







随着大语言模型(LLM)技术的不断发展,行业内的竞争日趋白热化。近日,谷歌推出的实验性大模型 Gemini-Exp-1114 凭借卓越性能,成功登顶 lmarena.ai 榜单,超越了 OpenAI 的 ChatGPT O1。这一成果标志着谷歌在 AI 领域取得了新的突破,也为全球 LLM 的发展树立了新的标杆。本文将深入探讨这一成就背后的数据和原因。
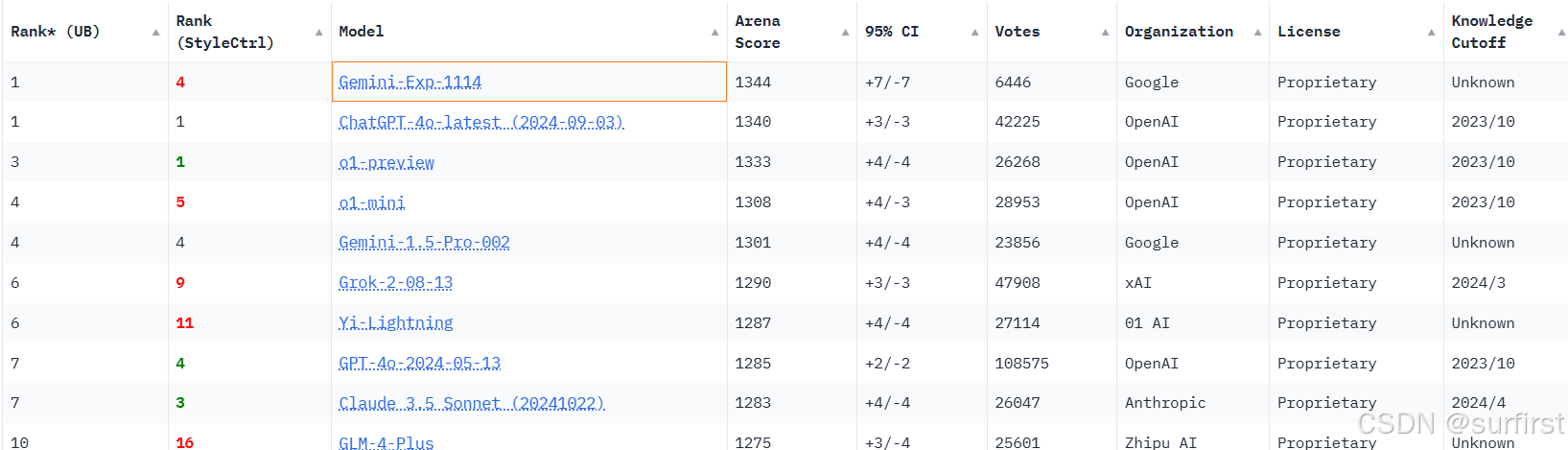
Gemini-Exp-1114 在 lmarena.ai 榜单上的卓越表现
谷歌于近期发布了实验性语言模型 Gemini-Exp-1114,并通过 Google AI Studio 向公众开放测试。该模型以全面的任务能力和跨领域表现脱颖而出:
- 多任务表现优异:在数学、创意写作、指令执行、多轮对话等多个类别中取得顶级成绩。
- 视觉 AI 实力突出:能够从图片中精准生成对应的 HTML 和 CSS 代码,展现了在视觉任务中的强大能力。
- 综合能力领先:即便在复杂的代码生成和硬提示风格控制任务中表现略逊,仅排名第三,但其整体表现依然强劲,足以确保榜单第一的位置。
这也是谷歌大模型首次在综合性排行榜中超越 OpenAI 的旗舰产品,成为行业的全新标杆。
lmarena.ai 榜单的排名方法与权威性
lmarena.ai 是由 UC Berkeley SkyLab 和 LMSYS 团队开发的开放式社区平台,用于通过人类偏好评估 LLM 的性能。其特点如下:
- 排名方法
- 平台采用 Bradley-Terry 模型,通过对模型的两两比较,计算得出相对评分。
- 数据来源广泛,既有专家评审,也有普通用户投票,确保多样性和公平性。
- 平台权威性
- 平台已经积累了超过 100 万次投票,数据覆盖了多种任务类型。
- 研究显示,投票结果与专家评分高度一致,验证了其评价机制的可信性。
- 行业认可度
- lmarena.ai 被广泛引用,成为行业内对比模型性能的主要参考之一。
这使得 Gemini-Exp-1114 在该平台上的胜出更具说服力。
中国大模型在 lmarena.ai 榜单中的表现
1. 榜单前28名模型
LM Arena 是当前最权威的跨语言模型性能评估平台之一。其基于用户反馈和多维度评估指标,为各大语言模型进行排序。以下是截至当前榜单中的前28名:
| 排名 | 模型名称 | 分数 | 组织 | 知识截止 |
|---|---|---|---|---|
| 1 | Gemini-Exp-1114 | 1344 | Unknown | |
| 1 | ChatGPT-4o-latest (2024-02-03) | 1340 | OpenAI | 2023/10 |
| 3 | o1-preview | 1333 | OpenAI | 2023/10 |
| 4 | o1-mini | 1308 | OpenAI | 2023/10 |
| 4 | Gemini-1.5-Pro-002 | 1301 | Unknown | |
| 6 | Grok-2-08-13 | 1290 | xAI | 2024/3 |
| 6 | Yi-Lightning | 1287 | 01 万物 | Unknown |
| 7 | GPT-4o-2024-05-13 | 1285 | OpenAI | 2023/10 |
| 7 | Claude-3.5-Sonnet (20241022) | 1283 | Anthropic | 2024/4 |
| 10 | GLM-4-Plus | 1275 | 智谱 AI | Unknown |
| 10 | GPT-4o-mini-2024-07-18 | 1272 | OpenAI | 2023/10 |
| 10 | Gemini-1.5-Flash-002 | 1272 | Unknown | |
| 10 | llama-3.1-Nemotron-70B-Instruct | 1269 | Nvidia | 2023/12 |
| 10 | Meta-llama-3.1-405B-Instruct-fp8 | 1267 | Meta | 2023/12 |
| 10 | Meta-llama-3.1-405B-Instruct-bf16 | 1266 | Meta | 2023/12 |
| 11 | Claude-3.5-Sonnet (20240620) | 1268 | Anthropic | 2024/4 |
| 11 | Grok-2-Mini-08-13 | 1267 | xAI | 2024/3 |
| 12 | Gemini-Advanced-App (2024-05-14) | 1267 | Online | |
| 12 | GPT-4o-2024-08-06 | 1265 | OpenAI | 2023/10 |
| 12 | Yi-Lightning-lite | 1264 | 01 万物 | Unknown |
| 12 | Qwen-Max-0919 | 1263 | 阿里巴巴 | Unknown |
| 17 | Qwen2.5-72B-Instruct | 1259 | 阿里巴巴 | 2024/9 |
| 18 | Gemini-1.5-Pro-001 | 1260 | 2023/11 | |
| 18 | Deepseek-v2.5 | 1258 | DeepSeek | Unknown |
| 22 | GPT-4-Turbo-2024-04-09 | 1256 | OpenAI | 2023/12 |
| 25 | Mistral-Large-2407 | 1251 | Mistral | 2024/7 |
| 25 | Athene-70B | 1250 | NexusFlow | 2024/7 |
| 26 | GPT-4-1106-preview | 1250 | OpenAI | 2023/4 |
Google 的 Gemini-Exp-1114 凭借 1344 的高分,与 OpenAI 的 ChatGPT-4o-latest 并列第一。从性能得分来看,Google 和 OpenAI 在顶级榜单中占据了主导地位。
2. 中国公司大模型的亮点与排名
在榜单中,中国的人工智能公司也有亮眼表现:
- 01 AI 的 Yi-Lightning:以 1287 的分数排名第 6;
- 智谱 AI (Zhipu AI) 的 GLM-4-Plus:以 1275 的分数排名第 10;
- 阿里巴巴的 Qwen 系列:分别排名第 12(Qwen-Max-0919,分数 1263)和第 17(Qwen2.5-72B-Instruct,分数 1259)。
尽管中国模型的总分稍低,但在特定任务上表现出色,展示了其在中文及多语言领域的优势。这些模型的崛起,表明中国公司在全球 LLM 竞争中展现出日益增长的影响力。
Gemini-Exp-1114 胜出的原因及优缺点
1. 胜出的原因
- 全面的任务覆盖:数学、指令理解、多轮对话、创意写作等多个领域排名第一。
- 视觉 AI 的突破:通过分析图片生成高质量代码,这一能力在当前行业中独树一帜。
- 用户体验的改进:通过 Google AI Studio 提供开放式测试,增强了用户对模型能力的直观感受。
2. 优缺点分析
- 优势
- 技术多样性:语言与视觉任务兼备,充分展示跨模态能力。
- 创新性任务能力:如生成仓储优化算法、解复杂逻辑问题等。
- 情感与创意表达:能够完成高质量创意写作和情感交流。
- 局限性
- 响应速度偏慢:与同类模型相比,优先考虑精准性导致速度稍有滞后。
- 上下文限制:32k token 的上下文长度在大模型中不算突出。
- 特定任务表现稍弱:在代码生成和硬提示风格控制任务中略逊于竞争对手。
总结与展望
Gemini-Exp-1114 的问世不仅刷新了行业基准,更展示了谷歌在跨模态任务中的领先地位。然而,这一成就也伴随着新挑战——如何进一步优化性能和扩展模型能力,将决定其能否长期占据行业领先位置。
对于用户来说,Gemini-Exp-1114 的公开测试为探索下一代 AI 提供了绝佳机会。而对于行业而言,竞争的持续加剧无疑将推动 LLM 技术进入新的发展阶段。
相关链接
- https://lmarena.ai/?leaderboard
- https://aistudio.google.com/app/prompts/new_chat?instructions=lmsys-1114&model=gemini-exp-1114


















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











