







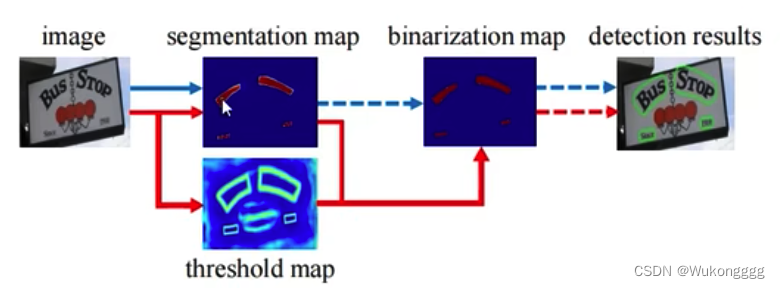
分割方法在文本检测中非常常见. 分割可以对付弯曲的情况. 分割: 对每个像素点做分类. 分割方法现状的缺点: 后处理方式要过滤, 比较麻烦 . 是不是文本的问题,属于二分类, 设定阈值.
DB: 可微分二值化. 创新点: 阈值不再固定的值,而是通过网络学习出来的自适应的值. DB自适应阈值的优点: 速度快.
ocr第一步: 找到文字在哪. 第二步分类.
DB: 传统路径中, 会对每个点生成一个概率, 再用二值图过滤. 如下图, 传统方法:蓝色. DB创新方法:红色.
网络过程:
先不断地进行下采样,获取不同的stage. 然后再对深层分别上采样,融合到浅层特征图中.
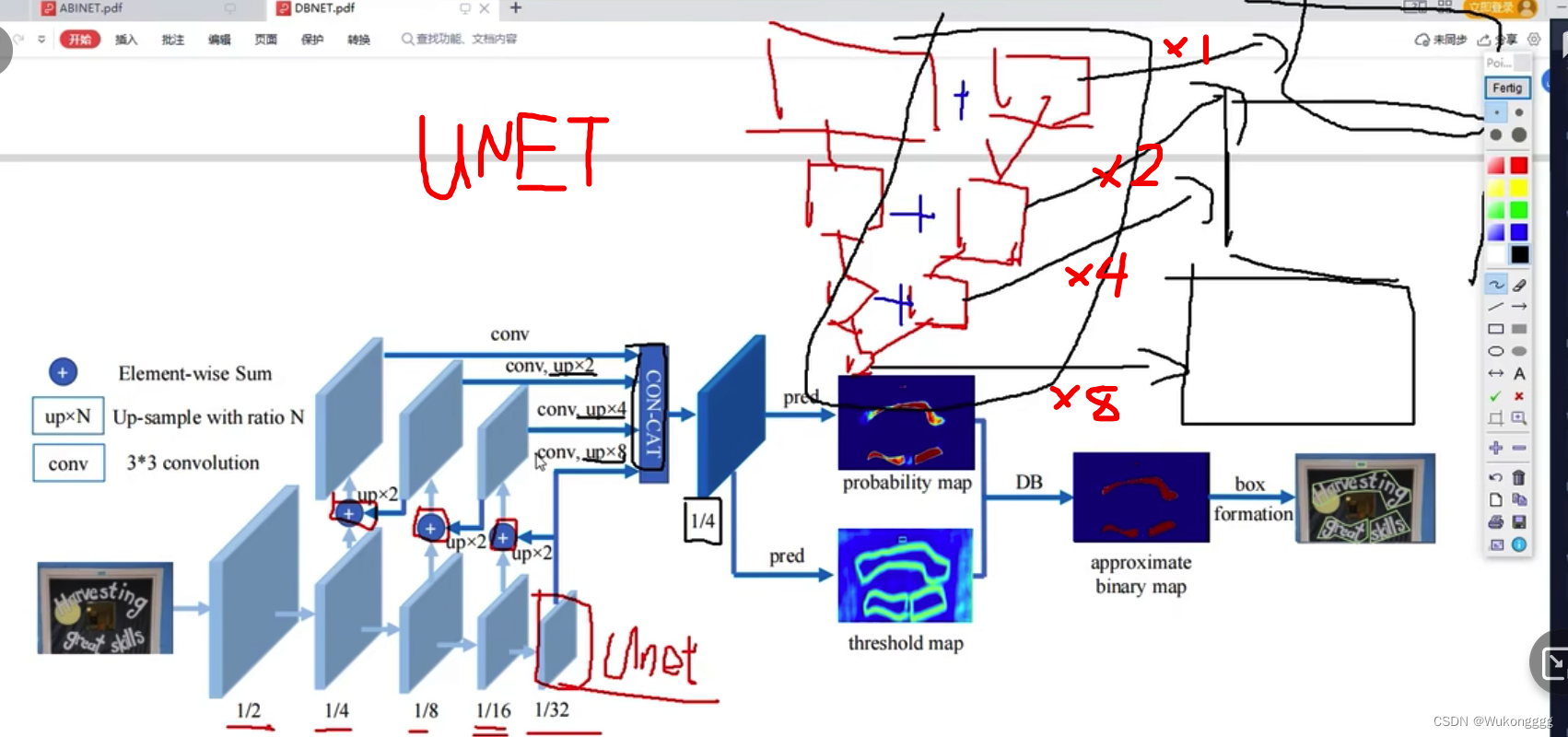
backbone层: 负责提取特征,不断进行下采样
neck层: 对特征进行整合拼接
head输出层:
概率图: 对每一个点的位置做一个多分类,得到一个概率图.
阈值图: 陪练的. 使模型知道边界在哪
到底是两个字段? 还是一个带空格的一个字段? 方法: 把检测框的尺寸往里缩, 检测框变小后, 检测框之间的距离变大, 防止将两个字段识别为一个字段, 让不同字段之间的边界更加清晰

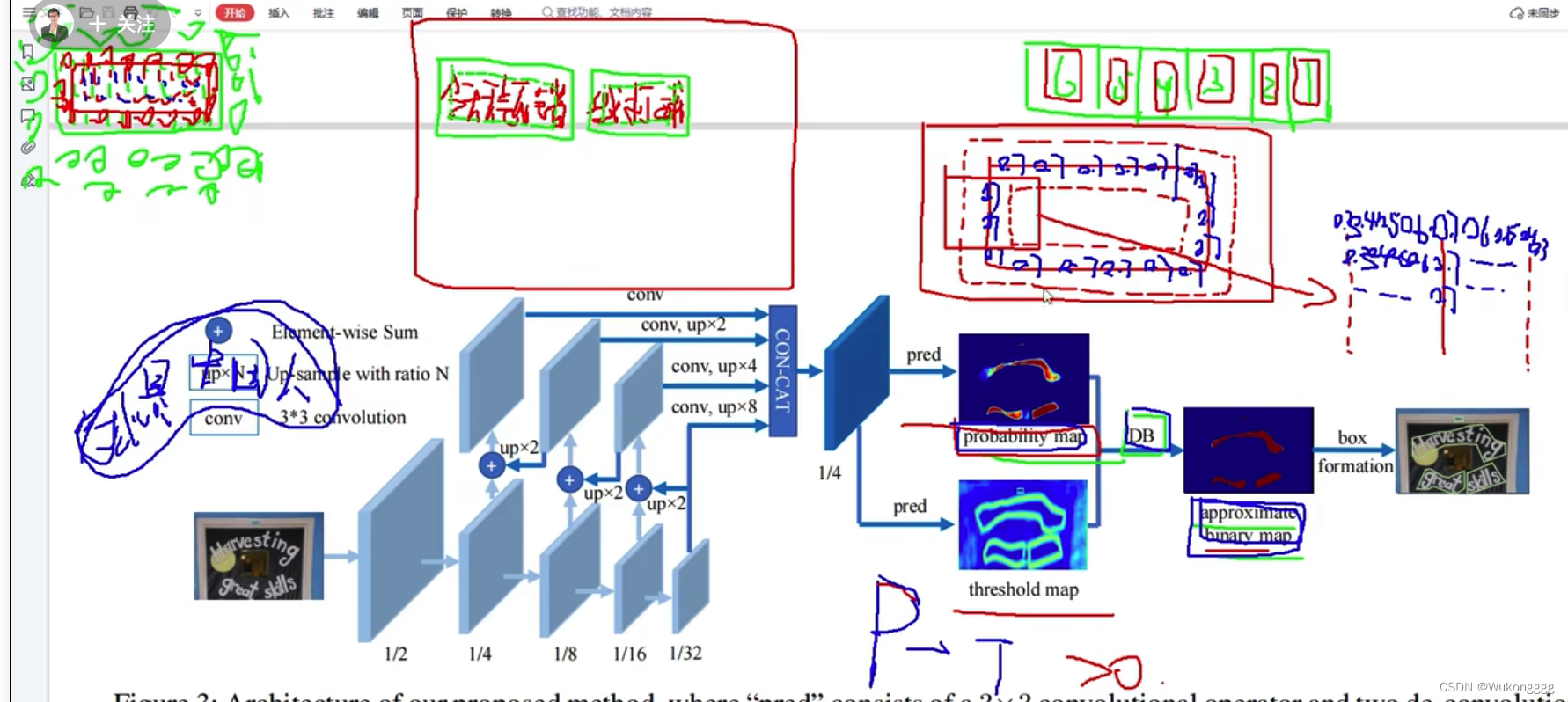
大于阈值的就是文字区域. 小于阈值的就是背景区域.
SB是标准二值化. 即大于0时为1, 小于0时为0.
把一个不可微的东西变成可微的.
k设为一个经验值50.
loss: 交叉熵损失的变异
和sigmoid的区别, sigmoid传入的是概率值, 这里的b传入的是概率值减去边界t之差.
CTPN:找到“广告招商”位置。 文本检测本质上也属于物体检测。
CRNN:“广告招商”第一个字、第二个字等都是什么字

文字是个变长序列,有的单词长度长,有的单词长度短。方法:切分为n个区域,然后判断每个框中内容是否为文字。最后将是文字的部分拼接在一起。















 6432
6432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









