







参考:医学图像分割综述:U-Net系列_医学图像 实例分割-CSDN博客
2D Unet
- 收缩路径:每个块包含两个连续的3 × 3卷积,后面是一个ReLU激活函数和最大池化层(下采样)
- 扩展路径:该路径包括一个2 × 2转置卷积层(上采样),然后是两个连续的3 × 3卷积和一个ReLU激活。
由两个连续卷积层(可选批量归一化)和ReLU激活函数组成的模块 DoubleConv
- nn.BatchNorm2d(out_channels):批量归一化层对小批量(mini-batch)数据进行归一化处理,有效减少梯度消失和梯度爆炸问题,加速网络训练并提高模型的泛化能力。
class DoubleConv(nn.Module): def __init__(self, in_channels, out_channels, with_bn=False): super().__init__() if with_bn: self.step = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.BatchNorm2d(out_channels), nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1), nn.BatchNorm2d(out_channels), nn.ReLU(), ) else: self.step = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1), nn.ReLU(), ) def forward(self, x): return self.step(x)定义了整个UNet网络结构,包括编码(下采样)和解码(上采样)部分。
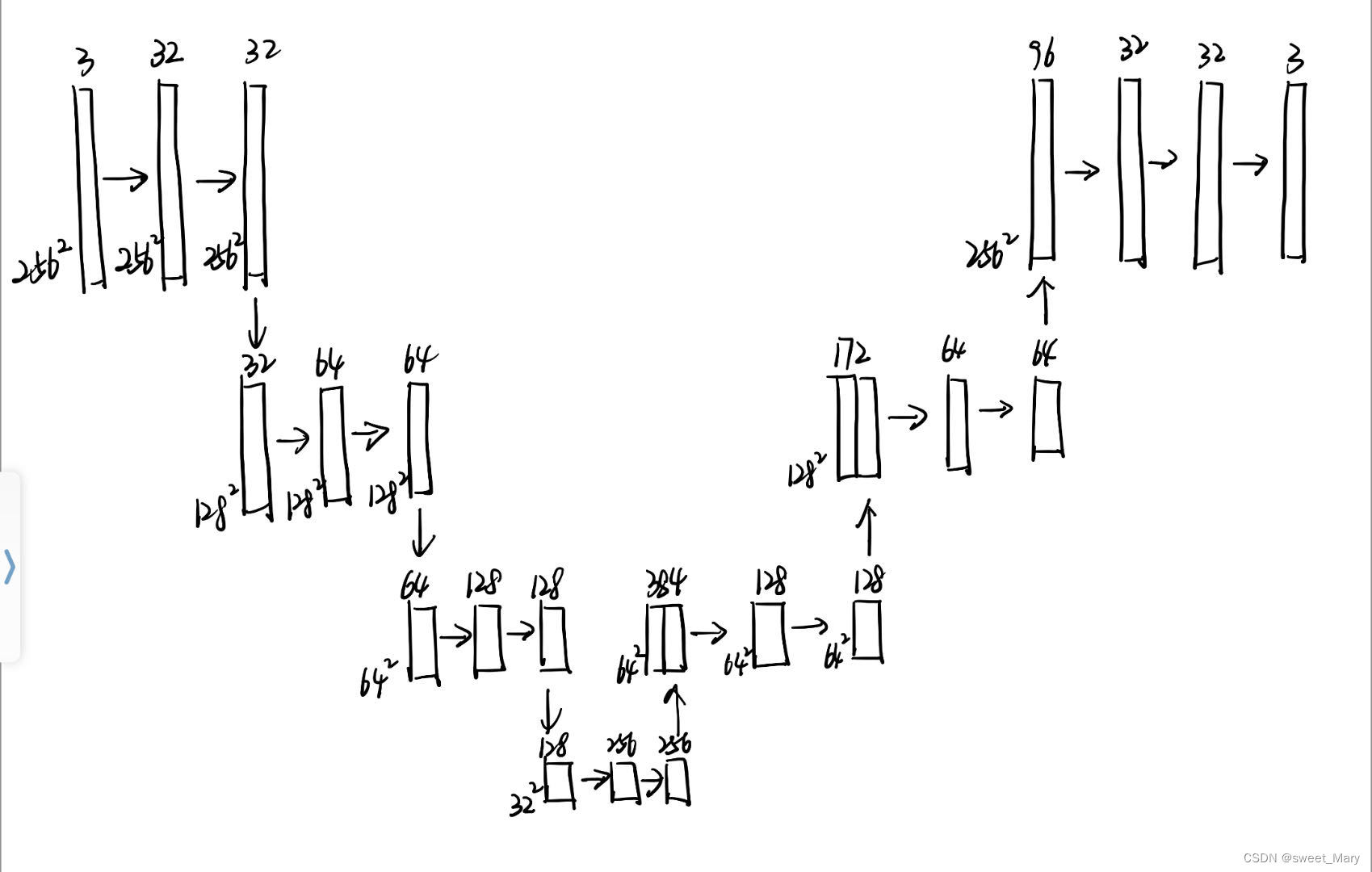
class UNet(nn.Module): def __init__(self, in_channels, out_channels, with_bn=False): super().__init__() init_channels = 32 self.out_channels = out_channels self.en_1 = DoubleConv(in_channels , init_channels , with_bn) self.en_2 = DoubleConv(1*init_channels, 2*init_channels, with_bn) self.en_3 = DoubleConv(2*init_channels, 4*init_channels, with_bn) self.en_4 = DoubleConv(4*init_channels, 8*init_channels, with_bn) self.de_1 = DoubleConv((4 + 8)*init_channels, 4*init_channels, with_bn) self.de_2 = DoubleConv((2 + 4)*init_channels, 2*init_channels, with_bn) self.de_3 = DoubleConv((1 + 2)*init_channels, 1*init_channels, with_bn) self.de_4 = nn.Conv2d(init_channels, out_channels, 1) self.maxpool = nn.MaxPool2d(kernel_size=2) self.upsample = nn.Upsample(scale_factor=2, mode='bilinear') def forward(self, x): e1 = self.en_1(x) e2 = self.en_2(self.maxpool(e1)) e3 = self.en_3(self.maxpool(e2)) e4 = self.en_4(self.maxpool(e3)) d1 = self.de_1(torch.cat([self.upsample(e4), e3], dim=1)) d2 = self.de_2(torch.cat([self.upsample(d1), e2], dim=1)) d3 = self.de_3(torch.cat([self.upsample(d2), e1], dim=1)) d4 = self.de_4(d3) return d4这里以3*256*256的图片为例,手动推算了一遍,有问题的小伙伴可以对照着代码自己手推一遍。
跳过连接增强
- 将深层、低分辨率层的语义信息与浅层、高分辨率层的本地信息结合在一起
- 由于本地高分辨率信息在网络的收缩部分丢失,因此在对这些卷积进行上采样时无法完全恢复。(针对U-net的什么问题)
增加跳过连接的数量
- 改进一
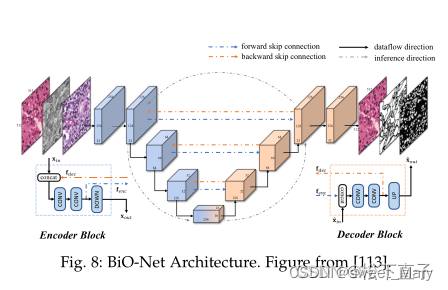
- 具有双向跳过连接的U-Net架构
- 有两种类型的跳过连接:前向和反向
- 前向:在同一级别上组合编码器和解码器层。这些跳过连接保留编码器的低级视觉特征,并将它们与语义解码器信息结合起来。
- 反向:向后跳过连接将解码后的高级特性从解码器传递回相同级别的编码器。编码器可以将语义解码器特征与其原始输入结合起来,灵活地聚合两种特征。
- 递归架构
- 框架图
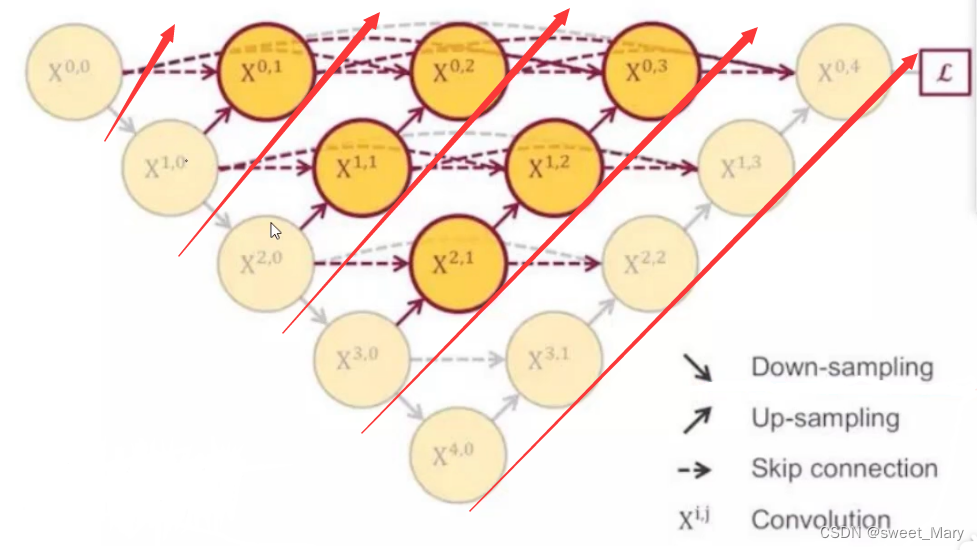
- 改进二(U-net++)
- 参考:网络模型(U-net,U-net++, U-net+++)_u-net+++官网-CSDN博客
- 流程图:
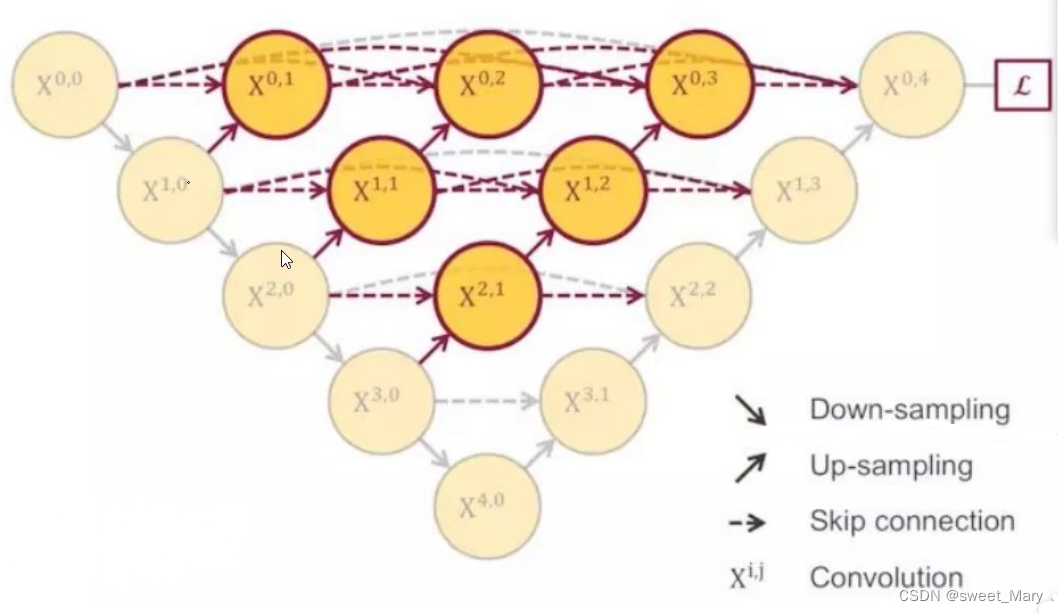
- 整体运行过程为:
普通的卷积模块(两个卷积层和批归一化层)VGGBlock,与上述的DoubleConv类似
class VGGBlock(nn.Module): def __init__(self, in_channels, middle_channels, out_channels): super().__init__() self.relu = nn.ReLU(inplace=True) self.conv1 = nn.Conv2d(in_channels, middle_channels, 3, padding=1) self.bn1 = nn.BatchNorm2d(middle_channels) self.conv2 = nn.Conv2d(middle_channels, out_channels, 3, padding=1) self.bn2 = nn.BatchNorm2d(out_channels) def forward(self, x): out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) return outU-net也是类似的,朋友们一定要自己推导一遍U-net,这个后面的内容看起来就会很轻松
class UNet(nn.Module): def __init__(self, num_classes, input_channels=3, **kwargs): super().__init__() nb_filter = [32, 64, 128, 256, 512] self.pool = nn.MaxPool2d(2, 2) self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0]) self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1]) self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2]) self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3]) self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4]) self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3]) self.conv2_2 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2]) self.conv1_3 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1]) self.conv0_4 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0]) self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1) def forward(self, input): x0_0 = self.conv0_0(input) x1_0 = self.conv1_0(self.pool(x0_0)) x2_0 = self.conv2_0(self.pool(x1_0)) x3_0 = self.conv3_0(self.pool(x2_0)) x4_0 = self.conv4_0(self.pool(x3_0)) x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1)) x2_2 = self.conv2_2(torch.cat([x2_0, self.up(x3_1)], 1)) x1_3 = self.conv1_3(torch.cat([x1_0, self.up(x2_2)], 1)) x0_4 = self.conv0_4(torch.cat([x0_0, self.up(x1_3)], 1)) output = self.final(x0_4) return output核心部分即为NestedUNet,用来替代Unet,整体流程如上述两张图片所示
class NestedUNet(nn.Module): def __init__(self, num_classes, input_channels=3, deep_supervision=False, **kwargs): super().__init__() nb_filter = [32, 64, 128, 256, 512] self.deep_supervision = deep_supervision self.pool = nn.MaxPool2d(2, 2) self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) #编码器 self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0]) self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1]) self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2]) self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3]) self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4]) #解码器 self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0]) self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1]) self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2]) self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3]) self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0]) self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1]) self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2]) #拿conv0_3举例,*3是因为(0,0),(0,1),(0,2)跳跃连接,+nb_filter[1]是因为(1,2)传递过来 self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0]) self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1]) self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0]) if self.deep_supervision: self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1) self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1) self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1) self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1) else: self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1) def forward(self, input): x0_0 = self.conv0_0(input) x1_0 = self.conv1_0(self.pool(x0_0)) x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1)) x2_0 = self.conv2_0(self.pool(x1_0)) x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1)) x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1)) x3_0 = self.conv3_0(self.pool(x2_0)) x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], 1)) x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], 1)) x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1)) x4_0 = self.conv4_0(self.pool(x3_0)) x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1)) x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], 1)) x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], 1)) x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1)) if self.deep_supervision: output1 = self.final1(x0_1) output2 = self.final2(x0_2) output3 = self.final3(x0_3) output4 = self.final4(x0_4) return [output1, output2, output3, output4] else: output = self.final(x0_4) return output
在跳过连接中处理特征映射
- 改进一
- 提高从超声图像中分割卵巢和卵泡的困难任务的性能
- 相邻的滤泡很可能在空间上是相关的--------空间循环神经网络(RNNs)
- 原有U-Net的最大池化操作会导致空间相对信息的丢失
- 改进二(Attunet)
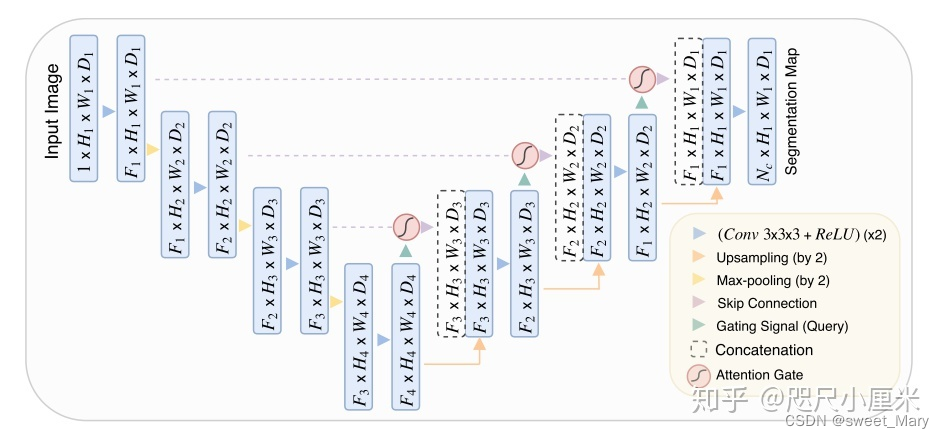
初始化层init_weights
def init_weights(net, init_type='normal', gain=0.02): def init_func(m): classname = m.__class__.__name__ if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1): if init_type == 'normal': init.normal_(m.weight.data, 0.0, gain) elif init_type == 'xavier': init.xavier_normal_(m.weight.data, gain=gain) elif init_type == 'kaiming': init.kaiming_normal_(m.weight.data, a=0, mode='fan_in') elif init_type == 'orthogonal': init.orthogonal_(m.weight.data, gain=gain) else: raise NotImplementedError('initialization method [%s] is not implemented' % init_type) if hasattr(m, 'bias') and m.bias is not None: init.constant_(m.bias.data, 0.0) elif classname.find('BatchNorm2d') != -1: init.normal_(m.weight.data, 1.0, gain) init.constant_(m.bias.data, 0.0) print('initialize network with %s' % init_type) net.apply(init_func)基本卷积块
conv_block类(水个字哈哈哈)---两个卷积层、批量归一化和ReLU激活函数class conv_block(nn.Module): def __init__(self,ch_in,ch_out): super(conv_block,self).__init__() self.conv = nn.Sequential( nn.Conv2d(ch_in, ch_out, kernel_size=3,stride=1,padding=1,bias=True), nn.BatchNorm2d(ch_out), nn.ReLU(inplace=True), nn.Conv2d(ch_out, ch_out, kernel_size=3,stride=1,padding=1,bias=True), nn.BatchNorm2d(ch_out), nn.ReLU(inplace=True) ) def forward(self,x): x = self.conv(x) return x
up_conv类---上采样卷积块class up_conv(nn.Module): def __init__(self,ch_in,ch_out): super(up_conv,self).__init__() self.up = nn.Sequential( nn.Upsample(scale_factor=2), nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=1,padding=1,bias=True), nn.BatchNorm2d(ch_out), nn.ReLU(inplace=True) ) def forward(self,x): x = self.up(x) return x递归卷积块
多次进行卷积操作,丰富提取特征
class Recurrent_block(nn.Module): def __init__(self,ch_out,t=2): super(Recurrent_block,self).__init__() self.t = t self.ch_out = ch_out self.conv = nn.Sequential( nn.Conv2d(ch_out,ch_out,kernel_size=3,stride=1,padding=1,bias=True), nn.BatchNorm2d(ch_out), nn.ReLU(inplace=True) ) def forward(self,x): for i in range(self.t): if i==0: x1 = self.conv(x) x1 = self.conv(x+x1) return x1RRCNN_block:继续增强特征提取
实现方式:把U-net中的卷积块编程RRCNN_blockclass RRCNN_block(nn.Module): def __init__(self,ch_in,ch_out,t=2): super(RRCNN_block,self).__init__() self.RCNN = nn.Sequential( Recurrent_block(ch_out,t=t), Recurrent_block(ch_out,t=t) ) self.Conv_1x1 = nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=1,padding=0) def forward(self,x): x = self.Conv_1x1(x) x1 = self.RCNN(x) return x+x1class R2U_Net(nn.Module): def __init__(self,img_ch=3,output_ch=1,t=2): super(R2U_Net,self).__init__() self.Maxpool = nn.MaxPool2d(kernel_size=2,stride=2) self.Upsample = nn.Upsample(scale_factor=2) self.RRCNN1 = RRCNN_block(ch_in=img_ch,ch_out=64,t=t) self.RRCNN2 = RRCNN_block(ch_in=64,ch_out=128,t=t) self.RRCNN3 = RRCNN_block(ch_in=128,ch_out=256,t=t) self.RRCNN4 = RRCNN_block(ch_in=256,ch_out=512,t=t) self.RRCNN5 = RRCNN_block(ch_in=512,ch_out=1024,t=t) self.Up5 = up_conv(ch_in=1024,ch_out=512) self.Up_RRCNN5 = RRCNN_block(ch_in=1024, ch_out=512,t=t) self.Up4 = up_conv(ch_in=512,ch_out=256) self.Up_RRCNN4 = RRCNN_block(ch_in=512, ch_out=256,t=t) self.Up3 = up_conv(ch_in=256,ch_out=128) self.Up_RRCNN3 = RRCNN_block(ch_in=256, ch_out=128,t=t) self.Up2 = up_conv(ch_in=128,ch_out=64) self.Up_RRCNN2 = RRCNN_block(ch_in=128, ch_out=64,t=t) self.Conv_1x1 = nn.Conv2d(64,output_ch,kernel_size=1,stride=1,padding=0) def forward(self,x): # encoding path x1 = self.RRCNN1(x) x2 = self.Maxpool(x1) x2 = self.RRCNN2(x2) x3 = self.Maxpool(x2) x3 = self.RRCNN3(x3) x4 = self.Maxpool(x3) x4 = self.RRCNN4(x4) x5 = self.Maxpool(x4) x5 = self.RRCNN5(x5) # decoding + concat path d5 = self.Up5(x5) d5 = torch.cat((x4,d5),dim=1) d5 = self.Up_RRCNN5(d5) d4 = self.Up4(d5) d4 = torch.cat((x3,d4),dim=1) d4 = self.Up_RRCNN4(d4) d3 = self.Up3(d4) d3 = torch.cat((x2,d3),dim=1) d3 = self.Up_RRCNN3(d3) d2 = self.Up2(d3) d2 = torch.cat((x1,d2),dim=1) d2 = self.Up_RRCNN2(d2) d1 = self.Conv_1x1(d2) return d1
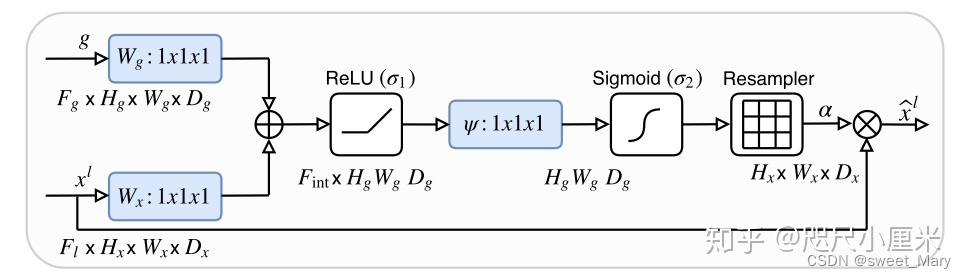
Attention_block(这里应该是重头戏吧)
class Attention_block(nn.Module): #F_g:来自解码器的特征图通道数 #F_l:来自编码器的特征图通道数 #F_int:中间特征图的通道数 def __init__(self,F_g,F_l,F_int): super(Attention_block,self).__init__() #对解码器特征图进行 1x1 卷积和批量归一化,用于调整通道数到 F_int self.W_g = nn.Sequential( nn.Conv2d(F_g, F_int, kernel_size=1,stride=1,padding=0,bias=True), nn.BatchNorm2d(F_int) ) #对编码器特征图进行 1x1 卷积和批量归一化,用于调整通道数到 F_int self.W_x = nn.Sequential( nn.Conv2d(F_l, F_int, kernel_size=1,stride=1,padding=0,bias=True), nn.BatchNorm2d(F_int) ) #将 F_int 通道数的特征图压缩为单通道特征图,通过 1x1 卷积、批量归一化和 Sigmoid 激活函数,输出注意力权重 self.psi = nn.Sequential( nn.Conv2d(F_int, 1, kernel_size=1,stride=1,padding=0,bias=True), nn.BatchNorm2d(1), nn.Sigmoid() ) self.relu = nn.ReLU(inplace=True) def forward(self,g,x): g1 = self.W_g(g) x1 = self.W_x(x) psi = self.relu(g1+x1) psi = self.psi(psi) return x*psi实现方式:
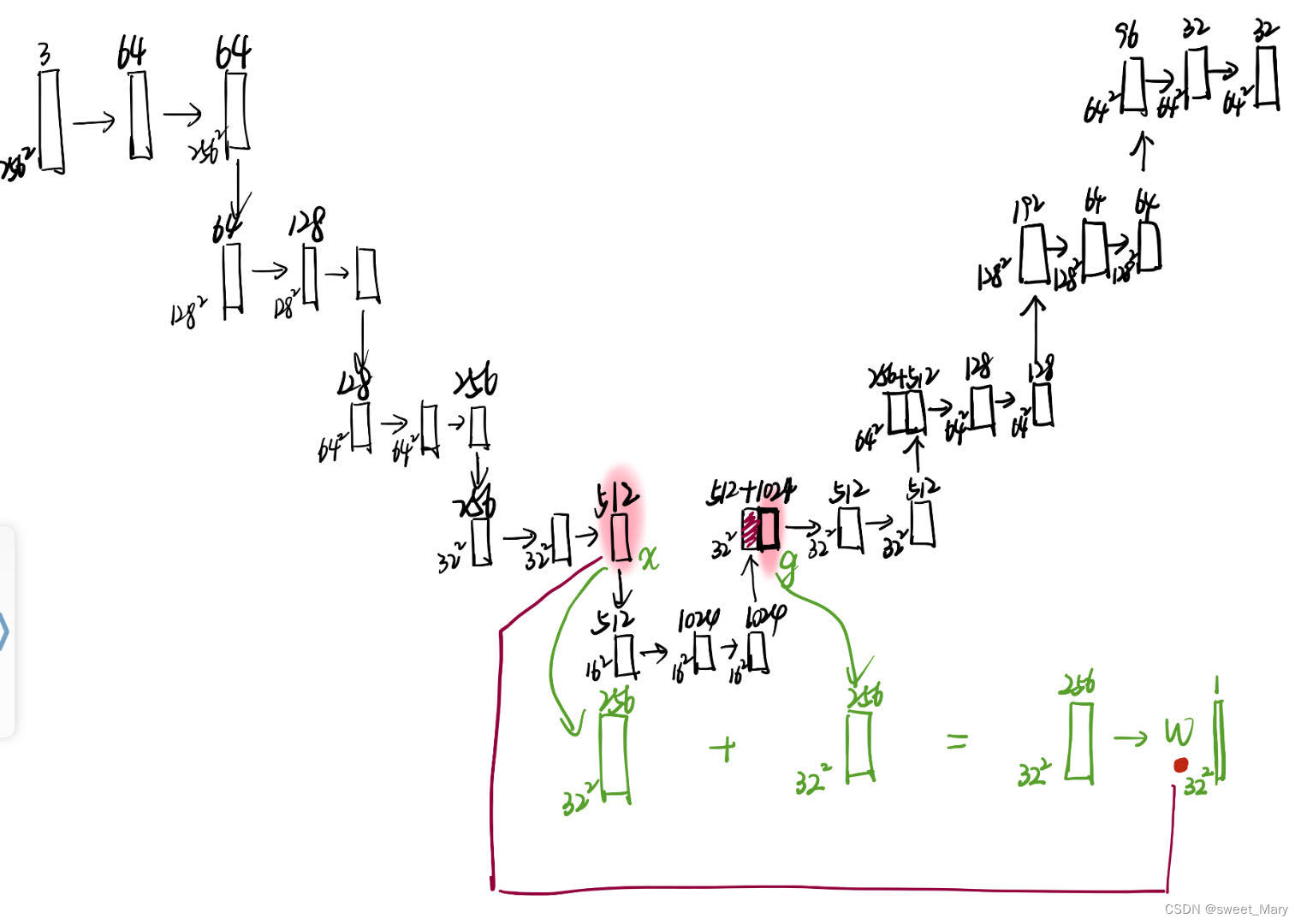
class AttU_Net(nn.Module): def __init__(self,img_ch=3,output_ch=1): super(AttU_Net,self).__init__() self.Maxpool = nn.MaxPool2d(kernel_size=2,stride=2) self.Conv1 = conv_block(ch_in=img_ch,ch_out=64) self.Conv2 = conv_block(ch_in=64,ch_out=128) self.Conv3 = conv_block(ch_in=128,ch_out=256) self.Conv4 = conv_block(ch_in=256,ch_out=512) self.Conv5 = conv_block(ch_in=512,ch_out=1024) self.Up5 = up_conv(ch_in=1024,ch_out=512) self.Att5 = Attention_block(F_g=512,F_l=512,F_int=256) self.Up_conv5 = conv_block(ch_in=1024, ch_out=512) self.Up4 = up_conv(ch_in=512,ch_out=256) self.Att4 = Attention_block(F_g=256,F_l=256,F_int=128) self.Up_conv4 = conv_block(ch_in=512, ch_out=256) self.Up3 = up_conv(ch_in=256,ch_out=128) self.Att3 = Attention_block(F_g=128,F_l=128,F_int=64) self.Up_conv3 = conv_block(ch_in=256, ch_out=128) self.Up2 = up_conv(ch_in=128,ch_out=64) self.Att2 = Attention_block(F_g=64,F_l=64,F_int=32) self.Up_conv2 = conv_block(ch_in=128, ch_out=64) self.Conv_1x1 = nn.Conv2d(64,output_ch,kernel_size=1,stride=1,padding=0) def forward(self,x): # encoding path x1 = self.Conv1(x) x2 = self.Maxpool(x1) x2 = self.Conv2(x2) x3 = self.Maxpool(x2) x3 = self.Conv3(x3) x4 = self.Maxpool(x3) x4 = self.Conv4(x4) x5 = self.Maxpool(x4) x5 = self.Conv5(x5) # decoding + concat path d5 = self.Up5(x5) x4 = self.Att5(g=d5,x=x4) d5 = torch.cat((x4,d5),dim=1) d5 = self.Up_conv5(d5) d4 = self.Up4(d5) x3 = self.Att4(g=d4,x=x3) d4 = torch.cat((x3,d4),dim=1) d4 = self.Up_conv4(d4) d3 = self.Up3(d4) x2 = self.Att3(g=d3,x=x2) d3 = torch.cat((x2,d3),dim=1) d3 = self.Up_conv3(d3) d2 = self.Up2(d3) x1 = self.Att2(g=d2,x=x1) d2 = torch.cat((x1,d2),dim=1) d2 = self.Up_conv2(d2) d1 = self.Conv_1x1(d2) return d1这是我自己手推的示意图,没明白的朋友建议先补一下注意力机制的Q、K、V,然后来看看图鸭~
最后,将RRCNN_block和Attention_block结合,为R2AttU_Net模块:
class R2AttU_Net(nn.Module): def __init__(self,img_ch=3,output_ch=1,t=2): super(R2AttU_Net,self).__init__() self.Maxpool = nn.MaxPool2d(kernel_size=2,stride=2) self.Upsample = nn.Upsample(scale_factor=2) self.RRCNN1 = RRCNN_block(ch_in=img_ch,ch_out=64,t=t) self.RRCNN2 = RRCNN_block(ch_in=64,ch_out=128,t=t) self.RRCNN3 = RRCNN_block(ch_in=128,ch_out=256,t=t) self.RRCNN4 = RRCNN_block(ch_in=256,ch_out=512,t=t) self.RRCNN5 = RRCNN_block(ch_in=512,ch_out=1024,t=t) self.Up5 = up_conv(ch_in=1024,ch_out=512) self.Att5 = Attention_block(F_g=512,F_l=512,F_int=256) self.Up_RRCNN5 = RRCNN_block(ch_in=1024, ch_out=512,t=t) self.Up4 = up_conv(ch_in=512,ch_out=256) self.Att4 = Attention_block(F_g=256,F_l=256,F_int=128) self.Up_RRCNN4 = RRCNN_block(ch_in=512, ch_out=256,t=t) self.Up3 = up_conv(ch_in=256,ch_out=128) self.Att3 = Attention_block(F_g=128,F_l=128,F_int=64) self.Up_RRCNN3 = RRCNN_block(ch_in=256, ch_out=128,t=t) self.Up2 = up_conv(ch_in=128,ch_out=64) self.Att2 = Attention_block(F_g=64,F_l=64,F_int=32) self.Up_RRCNN2 = RRCNN_block(ch_in=128, ch_out=64,t=t) self.Conv_1x1 = nn.Conv2d(64,output_ch,kernel_size=1,stride=1,padding=0) def forward(self,x): # encoding path x1 = self.RRCNN1(x) x2 = self.Maxpool(x1) x2 = self.RRCNN2(x2) x3 = self.Maxpool(x2) x3 = self.RRCNN3(x3) x4 = self.Maxpool(x3) x4 = self.RRCNN4(x4) x5 = self.Maxpool(x4) x5 = self.RRCNN5(x5) # decoding + concat path d5 = self.Up5(x5) x4 = self.Att5(g=d5,x=x4) d5 = torch.cat((x4,d5),dim=1) d5 = self.Up_RRCNN5(d5) d4 = self.Up4(d5) x3 = self.Att4(g=d4,x=x3) d4 = torch.cat((x3,d4),dim=1) d4 = self.Up_RRCNN4(d4) d3 = self.Up3(d4) x2 = self.Att3(g=d3,x=x2) d3 = torch.cat((x2,d3),dim=1) d3 = self.Up_RRCNN3(d3) d2 = self.Up2(d3) x1 = self.Att2(g=d2,x=x1) d2 = torch.cat((x1,d2),dim=1) d2 = self.Up_RRCNN2(d2) d1 = self.Conv_1x1(d2) return d1
ResUNet
- 与普通网络的串行结构相比,残差单元增加了跳跃映射,将输入与输出直接进行相加,补充卷积过程中损失的特征信息,这点与U-net的跳跃连接结构有点类似,不过Res中的跳跃连接做的是Add操作,而U-net的跳跃连接做的是Concatenate操作,还是有本质的不同
- 参考:结合残差结构的Res-Unet及其代码实现-CSDN博客















 9881
9881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









