







 本文介绍了DDIM反转技术在扩散模型中的应用,包括DDIM Sampling、Inversion Concept,以及如何在音频到图像的转换中使用扩散模型。通过DDIM Inversion可以编辑图像,替换图像中的对象,而在音频处理中,扩散模型被用来生成对应的频谱图,进而转换为音频。同时,文章探讨了Null-text Inversion解决DDIM在有指导情况下重建输入的问题,并提供了Fine-Tuning pipeline的方法。
本文介绍了DDIM反转技术在扩散模型中的应用,包括DDIM Sampling、Inversion Concept,以及如何在音频到图像的转换中使用扩散模型。通过DDIM Inversion可以编辑图像,替换图像中的对象,而在音频处理中,扩散模型被用来生成对应的频谱图,进而转换为音频。同时,文章探讨了Null-text Inversion解决DDIM在有指导情况下重建输入的问题,并提供了Fine-Tuning pipeline的方法。
任务四:
扩散模型的精细控制和拓展应用
DDIM Inversion
DDIM Inversion技术,是基于ODE过程可以在小步长的限制下进行反转的假设。它的采样过程跟DDIM正常采样过程相反,是从 , 数学表示为:
其中 是给定的真实图像的编码,Inversion最后得到包含原图像信息的噪声编码
,后面DDIM采样过程以
为初始值,能够近似重建原图像编码
,因此DDIM Inversion常用于真实图像编辑。
在实践中,DDIM Inversion每一步都会产生误差,对于无条件扩散模型,累积误差可以忽略。但是对基于classifier-free guidance( w >1 )的扩散模型,累积误差会不断增加,DDIM Inversion最终获得的噪声向量可能会偏离高斯分布,再经过DDIM采样,最终生成的图像会严重偏离原图像,并可能产生视觉伪影。因此,如果希望 DDIM Inversion之后的采样结果在layout上与原始图像相似,通常使用 当引导系数 w = 1, 即无 negative prompt时,DDIM Inversion产生的轨迹提供了原始图像的粗略近似。
DDIM Sampling
下面, 通过加载一个名为"runwayml/stable-diffusion-v1-5"的stable diffusion管线,实现这一想法:
import torch
import requests
import torch.nn as nn
import torch.nn.functional as F
from PIL import Image
from io import BytesIO
from tqdm.auto import tqdm
from matplotlib import pyplot as plt
from torchvision import transforms as tfms
from diffusers import StableDiffusionPipeline, DDIMScheduler
device = torch.device("mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available()
# Useful function for later
def load_image(url, size=None):
response = requests.get(url,timeout=0.2)
img = Image.open(BytesIO(response.content)).convert('RGB')
if size is not None:
img = img.resize(size)
return img
# Load a pipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5").to(device)
# Set up a DDIM scheduler
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)简而言之,DDIM采样是指在特定时间点,嘈杂的图像是原始图像与一些噪声的混合,其中噪声是具有单位方差的高斯噪声。在DDPM论文中,这个高斯噪声的参数被称为'alpha'(α),并且它定义了噪声调度器。在Diffusers中,通过计算alpha调度器的值并将其存储在scheduler.alphas_cumprod中来处理这些值。
# Plot 'alpha' (alpha_bar in DDPM language, alphas_cumprod in Diffusers for clarity)
timesteps = pipe.scheduler.timesteps.cpu()
alphas = pipe.scheduler.alphas_cumprod[timesteps]
plt.plot(timesteps, alphas, label='alpha_t');
plt.legend();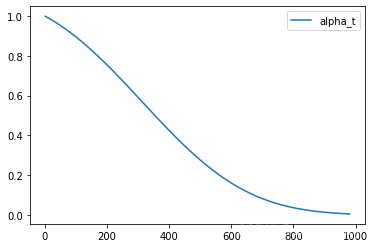
最初(时间步0,图表的左侧),我们从一个干净的图像开始,没有噪音。 随着时间步的增加,我们最终几乎全部都是噪音,并且噪音逐渐减少至接近0。
在采样过程中,我们从时间步1000开始,纯粹是噪音,然后慢慢移动到时间步0。为了计算采样轨迹中的下一个时间步(因为我们是从高时间步向低时间步移动),我们预测噪音(这是我们模型的输出),然后使用它来计算预测的去噪图像。然后我们使用这个预测来沿着指向某个方向的小距离移动。最后,我们可以添加一些额外的噪音,按照某个因子缩放。
因此,基于DDIM 的采样过程可以描述为以下代码:
# Sample function (regular DDIM)
@torch.no_grad()
def sample(prompt, start_step=0, start_latents=None,
guidance_scale=3.5, num_inference_steps=30,
num_images_per_prompt=1, do_classifier_free_guidance=True,
negative_prom 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2510
2510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









