






系列文章目录
分词
自定义词典
关键词提取
提示:需要安装jieba
前言
jieba可对中文进行系列操作
一、分词
import jieba
sentence = '现在我在广州天河区'
# 精准输出切分结果,速度慢
list1 = jieba.cut(sentence, cut_all=False, HMM=True)
print('/'.join(list1))
# 全模式,速度快
list2 = jieba.cut(sentence, cut_all=True, HMM=True)
print('/'.join(list2))
# 搜索模式
list3 = jieba.cut(sentence, HMM=True)
print('/'.join(list3))
二、自定义字典
import jieba
sentence='广州3号线是世界上最拥挤的地铁线路'
# jieba.load_userdict('userdict.txt')
list1=jieba.cut(sentence)
print(list(list1))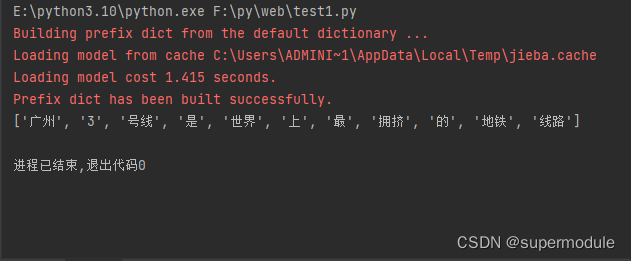
import jieba
sentence='广州3号线是世界上最拥挤的地铁线路'
jieba.load_userdict('userdict.txt')
list1=jieba.cut(sentence)
print(list(list1)) 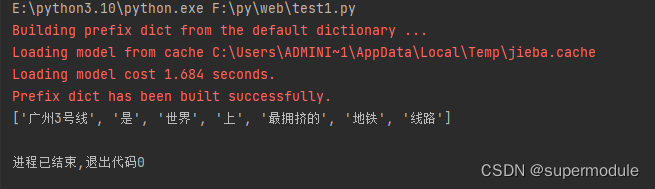
userdict.txt内的内容

三、关键词提取
import jieba.analyse
sentence = '我国继续保持世界第二大经济体的地位,经济稳健发展,全年国内生产总值预计超过120万亿元。面对全球粮食危机,我国粮食生产实现“十九连丰”,中国人的饭碗端得更牢了。我们巩固脱贫攻坚成果,全面推进乡村振兴,采取减税降费等系列措施为企业纾难解困,着力解决人民群众急难愁盼问题。疫情发生以来,我们始终坚持人民至上、生命至上,坚持科学精准防控,因时因势优化调整防控措施,最大限度保护了人民生命安全和身体健康。广大干部群众特别是医务人员、基层工作者不畏艰辛、勇毅坚守。经过艰苦卓绝的努力,我们战胜了前所未有的困难和挑战,每个人都不容易。目前,疫情防控进入新阶段,仍是吃劲的时候,大家都在坚忍不拔努力,曙光就在前头。大家再加把劲,坚持就是胜利,团结就是胜利。'
# 基于TF-IDF算法
list1 = jieba.analyse.extract_tags(sentence, topK=5, withWeight=False, allowPOS=(), withFlag=False)
# topK 返回最大权重关键词的个数,None表示全部,默认值20
# withWeight表示是否返回权重,返回(word,weight)的list,默认值为False
# allowPOS仅包括指定词性的词,默认为空
print(list1)
# 基于TextRank算法
list2 = jieba.analyse.textrank(sentence, topK=5, withWeight=False, allowPOS=('ns', 'n', 'v'), withFlag=False)
# 与TF-IDF方法相似,但是注意allowPOS有默认值,即会默认过滤某些词性
print(list2)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









