







 本文概述了大模型增量微调的发展,主要介绍了添加式(如适配器和提示微调)、指定式(如仅优化特定层)和重参数化(如LoRA)三种方法。这些方法通过高效地调整部分参数,实现了在保持模型结构不变的情况下提升性能。
本文概述了大模型增量微调的发展,主要介绍了添加式(如适配器和提示微调)、指定式(如仅优化特定层)和重参数化(如LoRA)三种方法。这些方法通过高效地调整部分参数,实现了在保持模型结构不变的情况下提升性能。
大模型增量微调发展至今,已经涌现出一系列方法,尽管这些方法可能有不同的模型结构和训练策略,但它们都秉承参数高效的基本原则。根据具体的训练策略,可以将增量微调分为三大类:添加式方法、指定式方法和重参数化方法。
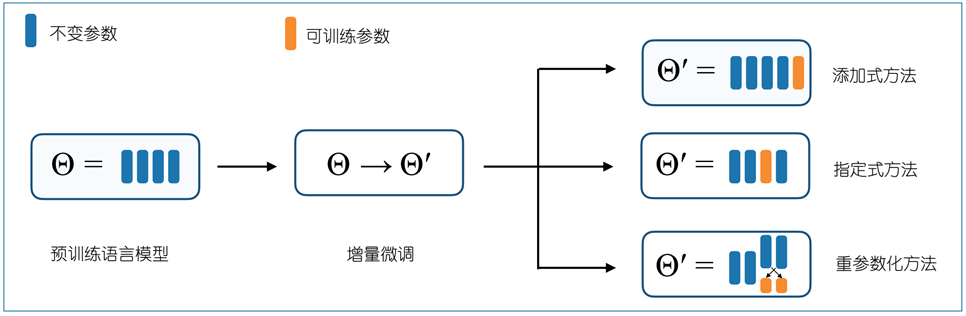
添加式方法会在模型中引入本身不存在的参数,并且只训练额外引入的这部分参数而保持其他参数不变;指定式方法则是指定模型中一部分特定的参数可训练,而保持其他参数不变;重参数化方法稍有不同,它是将模型的适配过程(或者是参数的变化)重新转化为一个参数高效的形式,如低维或者低秩的形式。
一、添加式方法
添加式增量微调方法是在大模型中添加额外的参数,但这些参数的位置和结构可能会有所不同。
1、适配器微调
适配器微调(adapter-tuning)是增量微调的开创性工作。这种方法的核心思想是在大模型中插入轻量级的神经网络模块,即适配器。在下游适配的过程中,仅对这些适配器的参数进行优化,其他参数保持不变。具体而言,一个适配器包括一个下投影线性层、一个非线性激活层和一个上投影线性层。适配器微调首次证明了仅调整0.5%~8%的参数即可达到与全参数微调相当的效果。在此基础上,适配器微调又衍生出了一系列的变体,如将适配器的参数复杂度从O(kr)降低到O(d+r)的Compacter方法,以及将适配器移出模型本身在模型之外进行单独优化的梯侧调整(Ladder
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6315
6315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









