







摘要
在数字艺术与人工智能的交汇点上,Stable Diffusion 3(SD3)的开源无疑是一场技术革新的盛宴。就在3月份,我撰写了一篇博文,深入探讨了SD3的技术报告内容与介绍,文章发表在CSDN博客上,https://blog.csdn.net/sunbaigui/article/details/136898729。如今,随着SD3 Medium版本的开源,https://huggingface.co/spaces/stabilityai/stable-diffusion-3-medium,我们迎来了新的里程碑。在本文中,我将分享我对这一开源版本的初步体验,以及它对文生图开源社区所带来的影响。Stable Diffusion 3 Medium的开源是一个重要的技术里程碑,它不仅展示了AI在图像生成领域的最新进展,也为未来的艺术创作和技术开发提供了丰富的土壤。虽然仍有挑战需要克服,但我相信,通过社区的共同努力和不断的技术创新,我们将能够解锁更多的创造潜力,开拓数字艺术的新境界。
体验与分析
为了确保体验的一致性和可复现性,我在所有样例中使用了相同的随机数种子——"888888888"。这一决定让我能够更准确地评估SD3 Medium的性能,并与其他用户的结果进行比较。
图像文字与背景的突破
SD3 Medium在图像文字和背景生成方面取得了显著的进步。它能够更好地理解和执行复杂的文本提示,生成的图像在视觉美学、提示遵循和排版方面都有了显著提升。这不仅推动了整个社区在图像生成技术上的发展,也为未来的艺术创作提供了更多可能性。
前景主体及其交互动作的挑战
尽管在图像文字和背景上取得了成功,SD3 Medium在前景物体、尤其是人物与物体的交互方面仍有提升空间。在一些生成的图像中,前景主体细节部分往往容易出错,尤其是躯干/手指等,另外物体间的交互动作也需进一步优化。这些挑战提示我们,尽管技术取得了巨大进步,但在实现高度逼真的图像生成方面,仍需不断地研究和提升。
样例1:
An astronaut riding a green horse
首先我们先看下官方样例结果:

在这个官方样例效果还不错,不过如果放开随机种子,多生成几次的话,局部细节不良率比较高。
样例2:
The elderly person sits on a wrought-iron chair, holding a glass of wine, facing the sea where spring is warm and flowers are blooming, at a seaside holiday home, with flowers and the sea around, savoring the fine wine while looking towards the coast.
再让我们看几个自定义文本输入的结果,纯中文的结果较差,我们通过kimi做一道英文翻译,再将相应英文描述输入到stable-diffusion-3-medium中,看相应结果:

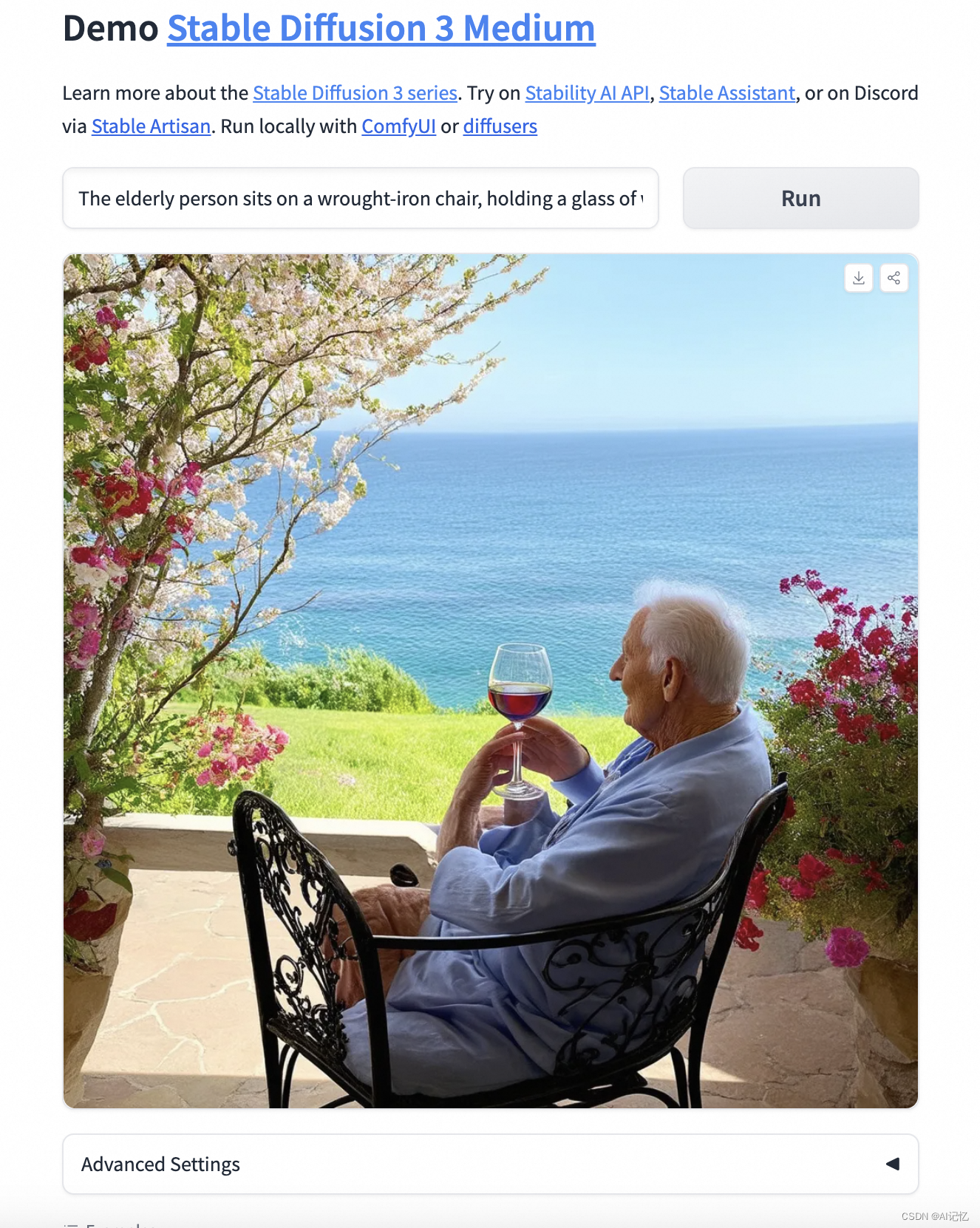
老人的手部和腿部都有一些问题,词意理解的比较到位,图像中的背景生成细节丰富。
样例3:
Create a poster with the "FaceChain" inscription at the center, and a Chinese dragon soaring through clouds and mist above it.

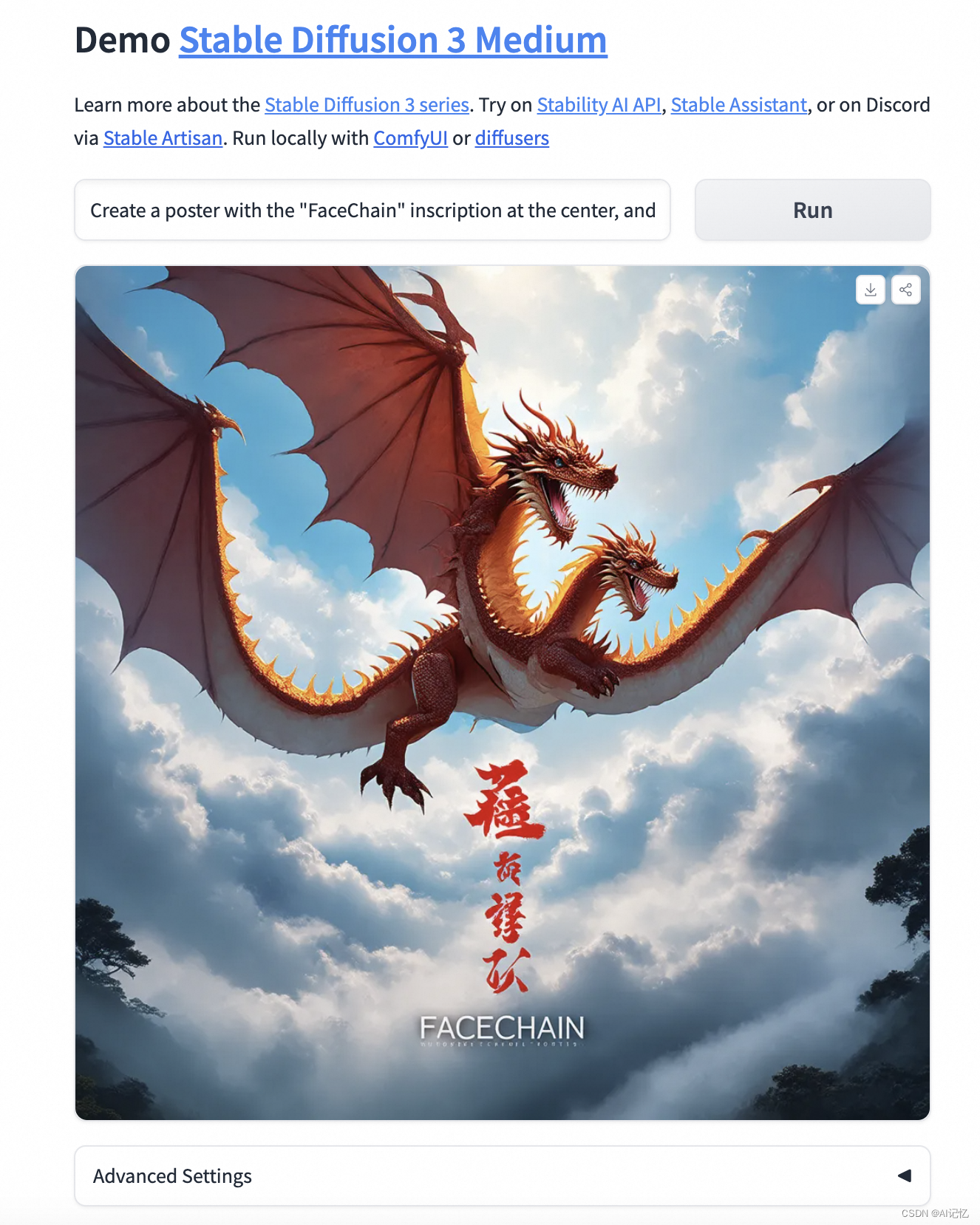
这里龙的局部包括龙头、龙翼、龙爪都有些个数与展示的不合理。但这边对FaceChain字样在图中的标识值得点赞,跟原技术报告中强调较强的图中文字嵌入能力是一致的,另外图中背景也理解到位。
样例4:
Spider-Man is engaged in a fierce battle with a Transformer, set against the backdrop of the Amazon rainforest. Spider-Man fires a web from his hand, which ensnares the Transformer's head, causing the mighty robot to be seated firmly on the ground.


这里意思没理解正确,如果放开随机种子多试几次会发现前景的交互细节有很多错误,但这里的图中背景也依然很好。
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











