







 本文深入探讨了 Stable Diffusion 的核心架构,包括 Latent Diffusion 和 Text Conditioning,介绍了如何通过 VAE 缩减计算需求,并利用文本编码器和 UNet 实现图像生成。Classifier-free Guidance 技巧提高了生成图像与文本提示的相关性,而 DIY 采样循环则允许自定义的生成流程。文章还涵盖了 Text Inversion 和模型微调,以及 Super-Resolution、Inpainting 和 Depth-to-Image 应用场景。
本文深入探讨了 Stable Diffusion 的核心架构,包括 Latent Diffusion 和 Text Conditioning,介绍了如何通过 VAE 缩减计算需求,并利用文本编码器和 UNet 实现图像生成。Classifier-free Guidance 技巧提高了生成图像与文本提示的相关性,而 DIY 采样循环则允许自定义的生成流程。文章还涵盖了 Text Inversion 和模型微调,以及 Super-Resolution、Inpainting 和 Depth-to-Image 应用场景。
任务三:
-
打卡内容:
-
学习笔记
-
作业:自行组装stable diffusion 并提交几个生成结果
-
Stable Diffusion 原理与实战
Stable Diffusion 的核心架构
Latent Diffusion

当我们处理的图像尺寸增大时,需要的计算能力也随之增加。特别是在执行一种叫做“自注意力”的操作时,所需的计算量会随着输入数量的增加而平方级增长。例如,一个128像素的正方形图像比64像素的正方形图像有4倍多的像素点,因此在自注意力层中它需要16倍(即4的平方)的内存和计算能力。对于希望生成高分辨率图像的人来说,这是一个大问题!
潜在扩散技术通过使用一个名为变分自编码器(VAE)的独立模型来缓解这个问题,它可以将图像压缩到更小的空间尺寸。这样做的理由是,图像往往包含大量的冗余信息——只要有足够的训练数据,我们希望VAE能够学习到一种方式,将输入图像压缩成一个更小的表示形式,然后基于这个小的潜在表示以高保真度重构原始图像。在SD中使用的VAE能够接收3通道的图像,并产生一个减少空间尺寸8倍的4通道潜在表示。也就是说,一个512像素的正方形输入图像将被压缩成一个4x64x64的潜在表示。
通过在这些潜在表示上应用扩散过程,而不是在全分辨率图像上进行,我们可以获得很多使用小图像时的好处(减少内存使用、UNet需要更少的层、更快的生成时间等),并且一旦我们准备好查看最终结果,还可以将结果解码回高分辨率图像。这项创新显著降低了训练和运行这些模型的成本。
想象一下,你有一张非常大的照片想要放进一个小相框里。如果直接放不进去,怎么办呢?你可能会想到要先缩小照片。在计算机图像处理中,当我们处理的照片越大,我们需要的计算机“力量”就越大。就像把一张超大的海报塞进小相框一样困难,我们的计算机也得费不少劲。
现在,科学家们发明了一种聪明的方法,就像一台能把照片变成缩略图的魔术机器。这台机器叫做变分自编码器(VAE),它可以把大图像变成小图像,同时尽量保留原图的所有重要信息。这样,我们的计算机就能更轻松地处理这些小图像了。就像用一张小照片代替海报放进相框,既节省了空间,又保留了我们想要的所有细节。
而且,当我们处理完这些小图像后,这台魔术机器还能把它们变回原来的大图像,而且质量出奇的好,就像从来没有被缩小过一样。这就意味着我们可以用更少的计算力做更多的工作,并且最后还能得到高清晰度的图片。
通过这种方式,科学家们显著降低了制作和运行这些高科技图像处理模型的成本,就像变魔术一样既神奇又实用!
具体实现方式: VAE
把一堆真实样本通过编码器网络变换成一个理想的数据分布,然后这个数据分布再传递给一个解码器网络,得到一堆生成样本,生成样本与真实样本足够接近的话,就训练出了一个自编码器模型。那VAE(变分自编码器)就是在自编码器模型上做进一步变分处理,使得编码器的输出结果能对应到目标分布的均值和方差,再在这个正态分布上进一步采样,得到采样变量,这个采样变量就等效于自编码器里的隐变量。
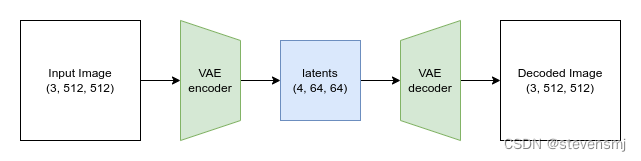
# Create some fake data (a random image, range (-1, 1))
images = torch.rand(1, 3, 512, 512).to(device) * 2 - 1
print("Input images shape:", images.shape)
# Encode to latent space
with torch.no_grad():
latents = 0.18215 * pipe.vae.encode(images).latent_dist.mean
print("Encoded latents shape:", latents.shape)
# Decode again
with torch.no_grad():
decoded_images = pipe.vae.decode(latents / 0.18215).sample
print("Decoded images shape:", decoded_images.shape)对应的输出结果如下:
Input images shape: torch.Size([1, 3, 512, 512])
Encoded latents shape: torch.Size([1, 4, 64, 64])
Decoded images shape: torch.Size([1, 3, 512, 512])此外,对于由 VAE 所编码的潜在表示,我们可以通过单独调用 `AutoencoderKL` 进行查看:
from diffusers import AutoencoderKL
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
# To the GPU we go!
vae = vae.to(torch_device)下面编码一个包装函数实现简单的 VAE 的编码和解码操作
def pil_to_latent(input_im):
# Single image -> single latent in a batch (so size 1, 4, 64, 64)
with torch.no_grad():
latent = vae.encode(tfms.ToTensor()(input_im).unsqueeze(0).to(torch_device)*2-1) # Note scaling
return 0.18215 * latent.latent_dist.sample()
def latents_to_pil(latents):
# bath of latents -> list of images
latents = (1 / 0.18215) * latents
with torch.no_grad():
image = vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
return pil_images现在输入 macaw 的图片,展示 VAE 的压缩效果:

# Download a demo Image
!curl --output macaw.jpg 'https://lafeber.com/pet-birds/wp-content/uploads/2018/06/Scarlet-Macaw-2.jpg'
# Load the image with PIL
input_image = Image.open('macaw.jpg').resize((512, 512))
input_image
# Encode to the latent space
encoded = pil_to_latent(input_image)
encoded.shape
# Let's visualize the four channels of this latent representation:
fig, axs = plt.subplots(1, 4, figsize=(16, 4))
for c in range(4):
axs[c].imshow(encoded[0][c].cpu(), cmap='Greys') 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 26
26

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









