







视觉表示学习的多模态对比训练
paper: https://arxiv.org/pdf/2104.12836v1.pdf
code: 暂无
摘要
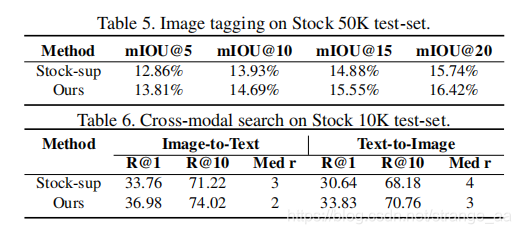
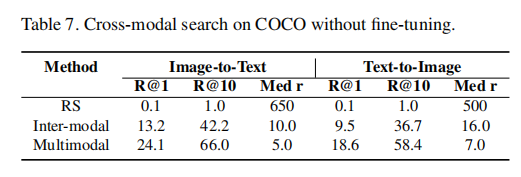
我们开发一种学习视觉表示的方法,该方法包含多模态数据,并结合了模态内部和模态间相似性保存目标。与在单个域中解决代理预测任务的现有视觉预训练方法不同,我们的方法同时利用每个模态和语义信息中的内在数据属性,从而提高所学视觉表示的质量。 通过将多模态训练包含在具有不同类型对比损失的统一框架中,我们的方法可以学习更强大和通用的视觉特征。我们首先对 COCO 模型进行训练,并评估在图像分类、目标检测和实例分割等各种下游任务上所学的视觉表示。例如,在通用传输协议下,通过我们的方法在COCO上预先训练的视觉表示在ImageNet分类上实现了55.3%的最好的top-1精度。我们还在大规模Stock images数据集上评估了我们的方法,并展示了它在多标签图像标记和跨模态检索任务中的有效性。
1. 引言
文章旨在在统一的训练框架中从多模态数据中学习视觉表示。框架设计应具有以下基本属性:
(1)以自我监督的方式充分挖掘每个未标记模态中数据的潜在信息;
(2)通过在具有相似性保持目标的公共语义空间中比较不同模态来弥合异质性差距;
(3)可以很容易地扩展到采用任何新的模态。
在本文中,我们对多模态数据中的模态内和模态间相似性保持采取统一的观点,在此基础上我们开发了一个新的视觉表示学习框架(图1)。具体来说,模态内训练路径用于在预测任务中捕获增强数据示例的内在模式。模态间训练方案通过包含跨模态交互来增强视觉特征。通过精心设计的对比损失,所有模态的特征都可以通过在多个训练路径中反向传播来调整。
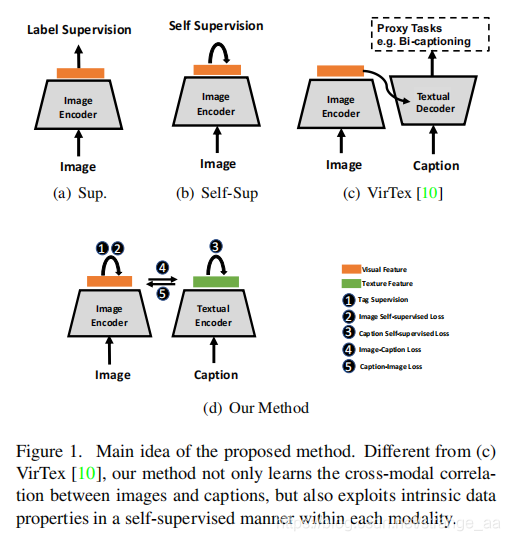
主要贡献点如下:
- 统一多模态训练。 我们的多模态训练框架可以利用每个模态的内在数据属性,同时从跨模态相关性中提取语义信息。此外,我们的框架对所有模态都是对称的,这表明它具有合并任何新模态的灵活性。
- 广泛的可转移性。 通过我们的方法预处理的视觉表征可以被转移到许多下游的计算机视觉任务中,并且在普通的转移学习协议下取得了优异的性能。
2. 相关工作
- 自监督学习: memory bank, NCE, MoCo, SimCLR, MoCo-v2
- 视觉-文本联合预处理: 针对VL任务的微调BERT来学习联合视觉-文本空间;利用NCE和MIL-NCE损失来学习跨视频、语言和音频模式的表示。
- 语言指导的视觉表征学习: Virtex, ICMLM
3. 方法
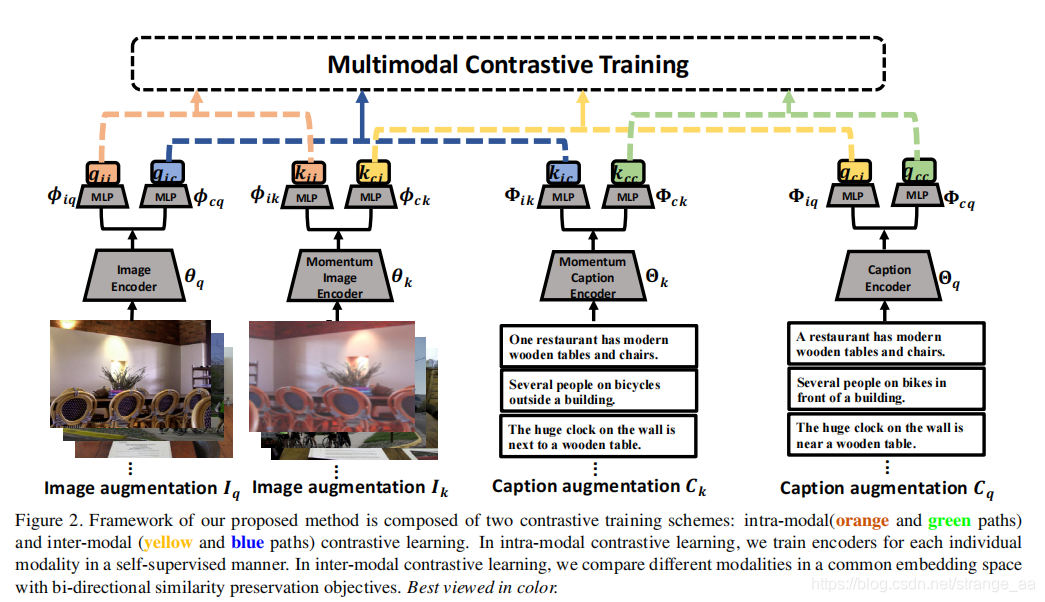
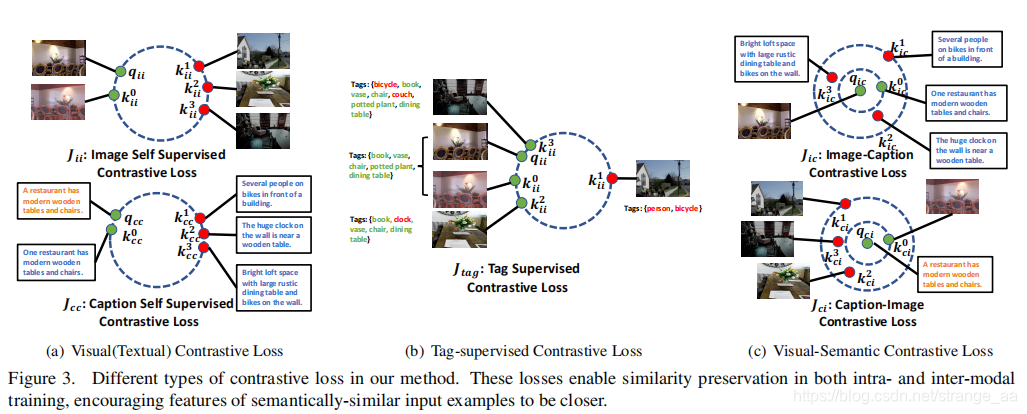
图2为提出的的多模态对比训练框架的整体架构。该系统由两种对比训练方案组成:模态内(橙色和绿色路径)和模态间(黄色和蓝色路径)对比学习,损失类型不同,如图3所示。
模态内的训练基于MoCo-v2。跨模态训练方案旨在通过包含跨模态交互来增强视觉特征。我们首先将视觉和文本特征嵌入到一个公共空间中。然后,我们设计了一个视觉语义对比损失,以迫使语义相似的输入示例的特征更加接近。因此,视觉特征将通过反向传播根据字幕进行调整,反之亦然。请注意,我们使用不同的MLP层进行跨模态特征嵌入,以便两种模态内和模态间训练方案不会相互干扰。通过这两个训练方案的组合,我们可以学习强大而通用的视觉表现。尽管所提出的方法也作为副产品产生有用的文本特征,但它不是本文的主要焦点。多模态对比训练完成后,视觉编码器可以直接应用于或微调各种下游任务。
3.1 模态内对比学习
定义
D
=
{
(
I
j
,
c
j
,
t
j
)
}
\ D=\left \{ (I_{j},c_{j},t_{j}) \right \}
D={(Ij,cj,tj)}
其中,
I
j
\ I_{j}
Ij为图像,
c
j
\ c_{j}
cj为文本,
t
j
\ t_{j}
tj为标签。
视觉对比学习:
定义图像编码器
f
i
q
(
⋅
;
θ
q
,
ϕ
i
q
)
)
\ f_{iq}(\cdot ; \theta _{q},\phi _{iq}))
fiq(⋅;θq,ϕiq))和动量图像编码器
f
i
k
(
⋅
;
θ
k
,
ϕ
i
k
)
)
\ f_{ik}(\cdot ; \theta _{k},\phi _{ik}))
fik(⋅;θk,ϕik)),其中
θ
\ \theta
θ和
ϕ
\ \phi
ϕ分别是CNN主干和2层MLP head的权重,用动量系数m更新:
θ
k
←
m
θ
k
+
(
1
−
m
)
θ
q
\ \theta _{k} \leftarrow m\theta _{k}+ (1-m)\theta _{q}
θk←mθk+(1−m)θq,
ϕ
i
k
←
m
ϕ
i
k
+
(
1
−
m
)
ϕ
i
q
\ \phi _{ik} \leftarrow m\phi _{ik}+ (1-m)\phi _{iq}
ϕik←mϕik+(1−m)ϕiq。该符号不同于MoCo-v2,后者将编码器权重作为一个整体,因为我们需要将主干特征映射到不同的空间,将特征嵌入从模态内和模态间训练路径中分离出来。对于一个图像的增强样本
I
j
†
\ I_{j}^{\dagger }
Ij†和
I
j
∗
\ I_{j}^{*}
Ij∗,图像编码器和动量编码器将它们嵌入query和key特征:
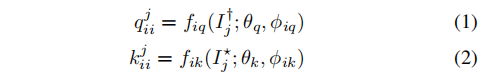
然后,通过动态队列来维护长度为K的一组动态关键特征。对于当前mini batch中的query特征
q
i
i
\ q_{ii}
qii,如果队列中的key特征
k
i
i
\ k_{ii}
kii能够与其形成正对,即它们源自同一图像,则该key特征被表示为
k
i
i
+
\ k_{ii}^{+ }
kii+。自监督对比损失定义为:
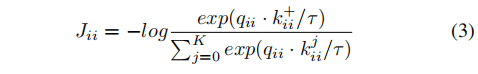
考虑到两个样本语义非常相似的时,相应的特征也会相似,设计了额外损失项:
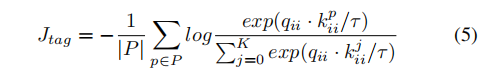
其中,P为
{
k
i
i
+
}
\ \left \{ k_{ii}^{+} \right \}
{kii+}的扩展,|P|为P的大小:
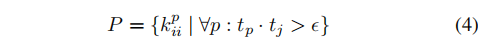
文本对比学习:
文本编码器的架构采用类似BERT的transformer结构。采用反向翻译进行数据增强。对比损失形式与视觉对比学习类似。
3.2 模态间对比学习
首先将图像和文本的表示嵌入到公共空间中,然后使用基于排名的对比损失来学习视觉和文本模型参数。如图3©所示,目标函数鼓励ground truth文本图像对的相似性大于所有其他负对的相似性,而不是仅仅解决一个难预测任务。
图像到字幕的对比学习:
给定图像-字幕对
(
I
j
,
c
j
)
\ (I_{j},c_{j})
(Ij,cj),我们使用图像编码器生成query特征,使用动量文本编码器生成key特征,然后将它们映射到公共空间。
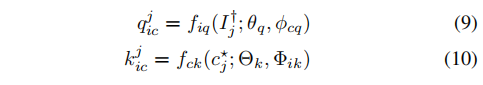
定义正对 kic,qic,我们的目标是同时最小化
q
i
c
\ q_{ic}
qic和
k
i
c
+
\ k_{ic}^{+}
kic+之间的距离,并最大化
q
i
c
\ q_{ic}
qic与队列中所有其他负key特征之间的距离。因此,我们将图像-字幕对比损失表述为:
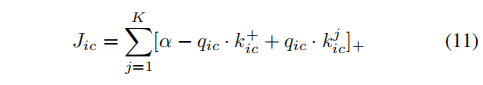
其中α为边距,点积表示相似度得分,[x]+表示max(x,0)。
字幕到图像的对比学习:
与图像到字幕的对比学习相似。
4. 实验结果
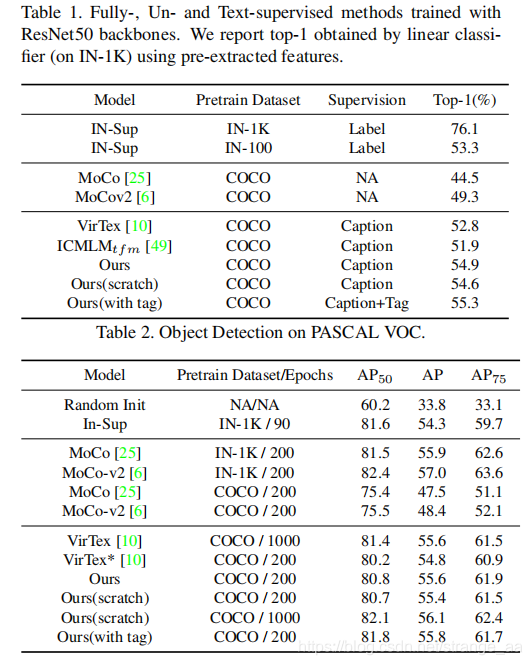
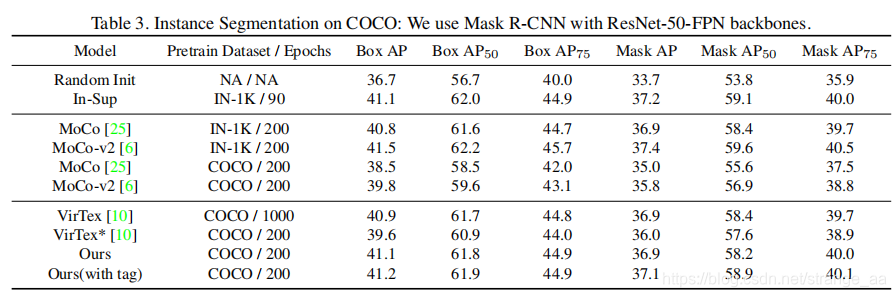
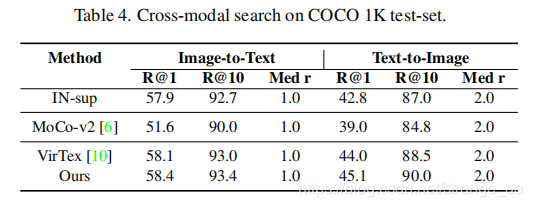

















 2052
2052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









