






一. Deep Marching Tetrahedra: a Hybrid Representation for High-Resolution 3D Shape Synthesis
1.背景
3D物体的隐式表达(sdf,OccNet)有两个缺点:
- 缺乏显示信息,这些信息对训练很有帮助 (ps:不太认可,只要能表达物体完整信息不就行了)
- 因为只能在物体表面采样作为监督,相当于是物体本身的一个近似,会有artifacts
- 需要用marching cube或者marching tetrahedra算法提取显式表达,计算开销大,为了减小开销,有的算法在降采样版本做MC和MT,会有量化误差。
显式表达的缺点:
- 分辨率有限
- 很多会预设一个形状,限制了最终形状多样性
本文提出了一种新的显式、隐式结合的表达方式DMTET
初步可以理解为,先得到隐式SDF表达,然后利用可微的Marching Tetrahedra过程将SDF转化为显式的Mesh表达。
MC/MT
通过输入粗略的点云/低分辨率体素,得到高分辨率Mesh表达。
2. 3D表示(先做些概念上的准备)
2.1 Deformable Tetrahedral Mesh(可变四面体网格)
用 ( V T , T ) (V_T,T) (VT,T)表示一个可变四边形网格,对某一个四面体 T k T_k Tk,四个顶点 { v a k , v b k , v c k , v d k } \{v_{ak},v_{bk},v_{ck},v_{dk}\} {vak,vbk,vck,vdk},顶点 v i v_i vi的SDF值为 s ( v i ) s(v_i) s(vi),四面体内部点的SDF值通过重心插值算法得到。
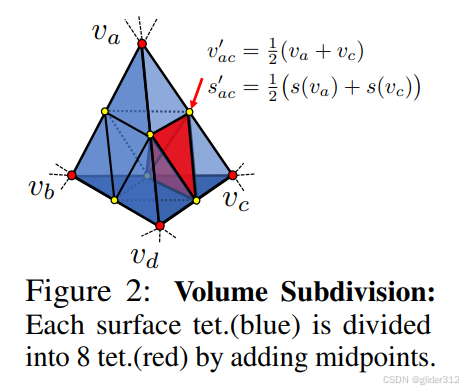
2.2 Volume Subdivision(体细分割,当确定某一个大的四面体包裹了物体表面后,分裂成8个小的四面体,使得更细致)
在DMTET方法中采用了从粗到细的策略。先分辨率低一点构建四面体,然后观察四面体顶点的SDF值,如果符号不同,说明四面体内部涵盖了表面,则一个四面体可以切分为8个小四面体。
2.3 Marching Tetrahedrea(sdf转mesh,先找到边缘顶点,然后根据sdf值插值找到预测顶点)
a. 四面体只有4个顶点,所以最终只有3种独特的形式:
即顶点negative和positive个数:
4:0/2:2/1:3(反过来是对称的)
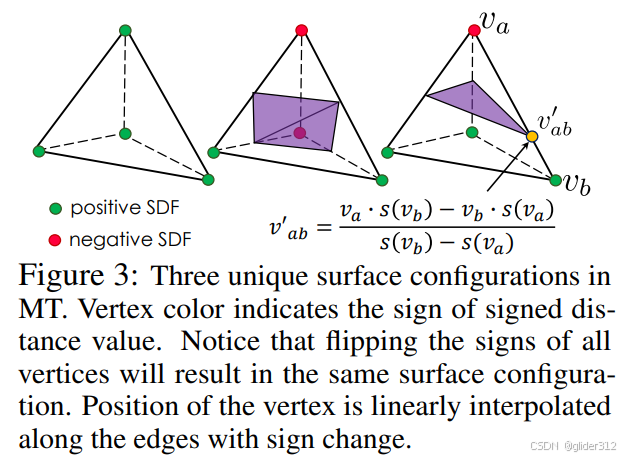
一旦确定好这三种,就可以通过图中公式插值出面片顶点位置。
因为分母是
s
(
v
b
)
−
s
(
v
a
)
s(v_b)-s(v_a)
s(vb)−s(va),此前工作会发现如果这俩相等,会有奇点。但如2.2,只会在四面体顶点符号不同时做这个计算,所以可以避免这个问题,且这个公式是可求导的,从而反向传播成为了可能。
2.4 表面细分(用于得到mesh后,通过算法增加顶点数量,进一步优化mesh)
旨在在不改变原始几何形状的前提下,增加网格的密度,使曲面看起来更加平滑。
传统方法采用Loop Subdivision method,对现有顶点通过某种方式得到权重,进行加权平均,得到新的顶点。
DMTET采用了固定的可学习的参数,包括顶点
v
i
′
v_i^{\prime}
vi′和控制邻近顶点平滑度的参数
α
i
\alpha_i
αi,只在开始时预测每个顶点参数,后续就使用这个参数,可以减少计算量。
3.DMTET
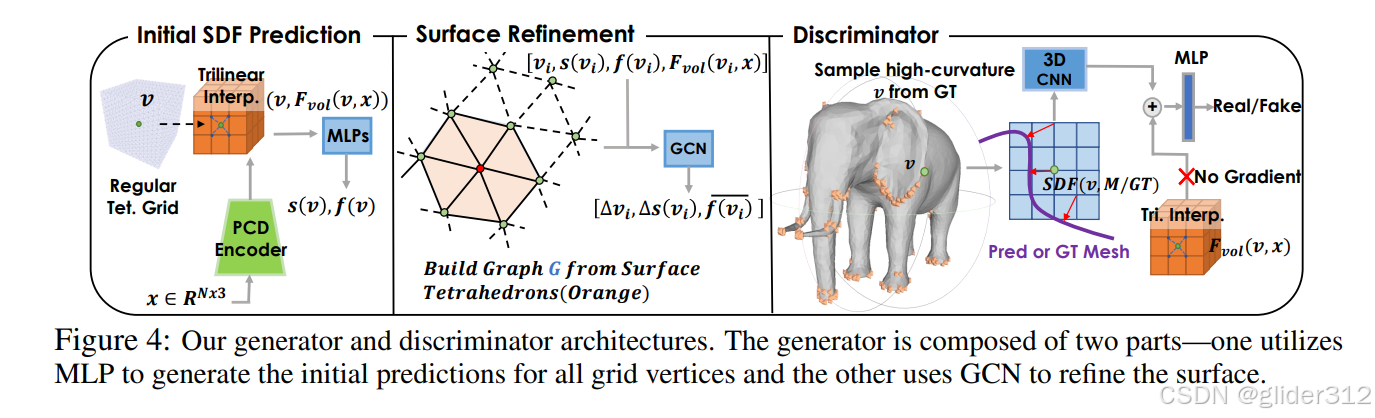
如图所示,DMTET主要用于将粗模型refine为细模型。
思路大概为:
a. 先预先构建一个均匀的,由四面体构建的立方体,这些立方体中每个四面体顶点,在粗模型点云的条件下,对应的sdf值
s
(
v
)
s(v)
s(v),和一个特征值
f
(
v
)
f(v)
f(v),有了顶点的sdf,每个四面体就可以通过顶点的sdf值,判断出是否包裹了物体表面,并将没有包裹的四面体筛除。
b.然后,将每个筛除后的四面体顶点和边构建为一个图神经网络,并将该顶点
v
i
v_i
vi、对应的sdf值
s
(
v
i
)
s(v_i)
s(vi),一个特征值
f
(
v
i
)
f(v_i)
f(vi),以及前一个步骤的中间特征
F
v
o
l
(
v
,
x
)
F_{vol}(v,x)
Fvol(v,x)输入网络,得到预测的顶点
Δ
v
i
\Delta v_{i}
Δvi、sdf偏移量
Δ
s
v
i
\Delta s_{v_i}
Δsvi和新的特征值
f
(
v
i
)
‾
\overline{{{{f(v_{i} )}}}}
f(vi)。
c. 根据
Δ
v
i
\Delta v_{i}
Δvi和
Δ
s
v
i
\Delta s_{v_i}
Δsvi更新
s
(
v
)
s(v)
s(v)和
f
(
v
)
f(v)
f(v)。并将包裹表面的四面体裂变,再重复b操作,构建图神经网络–预测偏移量。
d. 进行可微表面细分,增加顶点数,使得预测表面更光滑。
e. 最后得到预测mesh,与ground-truth求损失函数。
3.1 3D Generator
- 生成SDF表示
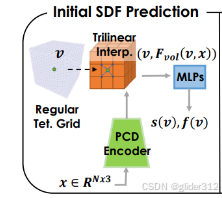
利用PVCNN&Trillinear Interpolation&MLP构建SDF,其中
x
x
x为point cloud(DMTET是从一个粗模型refine为精细模型),所以有个初始的point_cloud
PCD encoder会得到三个特征
R
1
3
×
C
1
,
R
2
3
×
C
2
,
R
3
3
×
C
3
R_1^3 \times C_1,R_2^3 \times C_2,R_3^3 \times C_3
R13×C1,R23×C2,R33×C3,其中
R
1
=
32
R_1=32
R1=32,
R
2
=
16
R_2=16
R2=16,
R
3
=
8
R_3=8
R3=8,
C
1
=
64
C_1=64
C1=64,
C
2
=
256
C_2=256
C2=256,
C
3
=
512
C_3=512
C3=512。
左侧Regular Tet Grid为预先做好的由四面体构成的立方体,将每个四面体顶点
v
v
v定位到PCD encoder得到的三个立方体特征,用最近的特征grid顶点插值。 三个立方体插值可以分别得到一个64/256/512长度的向量,拼接后作为特征
F
v
o
l
(
v
,
x
)
F_{vol}(v,x)
Fvol(v,x),与顶点
v
v
v一起输入MLP网络,得到对应的sdf值
s
(
v
)
s(v)
s(v),和一个特征值
f
(
v
)
f(v)
f(v)。
-
surface refinement with volume subdivision
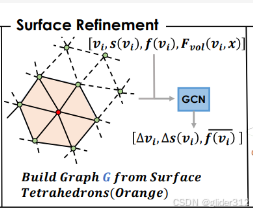
根据初始得到的SDF,先定位到包含物体表面的四面体 T s u r f T_{surf} Tsurf,构建一个图 G = ( V s u r f , E s u r f ) G=(V_{surf},E_{surf}) G=(Vsurf,Esurf)其中二者对应了 T s u r f T_{surf} Tsurf的顶点和边。
现在一阶段提供了一些东西,根据SDF新构建了一些G和初始面片顶点 v i v_i vi和对应 s ( v i ) s(v_i) s(vi),可以通过一个图神经网络,通过以下公式
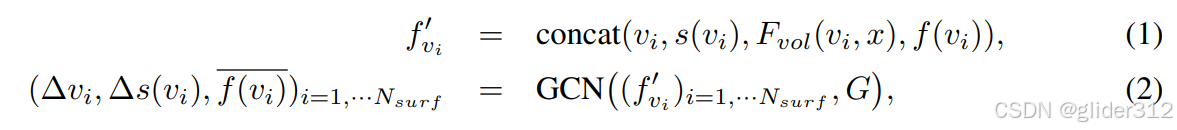
Δ v i \Delta v_{i} Δvi和 Δ s v i \Delta s_{v_i} Δsvi为位置偏移和SDF残差指,用于更新 v i v_i vi和 s ( v i ) s(v_i) s(vi)
v i ′ = = v i + Δ v i v_{i}^{\prime}==v_{i}+\Delta v_{i} vi′==vi+Δvi
s v i ′ = = s v i + Δ s v i s_{v_i}^{\prime}==s_{v_i}+\Delta s_{v_i} svi′==svi+Δsvi
f ( v i ) ‾ \overline{{{{f(v_{i} )}}}} f(vi)为更新后的顶点特征
随后将包含顶点的四面体和紧邻的四面体保留并切分为8块,其他的丢弃,再重新优化一次。
二阶段的各数值都是一阶段网络得到的,所以两个阶段可以一起反向传播。 -
提取表面后,利用一个图神经网络,参数化Loop Subvidision算法的顶点 v i ′ v_i^{\prime} vi′和控制邻近顶点平滑度的参数 α i \alpha_i αi进一步优化。
3.2 3D判别器
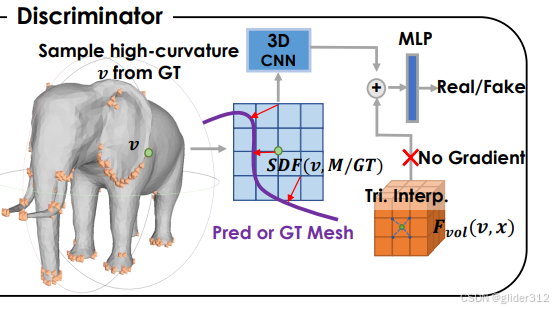
对SDF有一个判别器
GT:从目标Mesh中高曲率地方点
v
v
v以及附近一些点得到SDF
pred:预测Mesh中同样位置得到SDF
4.损失函数
最后gt为mesh
损失函数三部分:重建mesh+判别器loss+正则loss
-
重建mesh:预测的mesh中采样一些点云,gt mesh采样一些点云,求chamfer distance(点集相似度),法向一致性
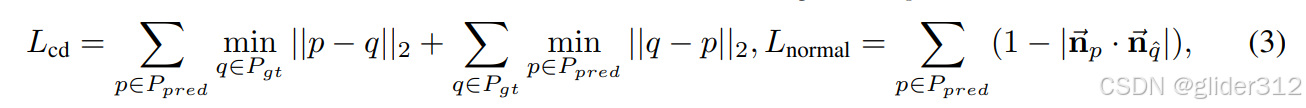
-
判别器loss
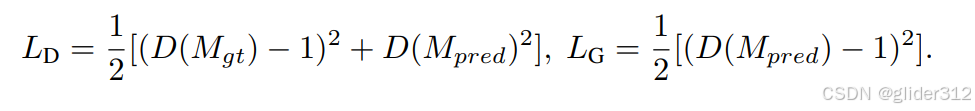
-
正则loss
要约束一下SDF,因为SDF符号如果全翻转,后面的四面体会认为不变。
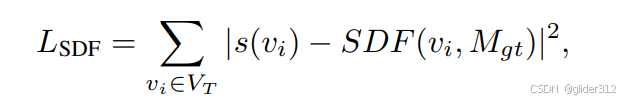
约束顶点偏移不要太大
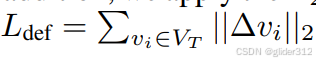
总loss:
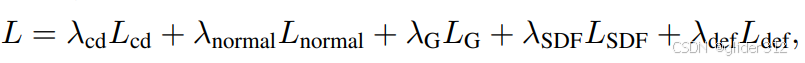
5.评价
其实就是生成SDF后通过MT算法得到Mesh。。。只不过将MT过程参数化,且跟SDF生成过程串联训练。虽然是串联训练,但又不得不在损失函数中增加SDF的约束。。。直接生成Mesh,还是不太利于深度学习表达,所以选用了图神经网络。
但是,个人看来,DMTET的深远意义在于,它是第一个开源的、稳定的、好用的,在训练过程汇中直接从隐式场中获得显式3D表达的工作。由于Nerf表面重建不好用,它在Neus等显式3D重建外重新提供了一种3D重建的思路;另一方面,它真正实现了3D shape重建端到端,避免了marching cube等后处理算法过程中带来的低质量干扰

















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









