







论文标题: Data Driven Decision Making with Time Series and Spatio-temporal Data
作者:Bin Yang(杨彬), Yuxuan Liang(梁宇轩), Chenjuan Guo(郭晨娟), Christian S. Jensen
机构:华东师范大学,香港科技大学(广州),奥尔堡大学
论文链接:https://arxiv.org/abs/2503.08473
Cool Paper:https://papers.cool/arxiv/2503.08473
TL, DR:本文提出“数据治理-分析-决策”范式,利用时间序列和时空数据进行数据驱动决策,涵盖数据基础、治理方法、分析特性及决策策略,展望预训练、生成模型与LLMs结合等研究方向。
关键词:数据驱动决策、时间序列、时空数据、数据治理、数据分析、决策制定、预训练、生成模型、大型语言模型

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅
摘要
时间序列数据捕获随时间变化的属性。此类数据广泛存在,从科学和医学领域到工业和环境领域。当时间序列中的属性表现出空间变化时,通常将数据称为时空数据。作为整个社会流程持续数字化的一部分,可用的时间序列和时空数据量越来越大。在本教程中,重点介绍使用此类数据进行数据驱动的决策,例如,基于交通时间序列预测实现更环保、更高效的交通。本教程采用“数据-治理-分析-决策”的整体范式。我们首先介绍时间序列和时空数据的数据基础,这些数据通常是异构的。接下来,讨论旨在提高数据质量的数据治理方法。然后介绍数据分析,重点关注五个期望特征:自动化、稳健性、通用性、可解释性和资源效率。最后,介绍数据驱动的决策策略,并简要讨论有希望的研究方向。希望本教程能够成为对时间序列和时空数据的价值创造感兴趣的研究人员和从业人员的主要资源。
Q: 这篇论文试图解决什么问题?
A: 论文中提到了多个与时间序列和时空数据相关的研究工作,这些研究涵盖了数据治理、数据分析、决策制定等多个方面。以下是一些关键的相关研究:
数据治理
- 缺失值插补:
- 图神经网络自编码器:用于空间缺失值的插补,通过图结构建模传感器之间的关系,将缺失值插补问题转化为图边权重完成任务 [12]。
- 循环神经网络:用于时间缺失值的插补,通过时间序列的上下文信息预测缺失值 [13]。
- 时空图神经网络:结合图神经网络和循环神经网络,用于时空数据的缺失值插补,例如在交通流量预测中 [14]。
- 不确定性量化:
- 动态不确定性图模型:用于智能交通中的交通流不确定性建模,通过概率分布表示交通速度的不确定性 [15]。
- 边缘中心范式和路径中心范式:分别用于处理图中的边和路径的不确定性,平衡效率和精度 [4]。
- 多模态数据融合:
- 特征基方法:通过特征提取和融合,整合多模态数据,例如将历史交通数据、天气数据和兴趣点数据融合用于交通预测 [18]。
- 对齐基方法:通过数据对齐,例如将车辆轨迹数据与地图数据对齐,以消除轨迹噪声和插补轨迹空白 [17]。
数据分析
- 自动化:
- 自动化时间序列预测:通过自动化网络架构设计和超参数选择,提高预测模型的性能 [24]。
- 自动化时空图预测:通过神经架构搜索,优化时空图预测模型 [26]。
- 泛化性:
- 无监督对比学习:通过无监督学习,提高模型在不同任务中的泛化能力 [30]。
- 弱监督对比学习:通过少量标注数据,提高模型的泛化能力 [31]。
- 掩码自编码器:通过掩码自编码器和关系推理,提高模型的泛化能力 [32]。
- 稳健性:
- 稳健异常检测:在噪声数据上进行异常检测,提高模型的稳健性 [34]。
- 对抗域适应:通过对抗学习,处理数据不平衡问题 [36]。
- 连续学习:通过连续学习,处理时空数据的分布偏移问题 [37]。
- 可解释性:
- 后验可解释性度量:通过后验方法评估模型的可解释性 [35]。
- 特征提取与可解释模型结合:通过神经网络提取特征,并与可解释模型结合,提高预测的可解释性 [43]。
- 因果模型:通过因果模型预测未来的相关性,提高决策的可解释性 [46]。
- 资源效率:
- 知识蒸馏框架:通过知识蒸馏,提高时空数据表示的效率 [32]。
- 轻量级时间序列分析框架:通过自适应量化,提高模型在资源受限设备上的效率 [47]。
数据驱动的决策制定
- 不确定性下的决策:
- 随机占优:通过随机占优方法快速识别最优选择,考虑不同风险偏好 [51]。
- 多目标决策:
- 帕累托最优:通过帕累托最优方法识别非支配选项,平衡多个目标 [15]。
- 偏好函数:通过偏好函数将多个目标整合为单一目标,选择最优选项 [54]。
- 个性化决策:
- 上下文感知路径排名:通过上下文感知方法,为不同用户定制个性化路径 [29]。
- 基于学习的决策:
- 专家决策模拟:通过分析专家的决策模式,使非专家能够复制专家级别的决策 [56]。
研究方向
- 预训练和少样本学习:通过预训练模型,提高模型在新任务和新环境中的适应能力 [20]。
- 生成模型:通过生成模型的强泛化能力和数据生成能力,提高时空数据的迁移能力。
- 与大型语言模型(LLMs)的结合:通过与LLMs的结合,提高时空数据挖掘的可解释性和交互性 [21]。
Q: 有哪些相关研究?
A: 论文中提到了多个与时间序列和时空数据相关的研究工作,这些研究涵盖了数据治理、数据分析、决策制定等多个方面。以下是一些关键的相关研究:
数据治理
- 缺失值插补:
- 图神经网络自编码器:用于空间缺失值的插补,通过图结构建模传感器之间的关系,将缺失值插补问题转化为图边权重完成任务 [12]。
- 循环神经网络:用于时间缺失值的插补,通过时间序列的上下文信息预测缺失值 [13]。
- 时空图神经网络:结合图神经网络和循环神经网络,用于时空数据的缺失值插补,例如在交通流量预测中 [14]。
- 不确定性量化:
- 动态不确定性图模型:用于智能交通中的交通流不确定性建模,通过概率分布表示交通速度的不确定性 [15]。
- 边缘中心范式和路径中心范式:分别用于处理图中的边和路径的不确定性,平衡效率和精度 [4]。
- 多模态数据融合:
- 特征基方法:通过特征提取和融合,整合多模态数据,例如将历史交通数据、天气数据和兴趣点数据融合用于交通预测 [18]。
- 对齐基方法:通过数据对齐,例如将车辆轨迹数据与地图数据对齐,以消除轨迹噪声和插补轨迹空白 [17]。
数据分析
- 自动化:
- 自动化时间序列预测:通过自动化网络架构设计和超参数选择,提高预测模型的性能 [24]。
- 自动化时空图预测:通过神经架构搜索,优化时空图预测模型 [26]。
- 泛化性:
- 无监督对比学习:通过无监督学习,提高模型在不同任务中的泛化能力 [30]。
- 弱监督对比学习:通过少量标注数据,提高模型的泛化能力 [31]。
- 掩码自编码器:通过掩码自编码器和关系推理,提高模型的泛化能力 [32]。
- 稳健性:
- 稳健异常检测:在噪声数据上进行异常检测,提高模型的稳健性 [34]。
- 对抗域适应:通过对抗学习,处理数据不平衡问题 [36]。
- 连续学习:通过连续学习,处理时空数据的分布偏移问题 [37]。
- 可解释性:
- 后验可解释性度量:通过后验方法评估模型的可解释性 [35]。
- 特征提取与可解释模型结合:通过神经网络提取特征,并与可解释模型结合,提高预测的可解释性 [43]。
- 因果模型:通过因果模型预测未来的相关性,提高决策的可解释性 [46]。
- 资源效率:
- 知识蒸馏框架:通过知识蒸馏,提高时空数据表示的效率 [32]。
- 轻量级时间序列分析框架:通过自适应量化,提高模型在资源受限设备上的效率 [47]。
数据驱动的决策制定
- 不确定性下的决策:
- 随机占优:通过随机占优方法快速识别最优选择,考虑不同风险偏好 [51]。
- 多目标决策:
- 帕累托最优:通过帕累托最优方法识别非支配选项,平衡多个目标 [15]。
- 偏好函数:通过偏好函数将多个目标整合为单一目标,选择最优选项 [54]。
- 个性化决策:
- 上下文感知路径排名:通过上下文感知方法,为不同用户定制个性化路径 [29]。
- 基于学习的决策:
- 专家决策模拟:通过分析专家的决策模式,使非专家能够复制专家级别的决策 [56]。
研究方向
- 预训练和少样本学习:通过预训练模型,提高模型在新任务和新环境中的适应能力 [20]。
- 生成模型:通过生成模型的强泛化能力和数据生成能力,提高时空数据的迁移能力。
- 与大型语言模型(LLMs)的结合:通过与LLMs的结合,提高时空数据挖掘的可解释性和交互性 [21]。
这些研究工作为时间序列和时空数据的管理和分析提供了坚实的基础,并为未来的研究方向提供了指导。
Q: 论文如何解决这个问题?
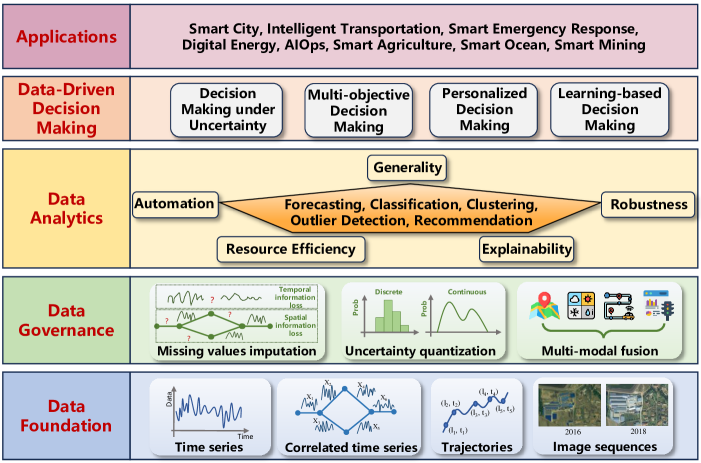
A: 论文通过提出一个全面的“数据治理-分析-决策”范式来解决时间序列和时空数据驱动决策的问题。以下是论文解决该问题的具体方法和步骤:
1. 数据基础
论文首先介绍了时间序列和时空数据的基本概念和定义,包括时间序列、相关时间序列、轨迹和图像序列等。这些定义为后续的数据治理和分析提供了基础。
- 时间序列: X = < s 1 , s 2 , . . . , s m > \mathbf{X}=< s_1,s_2,...,s_m > X=<s1,s2,...,sm>,其中 s i ∈ R c , 1 ≤ i ≤ M s_i\in\mathbb{R}^c,1\le i\le M si∈Rc,1≤i≤M,时序数据为一个 C C C维的向量, C C C是第 i i i个时间步观察到的属性。
- 相关时间序列(Correlated Time Series): T = { X 1 , X 2 , . . . , X N } \mathbf{T}=\{\mathbf{X}_1,\mathbf{X}_2,...,\mathbf{X}_N\} T={X1,X2,...,XN}。这些时间序列通常会由于相应传感器的空间排列而表现出相关性,并且相关性通常使用图来建模。
- 轨迹:(位置、时间)对的序列,用于捕捉移动物体(例如,人类、动物和车辆)随时间的位置。
- 图像序列: V = < I 1 , I 2 , . . . , I T > \mathbf{V}=<\mathbf{I}_1,\mathbf{I}_2,...,\mathbf{I}_T> V=<I1,I2,...,IT>, I i ∈ R N × M × C , 1 ≤ i ≤ T \mathbf{I}_i\in \mathbb{R}^{N\times M \times C},1\le i \le T Ii∈RN×M×C,1≤i≤T,是捕捉第 i i i个时间戳的状态的图像。每幅图像包含 N × M N×M N×M 个像素,代表空间区域。每个像素包含 C C C个观察到的属性。
2. 数据治理
数据治理部分旨在解决原始数据中存在的质量问题,如缺失值、不确定性和多模态数据的融合。具体方法包括:
- 缺失值插补:
- 空间插补:使用图神经网络自编码器,通过图结构建模传感器之间的关系,将缺失值插补问题转化为图边权重完成任务 。
- 时间插补:使用循环神经网络,通过时间序列的上下文信息预测缺失值 。
- 时空插补:结合图神经网络和循环神经网络,用于时空数据的缺失值插补,例如在交通流量预测中 。
- 不确定性量化:
- 动态不确定性图模型:用于智能交通中的交通流不确定性建模,通过概率分布表示交通速度的不确定性 。
- 边缘中心范式和路径中心范式:分别用于处理图中的边和路径的不确定性,平衡效率和精度 。
- 多模态数据融合:
- 特征基方法:通过特征提取和融合,整合多模态数据,例如将历史交通数据、天气数据和兴趣点数据融合用于交通预测 。
- 对齐基方法:通过数据对齐,例如将车辆轨迹数据与地图数据对齐,以消除轨迹噪声和插补轨迹空白 。
3. 数据分析
数据分析部分强调了自动化、稳健性、泛化性、可解释性和资源效率等五个关键特性。具体方法包括:
- 自动化:
- 自动化时间序列预测:通过自动化网络架构设计和超参数选择,提高预测模型的性能 [24]。
- 自动化时空图预测:通过神经架构搜索,优化时空图预测模型 [26]。
- 泛化性:
- 无监督对比学习:通过无监督学习,提高模型在不同任务中的泛化能力 [30]。
- 弱监督对比学习:通过少量标注数据,提高模型的泛化能力 [31]。
- 掩码自编码器:通过掩码自编码器和关系推理,提高模型的泛化能力 [32]。
- 稳健性:
- 稳健异常检测:在噪声数据上进行异常检测,提高模型的稳健性 [34]。
- 对抗域适应:通过对抗学习,处理数据不平衡问题 [36]。
- 连续学习:通过连续学习,处理时空数据的分布偏移问题 [37]。
- 可解释性:
- 后验可解释性度量:通过后验方法评估模型的可解释性 [35]。
- 特征提取与可解释模型结合:通过神经网络提取特征,并与可解释模型结合,提高预测的可解释性 [43]。
- 因果模型:通过因果模型预测未来的相关性,提高决策的可解释性 [46]。
- 资源效率:
- 知识蒸馏框架:通过知识蒸馏,提高时空数据表示的效率 [32]。
- 轻量级时间序列分析框架:通过自适应量化,提高模型在资源受限设备上的效率 [47]。
4. 数据驱动的决策制定
决策制定部分讨论了在不确定性下、多目标、个性化以及基于学习的决策制定策略。具体方法包括:
- 不确定性下的决策:
- 随机占优:通过随机占优方法快速识别最优选择,考虑不同风险偏好 [51]。
- 多目标决策:
- 帕累托最优:通过帕累托最优方法识别非支配选项,平衡多个目标 [15]。
- 偏好函数:通过偏好函数将多个目标整合为单一目标,选择最优选项 [54]。
- 个性化决策:
- 上下文感知路径排名:通过上下文感知方法,为不同用户定制个性化路径 [29]。
- 基于学习的决策:
- 专家决策模拟:通过分析专家的决策模式,使非专家能够复制专家级别的决策 [56]。
5. 研究方向
论文最后讨论了未来可能的研究方向,包括预训练和少样本学习、生成模型的应用以及与大型语言模型(LLMs)的结合等。这些方向旨在进一步提高模型的泛化能力、适应能力和交互性。
通过上述方法,论文提供了一个全面的框架,从数据治理到数据分析再到决策制定,系统地解决了时间序列和时空数据驱动决策的问题。

















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









