










感受野定义:
感受野被定义为卷积神经网络特征所能看到输入图像的区域,表示输出的特征图中一个像素对应的输入层的像素区域。一般来讲,对于只含有下采样的卷积网络,越靠后面的层,其输出的特征图上的每个元素的感受野越大。
公式一(自下到上计算)
计算公式为:
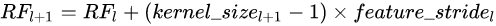 (1)
(1)
注:
(1)l表示层数,l+1表示l+1层;
(2)注意公式右边的feature_stride按下式计算:
(3)l=0时代表输入层,输入层的RF=1,feature_stride=1.
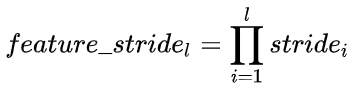
再引用一下那个例子:
原始图像为5x5,卷积核(Kernel Size)为3x3,padding 为1x1,stride为2x2,依照此卷积规则,连续做两次卷积。熟悉卷积过程的朋友都知道第一次卷积结果是3x3大小的feature map,第二次卷积结果是2x2大小的feature map。整个过程如图所示:

按照(1)式分别计算第一次和第二次卷积得到的特征图上每个元素的感受野为:
RF1 = 1+(3-1)*1 = 3
RF2 = 3+(3-1)21 = 7
公式二(自上到下计算)
(N-1)_RF =(N_RF - 1) * stride + kernel
注:
(N-1)_RF表示第N-1层的特征图中每个像素的感受野,N_RF示第N层的特征图中每个像素的感受野;
用这种方法计算上面的例子:
1_RF = (1-1)*1 + 3 = 3
0_RF = (3-1)*2 + 3 = 7
最上面一层的特征图对于本层来说RF=1,stride=1.
VGG网络用堆叠两次33卷积核代替55卷积核,用堆叠三次33卷积核代替77卷积核,这两种替代可以保证相应特征图上的每个像素具有相同的感受野,同时计算量大大降低了;此外,多层的小卷积核,可以引入更多次激活函数,提高了网络的非线性。

有效感受野
上面的计算公式得到的是理论感受野的大小,从卷积计算特点不难想到,越靠近输入中心位置的像素点对后面卷积层的输出特征图的影响权重越大。也就是说感受野内一些处于边缘位置的像素点并没有发挥很大作用,表观上表现为感受野实际减小了。下图为不同激活函数下的有效感受野对比:

设计神经网络结构时,要特别注意各层特征图的感受野变化情况。对于特征提取任务,最后一层卷积层的感受野不应超过输入图像大小;而对于anchor box的大小设置(或是特征金字塔层的选择),应使得anchor box大小与相应层的感受野大小相匹配。
附:
#!/usr/bin/env python
net_struct = {'alexnet': {'net':[[11,4,0],[3,2,0],[5,1,2],[3,2,0],[3,1,1],[3,1,1],[3,1,1],[3,2,0]],
'name':['conv1','pool1','conv2','pool2','conv3','conv4','conv5','pool5']},
'vgg16': {'net':[[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[3,1,1],
[2,2,0],[3,1,1],[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[3,1,1],[2,2,0]],
'name':['conv1_1','conv1_2','pool1','conv2_1','conv2_2','pool2','conv3_1','conv3_2',
'conv3_3', 'pool3','conv4_1','conv4_2','conv4_3','pool4','conv5_1','conv5_2','conv5_3','pool5']},
'zf-5':{'net': [[7,2,3],[3,2,1],[5,2,2],[3,2,1],[3,1,1],[3,1,1],[3,1,1]],
'name': ['conv1','pool1','conv2','pool2','conv3','conv4','conv5']}}
imsize = 224
def outFromIn(isz, net, layernum):
totstride = 1
insize = isz
for layer in range(layernum):
fsize, stride, pad = net[layer]
outsize = (insize - fsize + 2*pad) / stride + 1
insize = outsize
totstride = totstride * stride
return outsize, totstride
def inFromOut(net, layernum):
RF = 1
for layer in reversed(range(layernum)):
fsize, stride, pad = net[layer]
RF = ((RF -1)* stride) + fsize
return RF
if __name__ == '__main__':
print "layer output sizes given image = %dx%d" % (imsize, imsize)
for net in net_struct.keys():
print '************net structrue name is %s**************'% net
for i in range(len(net_struct[net]['net'])):
p = outFromIn(imsize,net_struct[net]['net'], i+1)
rf = inFromOut(net_struct[net]['net'], i+1)
print "Layer Name = %s, Output size = %3d, Stride = % 3d, RF size = %3d" % (net_struct[net]['name'][i], p[0], p[1], rf)
# [filter size, stride, padding]
#Assume the two dimensions are the same
#Each kernel requires the following parameters:
# - k_i: kernel size
# - s_i: stride
# - p_i: padding (if padding is uneven, right padding will higher than left padding; "SAME" option in tensorflow)
#
#Each layer i requires the following parameters to be fully represented:
# - n_i: number of feature (data layer has n_1 = imagesize )
# - j_i: distance (projected to image pixel distance) between center of two adjacent features
# - r_i: receptive field of a feature in layer i
# - start_i: position of the first feature's receptive field in layer i (idx start from 0, negative means the center fall into padding)
import math
convnet = [[11,4,0],[3,2,0],[5,1,2],[3,2,0],[3,1,1],[3,1,1],[3,1,1],[3,2,0],[6,1,0], [1, 1, 0]]
layer_names = ['conv1','pool1','conv2','pool2','conv3','conv4','conv5','pool5','fc6-conv', 'fc7-conv']
imsize = 227
def outFromIn(conv, layerIn):
n_in = layerIn[0]
j_in = layerIn[1]
r_in = layerIn[2]
start_in = layerIn[3]
k = conv[0]
s = conv[1]
p = conv[2]
n_out = math.floor((n_in - k + 2*p)/s) + 1
actualP = (n_out-1)*s - n_in + k
pR = math.ceil(actualP/2)
pL = math.floor(actualP/2)
j_out = j_in * s
r_out = r_in + (k - 1)*j_in
start_out = start_in + ((k-1)/2 - pL)*j_in
return n_out, j_out, r_out, start_out
def printLayer(layer, layer_name):
print(layer_name + ":")
print("\t n features: %s \n \t jump: %s \n \t receptive size: %s \t start: %s " % (layer[0], layer[1], layer[2], layer[3]))
layerInfos = []
if __name__ == '__main__':
#first layer is the data layer (image) with n_0 = image size; j_0 = 1; r_0 = 1; and start_0 = 0.5
print ("-------Net summary------")
currentLayer = [imsize, 1, 1, 0.5]
printLayer(currentLayer, "input image")
for i in range(len(convnet)):
currentLayer = outFromIn(convnet[i], currentLayer)
layerInfos.append(currentLayer)
printLayer(currentLayer, layer_names[i])
print ("------------------------")
layer_name = raw_input ("Layer name where the feature in: ")
layer_idx = layer_names.index(layer_name)
idx_x = int(raw_input ("index of the feature in x dimension (from 0)"))
idx_y = int(raw_input ("index of the feature in y dimension (from 0)"))
n = layerInfos[layer_idx][0]
j = layerInfos[layer_idx][1]
r = layerInfos[layer_idx][2]
start = layerInfos[layer_idx][3]
assert(idx_x < n)
assert(idx_y < n)
print ("receptive field: (%s, %s)" % (r, r))
print ("center: (%s, %s)" % (start+idx_x*j, start+idx_y*j))















 1103
1103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









