







1. 简介
YOLO是单阶段(one-stage)目标检测的开山之作。
此前双阶段(two-stage)目标检测是需要先产生大量的包含待检测物体的先验框,然后使用分类器判断每个先验框对应的边界框是否包含待检测的物体,以及物体所属类别的概率或置信度,同时需要后处理修正边界框,最后基于一些准则过滤掉置信度不高和重叠度较高的边界框,进而得到最终的检验结果,这就导致检测速度不能满足实时性。
YOLO就是打破这种“产生候选区”+“检测“”的双阶段思想,直接将两个阶段合二为一,将目标检测转变成一个回归问题,利用整张图作为网络输入,仅经过一个神经网络就得到bounding box(边界框)的位置和所属类别。
2.网络结构
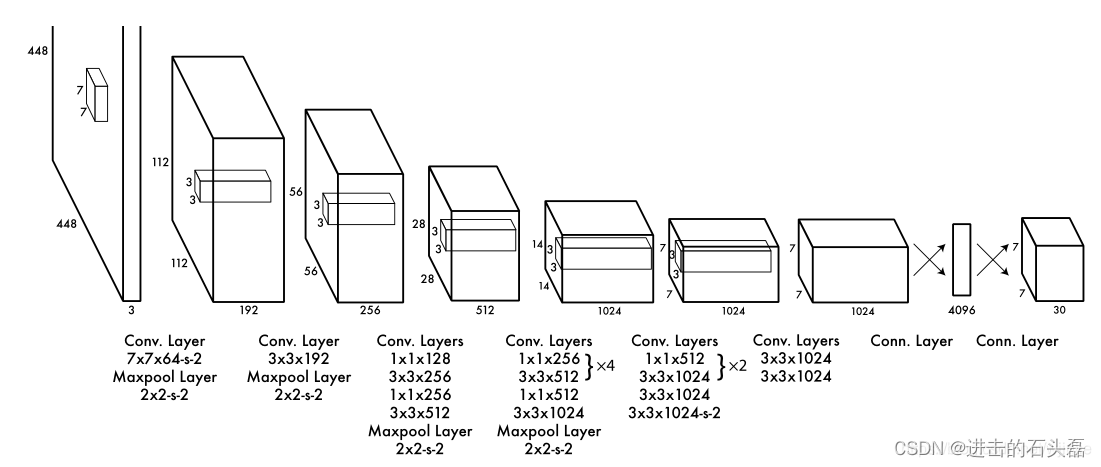
Yolo网络借鉴了GoogleNet分类网络结构,不同的是YOLO使用1x1卷积层和3x3卷积层替代inception module。如上图所示,整个检测网络包括24个卷积层和2个全连接层,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
- 网络输入:448*448*3的彩色图片
- 中间层:若干卷积层和最大池化层组成,用于提取图片的特征
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值
- 网络输出:7*7*30的预测结果
3.算法原理

(1)将图像分成S*S个网络(grid cell),如果某个object的中心落在这个网格中,则这个网格就要负责预测这个object;
(2)每个网格要预测B个bounding box,每个bounding box要预测(x, y, w, h)和confidence共5个值;
(3)每个网格还要预测一个类别信息,记作C个类;
(4)总的来说,S*S个网格,每个网格要预测B个bounding box,还要预测C个类别。网络输出就是一个S*S*(5*B+C)的张量
(5)在实际过程中,yolov1把一张图片划分为7*7个网格,每个网格预测2个bounding box,20个类别,因此网络输出就是7*7*30
4. 算法优缺点
优点:
(1)yolo检测物体非常快,实时检测的精度也比其他检测系统快
(2)yolo可以很好的区分背景和物体,不像其他物体检测使用滑窗或者region proposal,分类器只能得到局部图像的局部信息,yolo在训练和测试时都可以看到一整张图像的信息,因此YOLO可以更好地利用上下文信息
(3)YOLO具有高度泛化能力,迁移能力强,能运用到其他的新的领域
缺点:
(1)YOLO对于相互靠近的物体,以及很小的群体检测效果不好,这是因为一个网格只预测了2个框,并且都只属于同一个类
(2)位置精确性差,容易产生物体的定位错误,输入尺寸固定
(3)YOLO虽然可以降低将背景检测为物体的概率,但同时导致召回率较低
参考资料:















 318
318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









