






要点总结
-
标准的Transformer使用的是PostNorm
-
在完全相同的训练设置下Pre Norm的效果要优于Post Norm,这只能显示出Pre Norm更容易训练,因为Post Norm要达到自己的最优效果,不能用跟Pre Norm一样的训练配置(比如Pre Norm可以不加Warmup但Post Norm通常要加,这里说的warmup是指先给一个小的学习率warmup,然后再Linear decay)。Attention is all you need其实介绍过这种warmup(如下面截图)

-
在huggingface的VitTransformer中,笔者发现layernorm_before和layernorm_after都被用了(python3.9/site-packages/transformers/models/vit/modeling_vit.py)
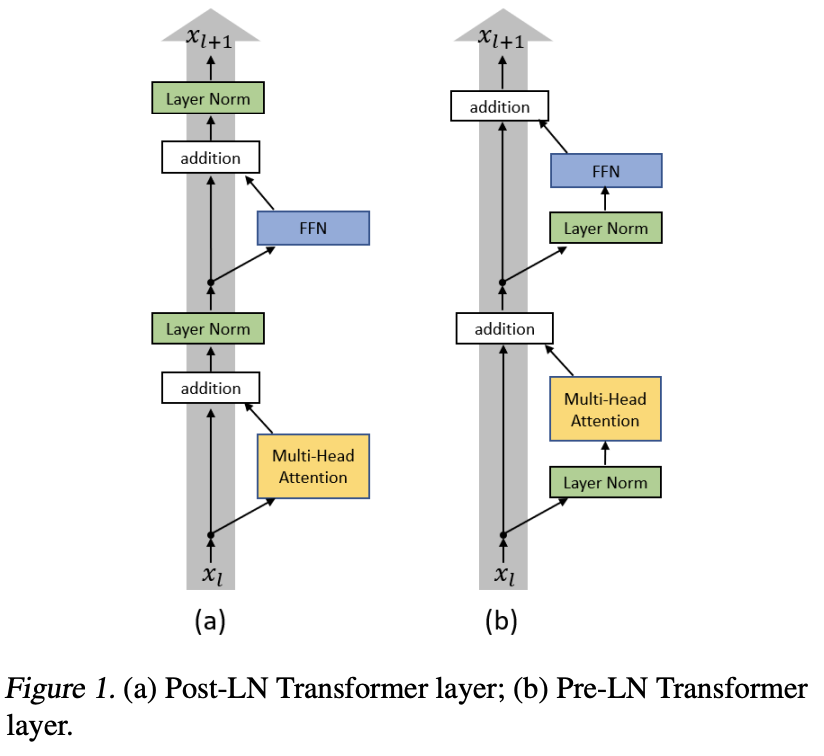
一些博客论文理解与转载
On Layer Normalization in the Transformer Architecture
这篇文章其实重点解释了Pre Norm可以不加Warmup但Post Norm通常要加,三个证明The main idea is that the layer normalization will normalize the gradients. In the Post-LN Transformer, the scale of the inputs to the layer normalization is independent of L, and thus the gradients of parameters in the last layer are independent of L.
为什么Pre Norm的效果不如Post Norm


















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









