







翻译笔记:https://zhuanlan.zhihu.com/p/21560667?refer=intelligentunit
数据预处理
均值减法
它对数据中每个独立特征减去平均值,从几何上可以理解为在每个维度上都将数据云的中心都迁移到原点。
#numpy
X -= np.mean(X, axis=0)归一化
是指将数据的所有维度都归一化,使其数值范围都近似相等。在图像处理中,由于像素的数值范围几乎是一致的(都在0-255之间),所以进行这个额外的预处理步骤并不是很必要。
X /= np.std(X, axis=0)。PCA和白化(Whitening)
在这种处理中,先对数据进行零中心化处理,然后计算协方差矩阵,它展示了数据中的相关性结构。
# 假设输入数据矩阵X的尺寸为[N x D]
X -= np.mean(X, axis = 0) # 对数据进行零中心化(重要)
cov = np.dot(X.T, X) / X.shape[0] # 得到数据的协方差矩阵我们可以对数据协方差矩阵进行SVD(奇异值分解)运算:
U,S,V = np.linalg.svd(cov)U的列是特征向量,S是装有奇异值的1维数组(因为cov是对称且半正定的,所以S中元素是特征值的平方)。为了去除数据相关性,将已经零中心化处理过的原始数据投影到特征基准上:
Xrot = np.dot(X,U) # 对数据去相关性注意U的列是标准正交向量的集合(范式为1,列之间标准正交),所以可以把它们看做标准正交基向量。因此,投影对应x中的数据的一个旋转,旋转产生的结果就是新的特征向量。
np.linalg.svd的一个良好性质是在它的返回值U中,特征向量是按照特征值的大小排列的。我们可以利用这个性质来对数据降维。这个操作也被称为主成分分析( Principal Component Analysis 简称PCA)降维:
Xrot_reduced = np.dot(X, U[:,:100]) # Xrot_reduced 变成 [N x 100]最后一个在实践中会看见的变换是白化(whitening)。白化操作的输入是特征基准上的数据,然后对每个维度除以其特征值来对数值范围进行归一化。该变换的几何解释是:如果数据服从多变量的高斯分布,那么经过白化后,数据的分布将会是一个均值为零,且协方差相等的矩阵。该操作的代码如下:
# 对数据进行白化操作:
# 除以特征值
Xwhite = Xrot / np.sqrt(S + 1e-5)警告:夸大的噪声。注意分母中添加了1e-5(或一个更小的常量)来防止分母为0。该变换的一个缺陷是在变换的过程中可能会夸大数据中的噪声。这是因为它将所有维度都拉伸到相同的数值范围,这些维度中也包含了那些只有极少差异性(方差小)而大多是噪声的维度。在实际操作中,这个问题可以用更强的平滑来解决(例如:采用比1e-5更大的值)。
注意:任何预处理策略(比如数据均值)都只能在训练集数据上进行计算,算法训练完毕后再应用到验证集或者测试集上。例如,如果先计算整个数据集图像的平均值然后每张图片都减去平均值,最后将整个数据集分成训练/验证/测试集,那么这个做法是错误的。应该怎么做呢?应该先分成训练/验证/测试集,只是从训练集中求图片平均值,然后各个集(训练/验证/测试集)中的图像再减去这个平均值。
权重初始化
错误:全零初始化。
如果网络中的每个神经元都计算出同样的输出,然后它们就会在反向传播中计算出同样的梯度,从而进行同样的参数更新。换句话说,如果权重被初始化为同样的值,神经元之间就失去了不对称性的源头。
小随机数初始化
因此,权重初始值要非常接近0又不能等于0。解决方法就是将权重初始化为很小的数值,以此来打破对称性。
W = 0.01 * np.random.randn(D,H)警告:并不是小数值一定会得到好的结果。例如,一个神经网络的层中的权重值很小,那么在反向传播的时候就会计算出非常小的梯度(因为梯度与权重值是成比例的)。这就会很大程度上减小反向传播中的“梯度信号”,在深度网络中,就会出现问题。
使用1/sqrt(n)校准方差
上面做法存在一个问题,随着输入数据量的增长,随机初始化的神经元的输出数据的分布中的方差也在增大。我们可以除以输入数据量的平方根来调整其数值范围,这样神经元输出的方差就归一化到1了。也就是说,建议将神经元的权重向量初始化为:
w = np.random.randn(n) / sqrt(n)其中n是输入数据的数量。这样就保证了网络中所有神经元起始时有近似同样的输出分布。实践经验证明,这样做可以提高收敛的速度。
稀疏初始化(Sparse initialization)
另一个处理非标定方差的方法是将所有权重矩阵设为0,但是为了打破对称性,每个神经元都同下一层固定数目的神经元随机连接(其权重数值由一个小的高斯分布生成)。一个比较典型的连接数目是10个。
偏置(biases)的初始化
通常将偏置初始化为0,这是因为随机小数值权重矩阵已经打破了对称性。
实践当前的推荐是使用ReLU激活函数,并且使用
w = np.random.randn(n) * sqrt(2.0/n)来进行权重初始化。
批量归一化(Batch Normalization)
其做法是让激活数据在训练开始前通过一个网络,网络处理数据使其服从标准高斯分布。因为归一化是一个简单可求导的操作,所以上述思路是可行的。在实现层面,应用这个技巧通常意味着全连接层(或者是卷积层)与激活函数之间添加一个BatchNorm层。
在实践中,使用了批量归一化的网络对于不好的初始值有更强的鲁棒性。最后一句话总结:批量归一化可以理解为在网络的每一层之前都做预处理,只是这种操作以另一种方式与网络集成在了一起。
正则化(Regularization)
在实践中,使用了批量归一化的网络对于不好的初始值有更强的鲁棒性。最后一句话总结:批量归一化可以理解为在网络的每一层之前都做预处理,只是这种操作以另一种方式与网络集成在了一起。
L2正则化
可以通过惩罚目标函数中所有参数的平方将其实现。即对于网络中的每个权重
w
,向目标函数中增加一个
L1正则化
L1正则化是另一个相对常用的正则化方法。对于每个w我们都向目标函数增加一个 λ|w| 。L1和L2正则化也可以进行组合: λ1|w|+λ2w2
最大范式约束(Max norm constraints)
另一种形式的正则化是给每个神经元中权重向量的量级设定上限,并使用投影梯度下降来确保这一约束。在实践中,与之对应的是参数更新方式不变,然后要求神经元中的权重向量
w→
必须满足
||w→||2<c
这一条件,一般
c
值为
随机失活(Dropout)
随机失活(Dropout)是一个简单又极其有效的正则化方法。该方法由Srivastava在论文Dropout: A Simple Way to Prevent Neural Networks from Overfitting中提出的,与L1正则化,L2正则化和最大范式约束等方法互为补充。在训练的时候,随机失活的实现方法是让神经元以超参数
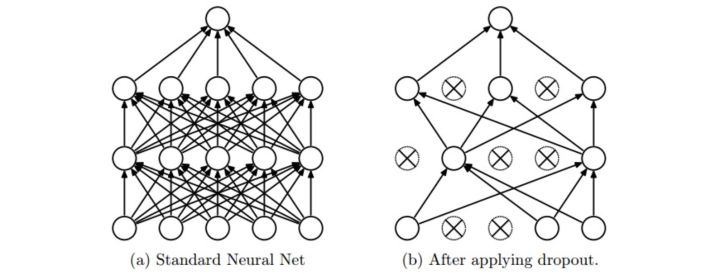
图片来源自论文,展示其核心思路。在训练过程中,随机失活可以被认为是对完整的神经网络抽样出一些子集,每次基于输入数据只更新子网络的参数(然而,数量巨大的子网络们并不是相互独立的,因为它们都共享参数)。在测试过程中不使用随机失活,可以理解为是对数量巨大的子网络们做了模型集成(model ensemble),以此来计算出一个平均的预测。
一个3层神经网络的普通版随机失活可以用下面代码实现:
""" 普通版随机失活: 不推荐实现 (看下面笔记) """
p = 0.5 # 激活神经元的概率. p值更高 = 随机失活更弱
def train_step(X):
""" X中是输入数据 """
# 3层neural network的前向传播
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # 第一个随机失活遮罩
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p # 第二个随机失活遮罩
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# 反向传播:计算梯度... (略)
# 进行参数更新... (略)
def predict(X):
# 前向传播时模型集成
H1 = np.maximum(0, np.dot(W1, X) + b1) * p # 注意:激活数据要乘以p
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # 注意:激活数据要乘以p
out = np.dot(W3, H2) + b3在上面的代码中,train_step函数在第一个隐层和第二个隐层上进行了两次随机失活。在输入层上面进行随机失活也是可以的,为此需要为输入数据X创建一个二值的遮罩。反向传播保持不变,但是肯定需要将遮罩U1和U2加入进去。
注意:在predict函数中不进行随机失活,但是对于两个隐层的输出都要乘以
p
,调整其数值范围。这一点非常重要,因为在测试时所有的神经元都能看见它们的输入,因此我们想要神经元的输出与训练时的预期输出是一致的。以
上述操作不好的性质是必须在测试时对激活数据要按照p进行数值范围调整。既然测试性能如此关键,实际更倾向使用反向随机失活(inverted dropout),它是在训练时就进行数值范围调整,从而让前向传播在测试时保持不变。这样做还有一个好处,无论你决定是否使用随机失活,预测方法的代码可以保持不变。反向随机失活的代码如下:
"""
反向随机失活: 推荐实现方式.
在训练的时候drop和调整数值范围,测试时不做任何事.
"""
p = 0.5 # 激活神经元的概率. p值更高 = 随机失活更弱
def train_step(X):
# 3层neural network的前向传播
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # 第一个随机失活遮罩. 注意/p!
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = (np.random.rand(*H2.shape) < p) / p # 第二个随机失活遮罩. 注意/p!
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# 反向传播:计算梯度... (略)
# 进行参数更新... (略)
def predict(X):
# 前向传播时模型集成
H1 = np.maximum(0, np.dot(W1, X) + b1) # 不用数值范围调整了
H2 = np.maximum(0, np.dot(W2, H1) + b2)
out = np.dot(W3, H2) + b3在随机失活发布后,很快有大量研究为什么它的实践效果如此之好,以及它和其他正则化方法之间的关系。如果你感兴趣,可以看看这些文献:
Dropout paper by Srivastava et al. 2014.
Dropout Training as Adaptive Regularization:“我们认为:在使用费希尔信息矩阵(fisher information matrix)的对角逆矩阵的期望对特征进行数值范围调整后,再进行L2正则化这一操作,与随机失活正则化是一阶相等的。”
实践:通过交叉验证获得一个全局使用的L2正则化强度是比较常见的。在使用L2正则化的同时在所有层后面使用随机失活也很常见。 p 值一般默认设为
0.5 ,也可能在验证集上调参。















 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









