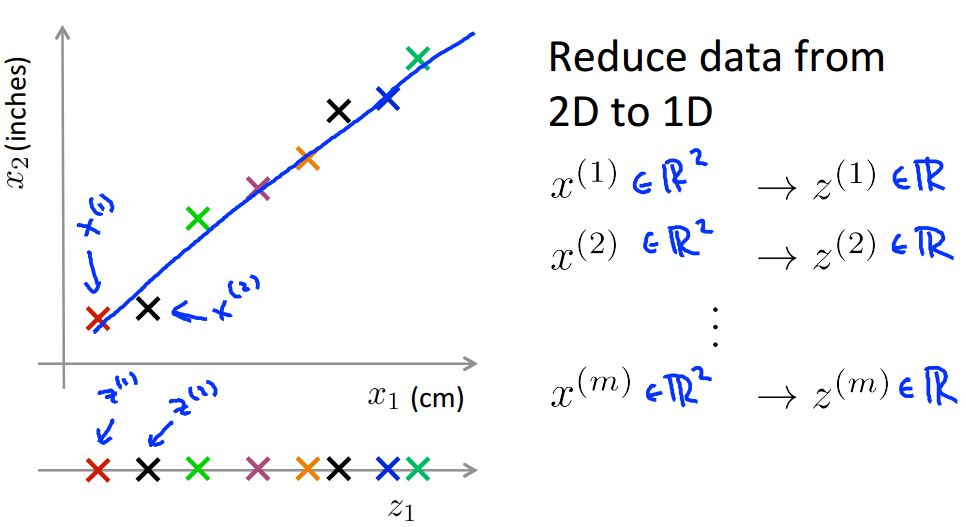
我们首先来介绍降维(Dimensionality Reduction)。假设我们已经收集了大量数据,其中含有特别多的特征,这里我们只选择其中的两个特征 x1 和 x2 ,二者都用来表示某一事物的长度, x1 的单位是厘米, x2 的单位是英寸,如下图所示。很明显数据存在冗余,我们可以使用一个特征来表示事物的长度,数据从二维降到一维。当然,实际生产中我们可能不会出现这么低级的问题,这里仅以此来做说明。
工业上的一个问题中可能会有上千个特征,很容易出现冗余。联系到直升机飞行员的例子,这里用 x1 表示飞行员的驾驶技巧,用 x2 表示飞行员对工作的喜爱程度,这两个特征时高度相关的,我们要从这两个特征中提取出一个新的特征 z1 (如pilot attitude)来代替它们。如下图所示,我们找到这样一条直线,每一个数据点在这条直线上的投影作为新的数据点,我们就可以实现二维到一维的降维。通过类似这样的方法,我们就实现了降维。
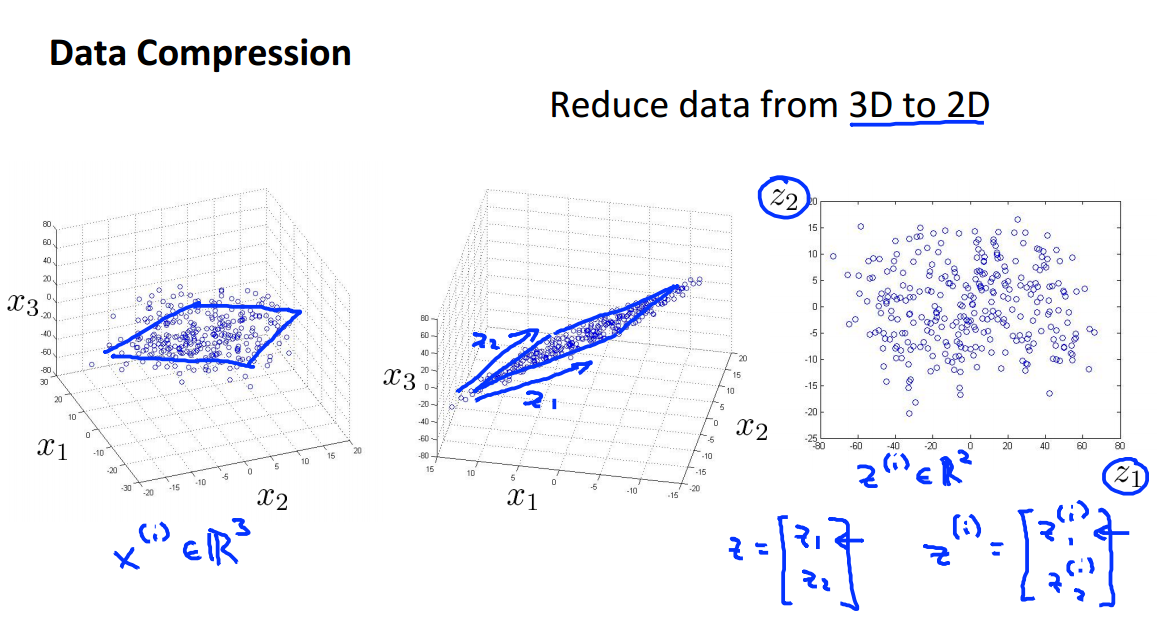
再给出一个三维降到二维的例子。如下图所示,我们可以将三维坐标系中的数据点投影到一个二维平面上,实现三维到二维的降维。
1.2 可视化数据
下面我们会介绍一种数据降维的应用——可视化数据。
在很多学习算法的应用中,对数据的理解可以帮助我们更好的改善模型,而降维恰好可以帮助我们实现数据的可视化,增进我们对数据的理解。
我们从第一个例子开始。
下面是大量的有关世界不同国家的统计数据集。数据中有很多特征,这对我们观察这些数据造成了很大的困难。我们怎样才能更好地理解这些数据?
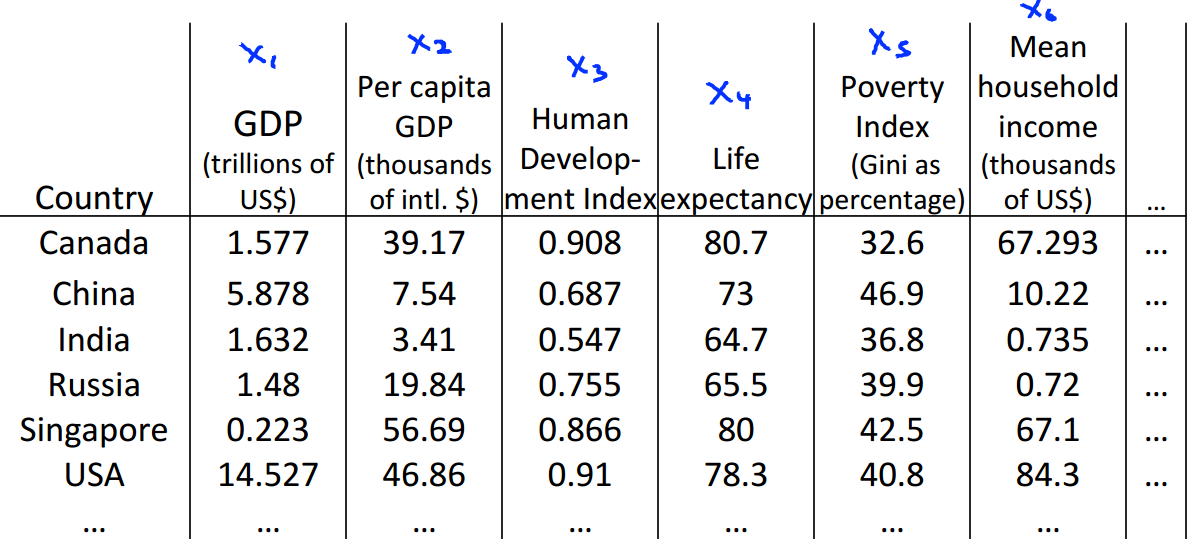
如果我们将下面表格中的多个特征降维到2个特征(如下图所示),然后在直角坐标系中画出它们。
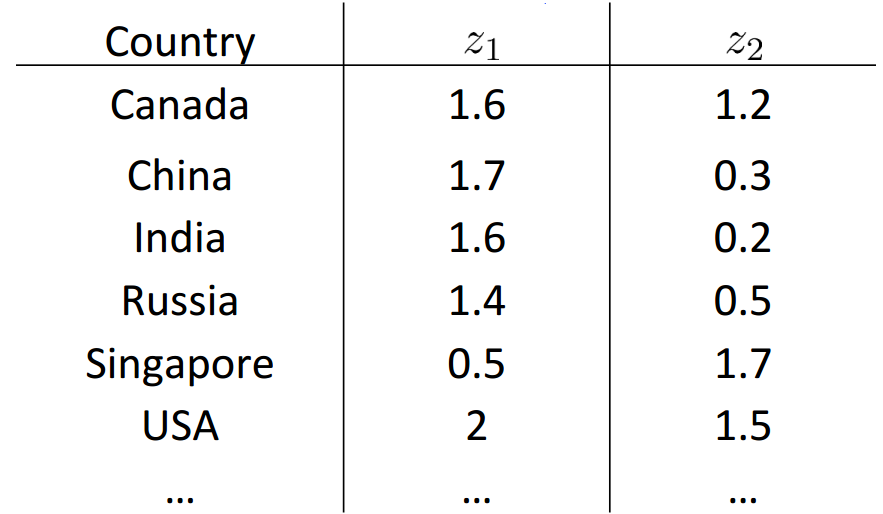
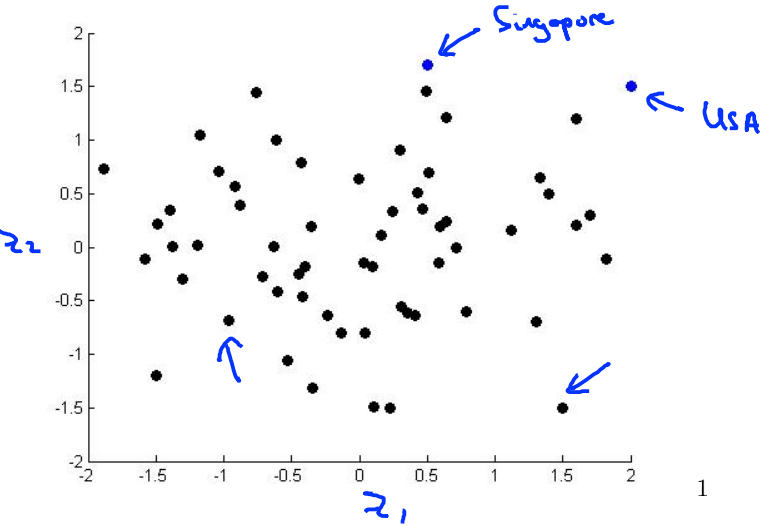
上图中坐标系的横轴可以表示一个国家的经济总量,纵轴代表人均经济量,图中的每一个点代表一个国家。如右上侧的那个绿点可能是美国——经济总量世界第一,人均经济量也达到很高的一个数值;最上方的那个绿点可能代表新加坡——经济总量不大(国家太小),但人均量很高。了解了一个国家在这张图上的位置,我们也就知道了这个国家的经济状况。当然我们也可以将横纵坐标变成其他的指标,实现对其他特征的可视化。
一般我们可视化会将数据降到二维或三维,因为更高维度的图像画起来会比较困难。
二、主成分分析(PCA)
在降维问题中最常见的一种算法是主成分分析(Principal Component Analysis,PCA)。下面我们会对这一算法进行详细介绍。
2.1 PCA的工作
如下图所示一个数据集:
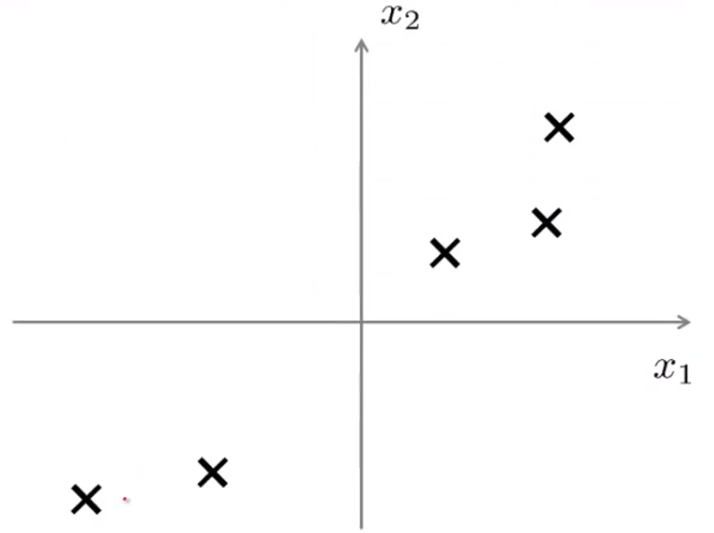
我们希望把数据从二维降到一维,也就是找到一条直线,把这些点投影到直线上去,那么怎么找到一条好的直线来投影?下图的红色直线也许是一个不错的选择,因为我们发现这些点到他们对应的投影点之间的距离非常小(即蓝色线段)。

上面的蓝色线段称为“投影误差”。PCA所做的事情就是找到一个低维的面,将数据投影到上面,并使得投影误差最小。在进行PCA之前,我们会先进行均值归一化和特征缩放使得特征 x1 和 x2 均值为 0 。
对比红线,我们再来看看另一条直线,如下图粉色直线所示。如果将数据点投影在这条直线上,投影误差会很大,因此,PCA算法会选择红色的直线而不会选择粉色这条。
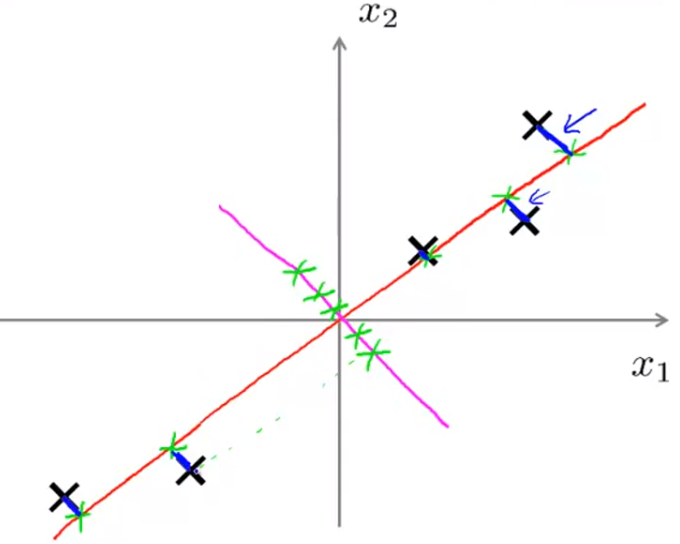
- 对于二维降到一维,PCA的目标是找到一个二维向量(
u(1)∈Rn , u(1) 的方向是正是负并没有关系),并且最小化投影误差。
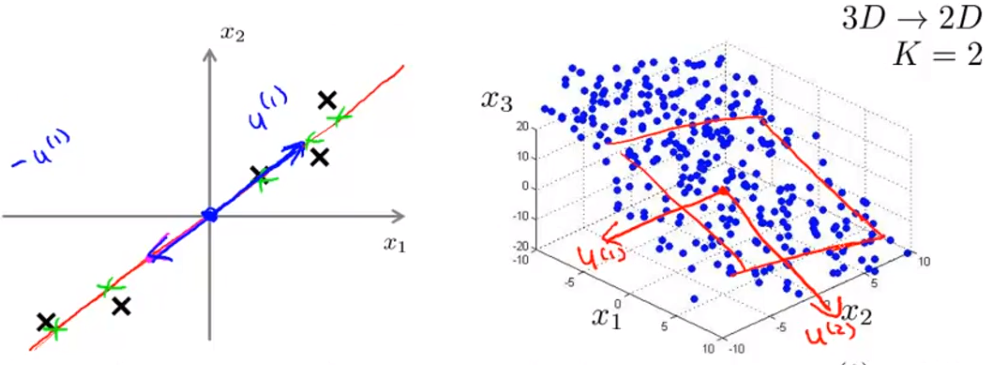
- 对于从 n 维降到
k 维,我们则需要找到 k 个n 维向量来实现。如下图所示,左图为二维降到一维,右图为三维降到二维:
2.2 PCA的算法
2.2.1 数据预处理
拿到数据以后,我们一般先进行均值归一化和特征缩放(详见 1.3特征缩放)。① 算出每个特征的均值 μ :
μj=1m∑mi=1x(i)j② 将每一个数据 x(i)j 都替换成:
x(i)j−μj如果每个特征的取值范围不同,我们还要进行特征缩放:
x(i)j←x(i)j−μjsjμi 是训练数据集中 xi 的平均值, si 是 xi 的取值范围( max(xi)−min(xi) ),或者 si 取 xi 的标准差。( x0 不进行上述操作)。
2.2.2 PCA算法
PCA所需要求的两个部分分别是投影向量和样本投影后的点,下面我们只介绍求取的过程不展开讲述原理与证明。③ 求解特征的协方差矩阵(Covariance Matrix):
Σ=1m∑ni=1(x(i))(x(i))T④ 求解特征值和特征向量:
#Octave [U S V]=svd(Sigma)svd 表示奇异值分解,Sigma就是第③步求到的协方差矩阵( Σ ),是一个 n×n 的矩阵。求得的矩阵U也是一个 n×n 的矩阵。
⑤ 求 U∈Rn×n 矩阵的前 k 列,组成
UReduce∈Rn×k ,用来投影数据。⑥ 求取降维后的数据 z(i) :
z(i)=(UReduce)Tx(i)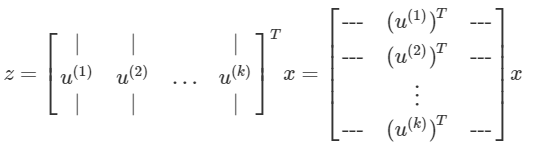
三、PCA的应用
3.1 压缩后的数据重建
前面介绍了使用PCA对数据进行降维,已达到压缩数据提高计算速率的目标,现在我们尝试着从压缩后的数据出发还原数据,注意这里得到的数据是原始数据的近似。我们沿用前面二维降到一维的例子,现在我们尝试着从一维升维到二维。具体的公式是:
xapprox=UReduce⋅z如果投影误差能够取到很小很小的值,则会有:
x≈xapprox
3.2 如何选择参数 k
在PCA算法中,我们把
n 维特征变量降维到 k 维特征变量,这个数字k 是PCA算法的一个参数,这个数字 k 也被称作主成分的数量,或者说是我们保留的主成分的数量。下面我们就来讲述如何选择这个参数k 。我们先来看几个有用的概念。
平均平方映射误差 (Average Squared Projection Error):
1m∑mi=1∥∥x(i)−x(i)approx∥∥2数据总变差(Total Variance in the data):
1m∑mi=1∥∥x(i)∥∥2接下来,我们给出一个计算公式 err:
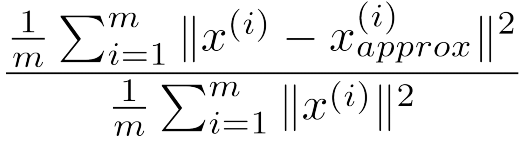
我们用这个公式来量化原始数据与降维后数据的差距。若该值不超过 0.01 ( 1% ),我们就可以说“ 99% of variance is retained”。(除了 0.01 ,我们还可以选择 0.05 , 0.10 )我们可以把err作为选择 k 值得指标:取
k=1 ,完成一系列降维计算,判断err是否大于等于 0.01 ,若满足则确定该 k 值为最终的k ;若不满足,则 k 加1 ,继续前面的计算直至满足要求。显然上面的过程效率非常的低。这里给出了计算err的一种简便方法。PCV求解过程中有这样一个公式
[U,S,V]=svd(sigma)其中的 S 是一个
n×n 的对角矩阵,对角线上是求得的特征值,从上到下依次递减。err可由下面的公式求得:err=1−∑ki=1Sii∑ni=1Sii这样我们就可以只进行一次svd运算,然后依次增加 k ,找出满足
err≤0.01 的最小 k 值。
3.3 应用PCA时的一些建议
假设一条数据中包含
10000 个特征,通过PCA降低到 1000 个特征,无论是在有监督式学习还是在无监督式学习中,这种降维对学习速度的提升是显著的。需要注意的一点是PCA只能在训练集上进行,得到的 Ureduce 同样能应用在交叉验证集和测试集上。在前面的学习中,我们知道过多的特征提取会导致过拟合,此时采取的措施是适当的去掉一些特征。而现在的降维恰好减小了特征的数量,那么我们是否可以通过降维来改善过拟合呢?答案是否定的。PCA不能用于解决过拟合问题。
需要注意的一点是,在进行机器学习时,我们首先使用的是原始数据。只有当算法的速度过慢、内存或磁盘不够,或者你有足够的把握确定问题出在原始数据上(此处的问题当然不是指数据的真假问题),这时你才可以考虑降维。















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









