







 本文详细介绍了目标检测领域的经典模型,包括RCNN、SPP-net、Fast-RCNN和Faster-RCNN。RCNN采用Selective Search生成候选区域,SPP-net通过空间金字塔池化提高速度,Fast-RCNN引入RoI Pooling层,而Faster-RCNN通过区域生成网络(RPN)进一步加速,实现了与Fast-RCNN共享特征提取网络。
本文详细介绍了目标检测领域的经典模型,包括RCNN、SPP-net、Fast-RCNN和Faster-RCNN。RCNN采用Selective Search生成候选区域,SPP-net通过空间金字塔池化提高速度,Fast-RCNN引入RoI Pooling层,而Faster-RCNN通过区域生成网络(RPN)进一步加速,实现了与Fast-RCNN共享特征提取网络。
浅谈RCNN、SPP-net、Fast-Rcnn、Faster-Rcnn
一、简介
RCNN、SPP-net、Fast-Rcnn、Faster-Rcnn,一连串的经典模型,目标检测的开山之作,传奇模型。RCNN和Fast-RCNN简直是引领了最近两年目标检测的潮流!
欢迎各位评论讨论,博主才疏学浅,有疏忽和错误,如存在错误和纰漏,请各位及时指出,共同交流,共同进步。
二、RCNN
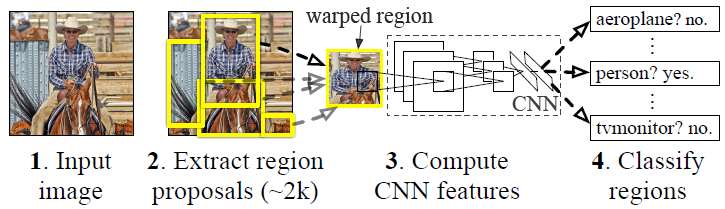
Region CNN(RCNN)可以说是利用深度学习进行目标检测的开山之作。R-CNN有两个关键点:一是使用建议窗口,并用CNN对其进行卷积特征提取;二是样本缺乏时,使用大量辅助样本进行预先训练,再用自己的样本进行微调。也就是fine-tuning,我觉得迁移学习和fine-tuning差不多…
经典的目标检测算法使用滑动窗口法来判断所有可能为目标的区域,取不同大小的滑动窗口,然后分别计算得分,还需要对框内的物体进行分类。显然运算量过于庞大。
那么RCNN的做法是先为图像生成region proposal(候选区域),然后用CNN进行特征提取。
RCNN的整体框架流程为:
- 采用Selective Search生成Region proposal(建议窗口),一张图片大约生成2000个建议窗口,由于建议窗口尺寸大小不一,warp(拉伸)到227*227.
- 运用CNN来提取特征,把每个候选区域送入CNN,提取特征。
- 将提取后的特征送入SVM分类器,用SVM对CNN输出的特征进行分类。
- Bounding Box回归,用Bounding Box回归校正原来的region proposal,生成预测窗口的坐标。
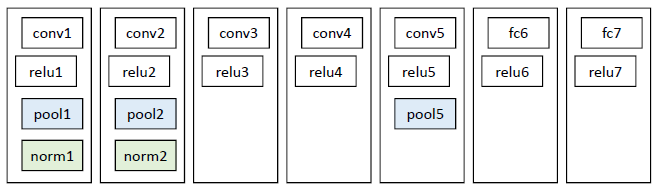
网络结构,借鉴Hinton 2012年在Image Net上的分类网络。

Selective Search
Selective Search方法从一种图片生成约2000个候选区域,采用一种过分割的手段,将图像分割成小区域,然后bottom-up,合并可能性最高的两个区域,重复合并,直到整张图像上合并成一个区域为止。
输出所有曾经存在过的区域,就是候选区域。
SVM
对每一类目标,使用一个线性SVM二类分类器进行判别。考察每一个候选框,如果和本类所有标定框的重叠面积都小于0.3,认定其为负样本。
Bounding Box回归
做位置精修,因为候选框不够准确,重叠面积很小。输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。
对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9634
9634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









