







可信多模态分类
ICLR 2021
paper: https://arxiv.org/pdf/2102.02051v1.pdf
code: https://github.com/hanmenghan/TMC
摘要
多视图分类 (MVC) 通常侧重于通过使用来自不同视图的信息来提高分类精度,通常将它们集成到下游任务的统一综合表示中。然而,动态评估不同样本的视图质量也很重要,以便提供可靠的不确定性估计,这表明预测是否可信。为此,我们提出了一种新的多视图分类方法,称为可信多视图分类,它通过在证据层动态集成不同的视图,为多视图学习提供了一种新的范式。该算法通过整合来自每个视图的证据,联合利用多个视图来提高分类的可靠性和鲁棒性。为了实现这一点,狄利克雷分布被用来模拟类概率的分布,用来自不同观点的证据进行参数化,并与Dempster-Shafer理论相结合。统一的学习框架引入了精确的不确定性,并相应地赋予模型对分布外样本的可靠性和鲁棒性。大量实验结果验证了该模型在准确性、可靠性和鲁棒性方面的有效性。
1.引言
多视图学习中,当呈现的视图没有得到很好的表示时,通常容易产生不可靠的预测。传统算法通常假设不同视图的值相等,或者为每个视图分配/学习固定的权重,前提是这些观点的质量或重要性对于所有样本来说基本上是稳定的。在现实中,对于不同的样本,视图的质量通常是不同的,我们除了知道预测结果外,还应该知道这个结果的可信度。
基于不确定性的算法可以大致分为两大类,即贝叶斯和非贝叶斯方法。传统的贝叶斯方法通过推断参数的后验分布来估计不确定性,包括拉普拉斯近似、马尔可夫链蒙特卡罗(MCMC) 和变分技术。然而,与普通神经网络相比,由于模型参数加倍和收敛困难,这些方法计算量很大。最近的算法通过在测试阶段引入dropout来估计不确定性,从而降低计算成本。已经提出了几种非贝叶斯算法,包括深度集成、证据深度学习和确定性不确定性估计。所有这些方法都侧重于估计单视图数据的不确定性,尽管通过不确定性融合多个视图可以提高性能和可靠性。
本文提出了一种新的多视图分类算法,旨在为可信决策集成多视图信息。在证据层次上结合了不同的视图,这产生了稳定和合理的不确定性估计,从而提高了分类的可靠性和鲁棒性。(当输出的不确定性过高时可以通过人为决策等手段,降低风险)
贡献:
- 提出了一种新的多视图分类模型,旨在以有效和高效的方式(无需任何额外的计算和神经网络改变)提供可信和可解释的(根据每个视图的不确定性)决策,这在多视图分类中引入了一种新的范式。
- 所提出的模型是一个有前途的样本自适应多视图集成的统一框架,它以一种可优化(可学习)的方式在证据水平上集成多视图信息和Dempster-Shafer理论。
- 每个视图的不确定性被精确估计,使我们的模型能够提高分类的可靠性和鲁棒性。
- 进行了广泛的实验,验证了我们的模型由于良好的不确定性估计和多视图集成策略而具有卓越的准确性、鲁棒性和可靠性。
2. 相关工作
基于不确定性的学习。 深度神经网络在各种任务中取得了巨大的成功。然而,由于大多数深度模型本质上是确定性函数,因此无法获得模型的不确定性。贝叶斯神经网络(BNNs)通过用分布代替确定性权重参数,赋予深度模型不确定性。由于贝叶斯网络在执行推理方面存在困难,并且通常具有令人望而却步的计算成本,因此提出了一种更具可扩展性和实用性的方法——MC-dropout。在这个模型中,推理是通过在训练和测试过程中对权重进行缺失采样来完成的。基于集成的方法训练和集成多个深度网络,并实现有前途的性能。该算法引入主观逻辑理论,无需集成或蒙特卡洛采样,直接对不确定性建模,而不是通过网络权重间接建模。在径向基函数网络的基础上,测试样本和原型之间的距离可以用作确定性不确定性的代理。从同态不确定性学习的不同任务的学习权重中获益,在多任务学习中取得了令人印象深刻的表现。
多视角学习。 多视图数据学习在各种任务中被证明是有效的。基于CCA的多视图模型是在多视图表示学习中已经广泛使用的代表性算法。这些模型本质上是通过最大化不同视图之间的相关性来寻求共同的表示。考虑到公共和排他信息,分层多模态度量学习(HM3L)明确地学习共享多视图和视图特定的度量,而AE2-Nets隐含地学习用于分类的完整(视图特定和共享多视图)表示。最近,方法也取得了不错的成绩。由于其有效性,多视图学习已经广泛应用于各种应用中。
DempsterShafer证据理论(DST)。 DST是一种关于信念函数的理论,最早由登普斯特提出,是贝叶斯理论对主观概率的推广。后来,它被发展成一个通用的框架来模拟认知不确定性。贝叶斯神经网络通过对权重参数的多次随机采样间接获得不确定性,而DST则直接对不确定性建模。DST允许来自不同来源的信念与各种融合算子相结合,以获得考虑所有可用证据的新信念。当面对来自不同来源的信念时,登普斯特的组合规则试图融合它们共有的部分,并通过归一化因子忽略冲突的信念。
3. 方法

整体框架可以分为三个部分:
- 证据估计(框架图的①)——非负神经网络
- 意见生成(框架图的②③)——狄利克雷类分布
- 多源融合(框架图的④)——DS证据融合理论
3.1 不确定性和证据理论:
在多类分类的背景下,主观逻辑(SL)将狄利克雷分布的参数与信念分布相关联,其中狄利克雷分布可以被认为是分类分布的共轭先验。我们阐述了主观逻辑,它定义了一个理论框架,用于基于从数据中收集的证据获得不同类别的概率(belief masses)和多分类问题的总体不确定性(uncertainty mass)。对于K分类问题,主观逻辑理论试图基于证据为每个类别标签分配一个置信概率质量,并为整个框架分配一个总体不确定概率质量。(不确定性:描述分类分布的不确定性。用狄利克雷类分布描述分布。)对于第v个视图,K + 1的mass值都是非负的,它们的和为1:
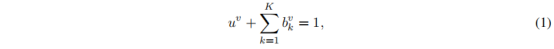
u
v
u^{v}
uv:不确定性 ;
b
k
v
b_{k}^{v}
bkv:概率
对于第v个视图,主观逻辑将证据
e
v
=
[
e
1
v
,
.
.
.
,
e
K
v
]
e^{v}=[e_{1}^{v},...,e_{K}^{v}]
ev=[e1v,...,eKv]连接到狄利克雷分布
α
v
=
[
α
1
v
,
.
.
.
,
α
K
v
]
\alpha^{v}=[\alpha _{1}^{v},...,\alpha _{K}^{v}]
αv=[α1v,...,αKv]的参数(图1(a)中的②)。具体地,Dirichlet分布的参数
α
k
v
\alpha_{k}^{v}
αkv由
e
k
v
e_{k}^{v}
ekv导出,即
α
k
v
=
e
k
v
+
1
\alpha_{k}^{v}=e_{k}^{v}+1
αkv=ekv+1(这里的1是任意取的常量)。然后,置信质量
b
k
v
b_{k}^{v}
bkv和不确定性
u
v
u^{v}
uv(图1(a)中的步骤3)被计算为:
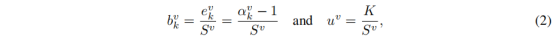
其中
S
v
=
∑
i
=
1
K
(
e
i
v
+
1
)
=
∑
i
=
1
K
α
i
v
S^{v}=\sum_{i=1}^{K}(e_{i}^{v}+1)=\sum_{i=1}^{K}\alpha _{i}^{v}
Sv=∑i=1K(eiv+1)=∑i=1Kαiv是狄利克雷强度。
公式2表明:证据足够强时,不确定性可以忽略(趋于0);证据非常弱时,不确定性变为极大(趋于1)。

狄利克雷分布的例子:
在三分类任务下,假设e = <40,1,1>,因此我们有α = <41,2,2>。相应的狄利克雷分布,如图2(a)所示,产生一个以标准2-单形顶部为中心的尖锐分布。这表明已经观察到足够的证据来确保准确的分类。(b)表示分类证据很少,©中每个证据都很高,相应不确定性变高,(d)我们基于主观逻辑理论将一个狄利克雷分布转化为一个标准的3-单形(在
R
4
R^{4}
R4有顶点(1,0,0,0),(0,1,0,0),(0,0,1,0)和(0,0,0,1)的正四面体)。其中单形中对应于
{
{
b
k
}
i
=
1
3
,
u
}
\left \{ \left \{ b_{k} \right \}_{i=1}^{3},u \right \}
{{bk}i=13,u}的点(M)表示一个意见。相应地,狄利克雷分布的期望值p是M在底部的投影。
3.2 多视图分类的Dempster组合规则
图1(a)中的④
我们需要组合V个独立的概率质量赋值集合
{
M
v
}
1
V
\left \{ M^{v} \right \}_{1}^{V}
{Mv}1V,其中
M
v
=
{
{
b
k
v
}
k
=
1
K
,
u
v
}
M^{v}=\left \{ \left \{ b_{k}^{v} \right \}_{k=1}^{K},u^{v} \right \}
Mv={{bkv}k=1K,uv},以获得连接块
M
=
{
{
b
k
}
k
=
1
K
,
u
}
M=\left \{ \left \{ b_{k} \right \}_{k=1}^{K},u \right \}
M={{bk}k=1K,u}。
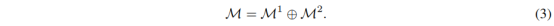
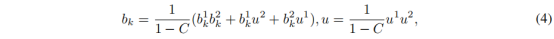
其中,
C
=
∑
i
≠
j
b
i
1
b
j
2
C=\sum_{i\neq j}^{}b_{i}^{1}b_{j}^{2}
C=∑i=jbi1bj2是两个质量组(图1(b)中的白色块)之间冲突量的度量,比例因子
1
1
−
C
\frac{1}{1-C}
1−C1用于标准化。(如图1(b)所示)
证据理论融合合理性:
- 当两种模态不确定性都较高时,最终分类一定是低置信度;
- 当两种模态不确定性都较低时,最终分类一般是高置信度;
- 当仅有一种模态不确定性较低时,最终分类是高可信度;
- 当两种模态决策冲突时,最终分类可信度降低。
使用主观逻辑相比softmax的优势:与softmax输出相比,使用主观不确定性更适合多决策的融合。主观逻辑提供了一个额外的mass函数(u),允许模型区分缺乏证据。在我们的模型中,主观逻辑提供了每个视图的总体不确定程度,这在某种程度上对于可信分类和可解释性很重要。
3.3 学会形成观点
图1(a)中的①
在这一节中,我们将讨论如何训练神经网络来获得每个视图的证据。神经网络可以从输入中捕获证据以诱导分类意见,并且传统的基于神经网络的分类器可以自然地转换为基于证据的分类器,只需稍加更改。具体地,传统的基于神经网络的分类器的softmax层被激活函数层(即,ReLU)代替,以确保网络输出非负值,这些值被认为是证据向量。因此,可以获得狄利克雷分布的参数。
训练与优化:
- 传统交叉熵损失:
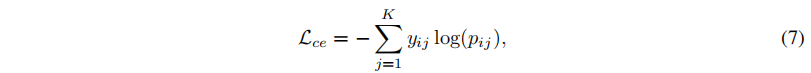
- 调整交叉熵损失(在狄利克雷类分布上积分):
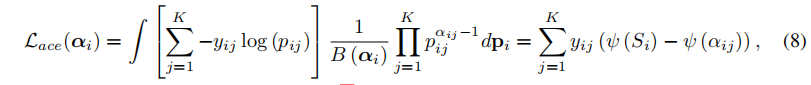
- 加入正则约束(狄利克雷类分布先验信息融入,抑制不合理分布):
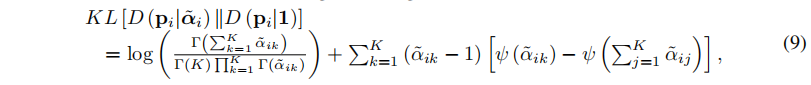
- 得到单模态损失:
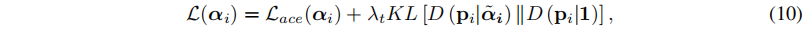
- 总损失:
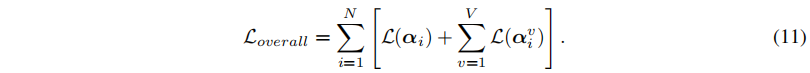
4. 实验结果


















 2123
2123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









