







本文首发于微信公众号:人工智能与图像处理
关键点检测算法-OpenPose
一,论文解析:
人体姿态简介
人体姿态估计是计算机视觉中一个很基础的问题。从名字的角度来看,可以理解为对“人体”的姿态(关键点,比如头,左手,右脚等)的位置估计。
人体姿态估计可以分为两种思路:
-
“top-down”,它指先检测人体区域,再检测区域内的人体关键点。
-
“bottom-up”,它指先检测图片中所有的人体关键点,然后将这些关键点对应到不同的人物个体。
这里需要提及一下,第一种方案因为需要对检测出的每个人体区域,分别做前向关键点检测,所以速度较慢,而OpenPose采用的则为第二种方案。

图1:顶部:多人姿态估计。属于同一人的身体部位相连,包括脚部关键点(大脚趾、小脚趾和脚跟)。左下:对应连接右肘和手腕的部位亲和场(PAFs)。颜色编码了方向。右下:每个PAF的每个像素中都编码了肢体的位置和方向的2D向量。
Fig1下左中一个个带颜色的小区域就是PAF(其实就是limb区域,比如右手肘到右手腕这一段肢体区域),不同颜色代表不同的方向。在PAF中的每个像素都对应一个向量,来表示limb的位置和方向,如Fig1下右所示。
已有"bottom-up"方法缺点:
-
未利用全局上下文先验信息,也即图片中其他人的身体关键点信息;
-
将关键点对应到不同的人物个体,算法复杂度太高。
OpenPose改进点:提出“Part Affinity Fields (PAFs)”,每个像素是2D的向量,用于表征位置和方向信息。基于检测出的关节点和关节联通区域,使用greedy inference算法,可以将这些关节点快速对应到不同人物个体。
OpenPose论文翻译
摘要
我们提出了一个方法,能够在一张图中高效的识别出多人的2D姿态。该方法运用了非参数表示(non-parametric representation),我们称之为部分亲和域(PAFs:Part Affinitu Fields),用它来学习怎样将身体部分和个体联系起来。这个结构编码了全局信息,并允许一个贪婪的从底向上的解析步骤,这在实现实时性能时,有着高度的精准且无须考虑图像中人的数量。这个结构被设计成相同顺序预测过程的两个分支,来联合学习部分位置(关节点)以及它们之间的关联(相邻的关节点的连接关系)。我们的方法在the inaugural COCO 2016 keypoints challenge中首次提出,并且在性能和有效性上,都超过了之前在MPII Multi-Person基准上的最佳方法。
1. Introduction
人体的2D姿态估计,在定位人体的关键点或者部分关键点,主要集中在寻找个体的身体部位。在图中预测多人的姿态,尤其是社会性的个体(各种状况的姿势)面临着独特的挑战。
-
首先,每张图片中的人体数量是未知的,并且这些人存在不同位置和不同大小。
-
第二,人与人之间的交互产生复杂的空间推理,比如,接触、遮挡、肢体关节等因素是各部分之间的联系变得困难。
-
第三,运行时间复杂度会随着图片中的人的数量而增大,从而实时性能是一个挑战。
常见的方式是利用人体检测器检测出所有人体,然后进行单人的姿态估计。这种自上而下的方法直接利用已有的技术来做单人姿态估计,但是容易出现的问题:如果人体检测器失败了(当人体靠近时容易发生),那么检测结果是无法恢复正确的。进一步说,自上而下方法的运行时间与人体数量成正比:每一个人体,都要运行一次单人姿态估计,如果图片中存在很多人,那么就需要花费大量时间。与之相反,自下而上是吸引人的,因为它们提供了早期结果的鲁棒性,并且具有潜在的能力来解耦图片中人体的数量和运行时间复杂性的关系。并且,自下而上的方法不直接使用来自另外身体部分和另外的人体的全局信息。实际上,自下而上的方法不能保证效率的提高,因为最后的解析需要花费高昂的全局推理。例如,Pishchulin等人提出开创性的研究,提出了一个自下而上的方法,可以标记出候选检测内容(关键点)以及它们与个体的联系。但是,在一个全连接图上解决整数线性规划问题是一个NP-hard问题,而且处理这类问题需要几个小时。Insafutdinov等人建立了基于ResNet的部分检测器和图像的从属成对分数(image-dependent pairwise scores)的模型。很大的提高了运行时间,但这个方法处理每张图片然然需要几分钟,因为受限于部分提议的数量(指的是图中人体的个数)。在论文[11]中使用成对表现(pairwise representations),很难做精确的回归,因此需要独立的逻辑回归。non-deterministic polynomial:非确定性多项式,NP-hard问题通俗的来说是其解的正确性能够被很容易检测的问题,“很容易检测”值的是存在一个多项式检测算法
在这篇论文,我们提出了一个多人姿态评估有效的方法,其准确性在多个公共数据集中达到了领先水平。我们第一个提出利用部分亲和域(PAFs:Part Affinitu Fields)来表示自上而下的联系分数,PAFs,是图片中2D向量集,编码了肢体的定位和方向。我们证明了同时推断自下而上的对全局上下进行了足够好的编码,来允许贪婪的解析获得高质量的结果,而花费的计算成本只是一小部分。我们已经开源了代码,能够完整的复现,并正式发布了这史上第一个实时多人姿态检测系统。
2.相关工作
OpenPose是第一个用于身体、脚、手和面部关节点实时检测的开源库。
3. 方法
图2展示了我们方法的整体流程。将一张大小为w∗h彩色图作为输入(图2a),然后将输入图像喂给一个前馈网络得到两个结果,一个是Fig2(b),另一个是Fig2(c)。
先说Fig2(b),其得到的是一组heatmap(即文中所说的confidence map),用符号S表示,每张heatmap对应一种关节点,比如Fig2(b)左所示的heatmap预测的是左肘(注意两个人的左肘都会被预测出来),Fig2(b)右所示的heatmap预测的则是两个人的左肩,假设一共有J个heatmap,那么有
![]()
,且
![]()
,
![]()
。
然后再来说Fig2(c),其得到的是一组2D向量域,用符号L表示,有
![]()
,共有C个向量域(注意每个向量域内都有很多小向量,如Fig2(c)右所示),且有
![]()
,其中LcLc表示躯干(limb),比如左肩→→左肘等。我们只把有对称分布的才称为limb,比如面部就不属于limb。然后,通过贪心推理(greedy inference)解析confidence maps和PAFs(Part Affinity Fields),如Fig2(d)所示,最终得到最后的结果(见Fig2(e))。

3.1 Network Architecture
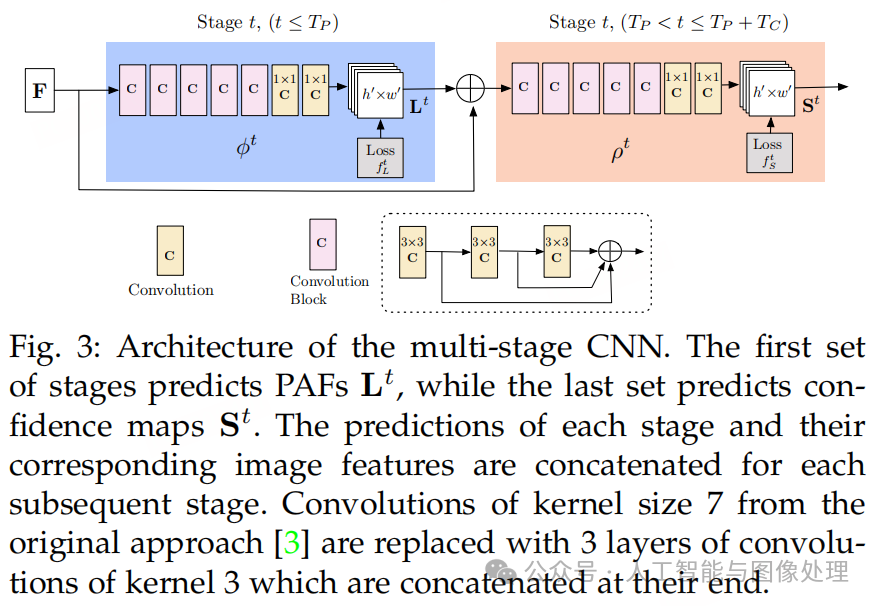
框架结构见Fig3,主要分为两个阶段:
1)PAFs阶段生成LL;
2)confidence map检测阶段生成S。
3.2 Simultaneous Detection and Association
输入图像先经过一个CNN(这个CNN使用VGG-19的前10层进行初始化,并进行了fine-tune)得到F。然后开始第一次迭代(即Stage 1),F首先被喂入PAFs阶段,得到
![]()
。然后继续进行PAFs阶段的第二次迭代(即Stage 2),第二次迭代的输入一部分来自上一次迭代的输出,另一部分来自图像特征FF,用公式可表示为:
![]()
PAFs阶段一共迭代TPTP次。接下来进入confidence map检测阶段的迭代。
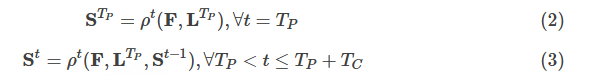
confidence map检测阶段一共迭代TC次,总迭代次数为T=TP+TCT=TP+TC,有t∈{1,…,T}。
Fig4展示了PAF的refine过程。

随着迭代次数的增加,PAF变得越来越精细,越来越准确。我们在PAFs阶段和confidence map检测阶段的末尾都添加了损失函数。
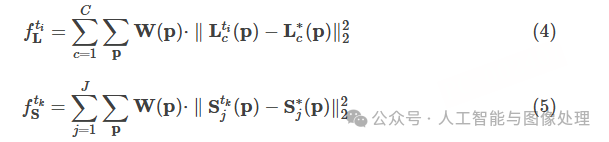
其中,Lc∗是PAF的GT,Sj∗是confidence map的GT,W是一个二值mask,当像素p没有标注时,有W(p)=0。总的损失函数表示为:

3.3.Confidence Maps for Part Detection
为了在训练中评估式(6)的
![]()
,我们根据标注的2D关节点生成了groundtruth confidence maps S∗。先考虑图像中只有一个人的情况,对于每个人kk的第jj个关节点,
![]()
是该点的真实像素位置,然后我们采用常见的高斯分布来生成heatmap:
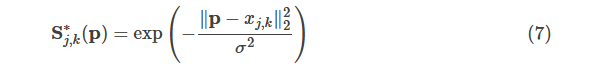
那如果是多人的情况,则会取一个最大值:
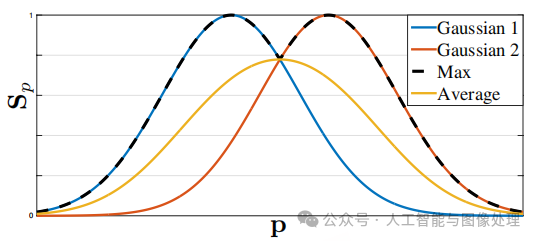
![]()
如下图所示,如果我们使用取平均而不是取最大值的方式,则会影响峰值附近的精度。在预测confidence map时使用了NMS。
3.4.Part Affinity Fields for Part Association
有了检测的关节点(如Fig5(a))之后,我们该如何将这些关节点匹配起来呢?我们需要计算每一对limb关节点(见Fig5(a)灰色线)的置信度,以判断它们是否属于同一个人。一个可行的方法是再额外检测出每一对limb关节点的中点(见Fig5(b)黄色点),以此来进一步判断每对limb关节点的归属。但这种方法会导致如Fig5(b)绿色线那样的错误。这种错误源自该方法的两个限制:1)只考虑了limb的位置,而没有考虑其方向;2)将limb的支持区域减少到了单个点。

PAF则解决了这些限制。PAF保留了limb支持区域的位置和方向信息(如Fig5(c)所示)。每一个PAF都是一个limb的2D向量域,如Fig1下右所示。2D向量域中的每个小向量都从limb的一端指向另一端。
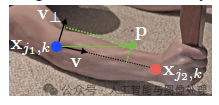
考虑如下图所示的limb。用
![]()
表示关节点的GT位置,k表示图像中的第k个人,
![]()
为limb c所连接的两个关节点。如果点p位于limb区域内,则该点的GT 2D向量表示为
![]()
,其是一个单位向量,方向从j1j1指向j2j2。而在非limb区域的点都设为零向量。
为了在训练中评估式(6)的fL,我们定义PAF的GT如下:
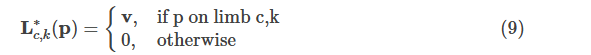
其中,
![]()
是一个单位向量。那么如何判断点p是否落在了limb c,k上呢?如果点p落在limb c,k区域内,则应满足下式:
![]()
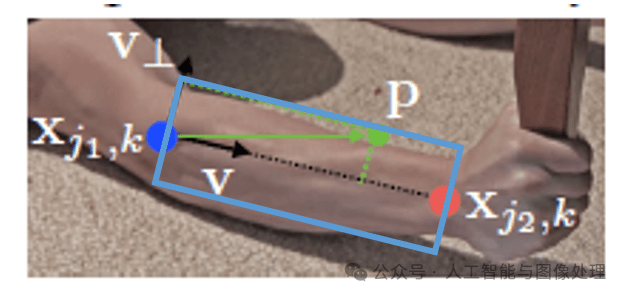
其中,σl是limb的宽度(单位是像素),宽度是沿着v⊥方向的,而v⊥是和vv垂直的。lc,kk是limb的长度(单位是像素),长度是沿着vv方向的。
简单解释下上式,
![]()
就是上图绿色向量(我们暂记为a),其和单位向量v进行点积:
![]()
,就相当于得到了绿色向量在v方向上的投影长度,我们要限制这个长度在
![]()
。在v⊥方向对宽度的限制同理。简单来说,其实每个limb区域就是一个旋转的矩形框(如下图蓝框所示),落在矩形框内的点即被视为落在了limb上。
考虑图像中的所有人,PAF的GT可定义为:

nc(p)为所有的k个人在点p处非零向量的个数。
在预测阶段,假设图像有两个人,heatmap1预测得到两个左肘位置(假设记为左肘1和左肘2),heatmap2预测得到两个左腕位置(假设记为左腕1和左腕2),那么我们该如何判断左肘1应该是和左腕1相连还是左腕2相连呢?因此我们需要一个关联置信度,来判断左肘1---左腕1相连更合适,还是左肘1-左腕2相连更合适。假设我们把左肘1记为dj1,左腕1记为dj2,那左肘1和左腕1相连得到的limb的PAF记为Lc,那么左肘1-左腕1的关联置信度可用下式计算:
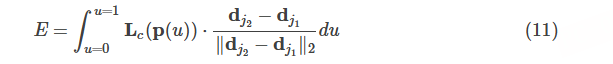
其中,p(u)是dj1和dj2之间的插值:
![]()
因为如果在计算关联置信度时考虑到limb区域内的所有点,会使得计算量很大,所以我们只考虑dj1和dj2所连线段上的点(即p(u))。因为线段上可以取无数多个点,所以在式(11)中用到了积分。而在实际实现时,我们会对u进行均匀间隔采样来近似积分。如果线段上的点对应的2D向量越接近沿着线段方向,那么算出来的关联置信度(即EE)就越大。
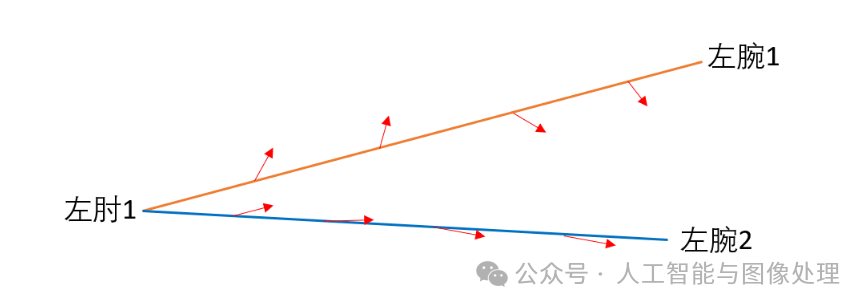
如上图所示,假设我们对u均匀采样了4个值,即在线段上取4个点,每个点对应的2D向量用红色箭头表示,左肘1-左腕2的关联置信度要高于左肘1-左腕1。
3.5.Multi-Person Parsing using PAFs
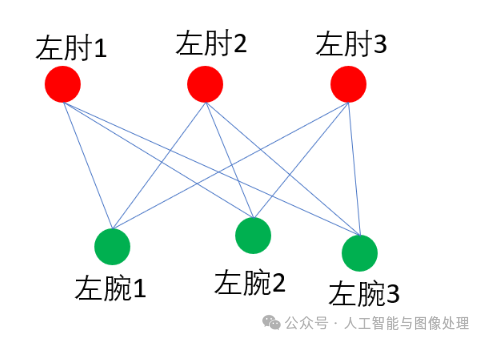
假设一张图里有3个人,那么我们预测可以得到3个左肘和3个左腕。如果不考虑同一类型关节点的连接,我们可以得到如下所有可能的连接方式:
这是一个典型的二分图最大匹配问题,我们可以用匈牙利算法来得到最大匹配(在匹配算法之前,我们可以通过一些限制条件来删掉一些边,比如把低于关联置信度阈值的连接删除),因为匈牙利算法的解不是唯一的,所以我们能得到多个最大匹配方案。比如下面是两种不同的最大匹配方案,我们该如何判断哪种匹配方案更好呢?
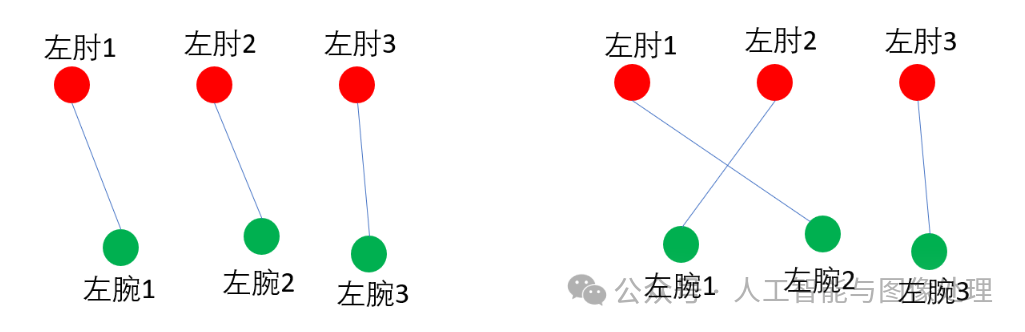
这就需要用到我们在第3.4部分介绍的关联置信度了,以上图左为例,该匹配方案的关联置信度可定义为:E(左肘1-左腕1)+E(左肘2-左腕2)+E(左肘3-左腕3)。我们的目标就是找到关联置信度最高的匹配方案。
首先在检测到的confidence map上使用NMS得到一系列关节点。由于图像中可能会存在多个人或者检测出现了假阳,同一类型的关节点会有多个候选点(见Fig6(b))。这些候选点能够定义出非常多可能的limb。对于这些limb,我们都可以用式(11)计算其关联置信度。但这种K维匹配属于是NP-Hard的问题(见Fig6(c),可简单理解为几乎无法在可接受时间内对K维匹配进行求解)。因此我们提出一种贪心松弛(greedy relaxation)的策略,其可以一直获得高质量的匹配。
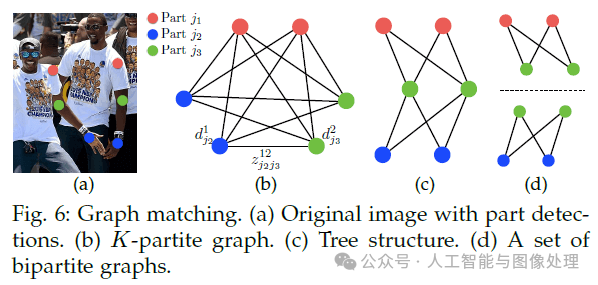
首先,我们定义一组关节点:
![]()
,其中,j表示关节点的类型,Nj表示类型为j的关节点的候选点数量,
![]()
表示类型为jj的关节点的第m个候选点。我们用
![]()
表示两个不同类型的关节点候选点
![]()
是否相连
![]()
,目标就是寻找一组最优连接。
为了避免K维匹配的NP难问题,我们一次只考虑一个limb,比如只考虑第c个limb,其连接的两个关节点为
![]()
(比如脖子和右髋),这样就将K维匹配转化成了多个最大权重的二分图匹配问题。二分图的两个点集分别是
![]()
,边是所有可能的连接。边的权重是通过式(11)计算得到的关联置信度。同一个点不能被两条边共享。我们的目标就是寻找权重最大的匹配方案:
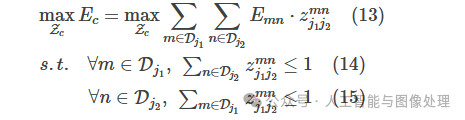
Ec是针对第c个limb的某一匹配方案的总权重,Zc是针对第c个limb的某一匹配方案,
![]()
的关联置信度(计算见式(11))。式(14)和式(15)用于限制两条边不能共用一个点,即两个同一类型的limb(比如两个左前臂)不能使用同一个关节点。我们可以使用匈牙利算法来获得最优匹配。
式(15)只考虑第c个limb,如果考虑全身所有的limb,则优化目标为:

只要我们把所有检测到且有共同关节点的limb组合起来,便可得到一个人的全身关节点。
我们现在的模型中包含了很多冗余的PAF连接(比如耳朵-肩膀、手腕-肩膀等)。这些冗余的连接提高了在拥挤图像中的精度,如Fig7所示。为了处理这些冗余连接,我们对多人解析算法进行了微调。在初始方法中,我们从一个limb开始,依次连接有共同关节点的其他limb,而微调之后的方法是,将所有limb按照PAF分数(即关联置信度)进行降序排列,从最高PAF分数的limb开始逐个连接。如果有一个连接试图连接已经分配给了两个不同人的关节点,那么这个连接会被忽略。

4. OPENPOSE
为了帮助其他的研究工作,我们开源了OpenPose,是第一个实时、多人系统,用于检测人物面部、脚部、手部和身体的关节点(一共135个关节点)。例子见Fig8。

4.1.System
现在可用的一些2D姿态估计库,比如Mask R-CNN或Alpha-Pose,都需要用户自己实现大部分的pipeline,比如他们自己的frame reader(比如视频、图像或相机流)以及自己去可视化结果。并且这些方法没有集成对脸部关节点的检测,OpenPose解决了这些问题。OpenPose可以在不同平台上运行,包括Ubuntu、Windows、Mac OSX和嵌入式系统(比如Nvidia Tegra TX2)。OpenPose还支持不同的硬件,比如CUDA GPUs、OpenCL GPUs以及CPU。用户的输入可以选择图像、视频、webcam和IP camera streaming。用户也可以选择是否显示结果并保存它们,可以enable或disable每个检测器(身体、脚、面部和手部),还支持像素坐标归一化,还能指定使用几块GPU,还可以选择是否跳帧来获得更快的处理等等。
OpenPose包括3个不同的block:1)body+foot检测;2)hand检测;3)face检测。其中,core block是body+foot检测器(见第4.2部分)。它可以使用在COCO和MPII上训练的body-only的模型。基于body-only检测模型得到的耳朵、眼睛、鼻子、脖子等关节点的位置,我们可以粗略得到facial bounding box proposals。类似的,通过胳膊关节点我们可以得到hand bounding box proposals。这里采用了第1部分提到的top-down的方式。手部关节点的检测算法见论文“T. Simon, H. Joo, I. Matthews, and Y. Sheikh, “Hand keypoint detection in single images using Multiview bootstrapping,” in CVPR, 2017.”,面部关节点检测算法的训练方式和手相同。OpenPose库还包括3D keypoint pose detection。
在保证高质量结果的同时,OpenPose的推理速度优于所有的SOTA方法。在Nvidia GTX 1080 Ti上能达到22 FPS(见第5.3部分)。
4.2.Extended Foot Keypoint Detection
现在的人体姿态数据集只包含有限的身体部位。MPII数据集标注了脚踝、膝盖、髋、肩膀、手肘、手腕、脖子、躯干和头顶,COCO还多包含了一些面部的关节点。对于这两个数据集,脚部标注就只有脚踝。然而,对于一些应用,比如3D人物重建,则需要脚部更多的关节点,比如大脚趾和脚跟。基于此,我们使用Clickworker平台对COCO数据集中的一部分数据进行了脚部关节点的标注。有14K个标注实例来自COCO训练集,有545个标注实例来自COCO验证集。一共标注了6个脚部关节点(见Fig9(a))。
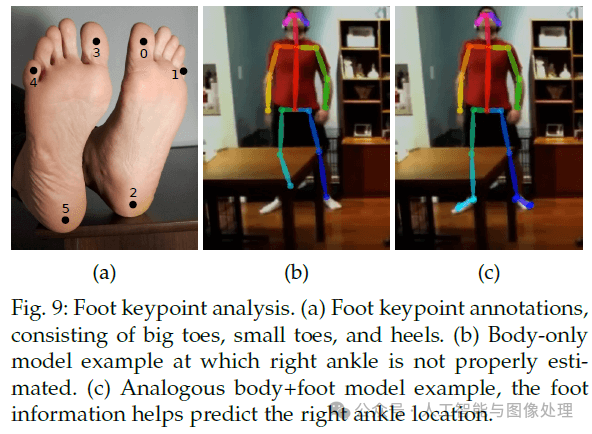
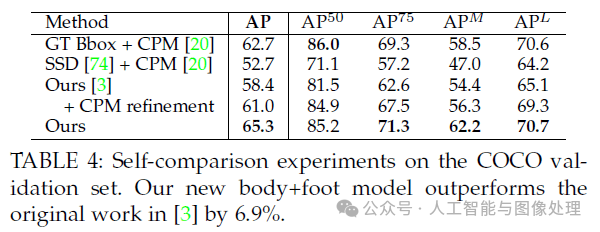
使用我们的数据集,我们训练了一个脚部关节点检测算法。最简单的想法是,我们基于身体关节点检测器生成脚部bbox proposals,然后再训练一个脚部检测器。但这种top-down结构存在一些特有问题(见第1部分)。因此,我们在先前提到的身体关节点检测器的框架中直接加入了对脚部关节点的预测。3种数据集(COCO、MPII、COCO+foot)的关节点标注见Fig10。即使上半身被遮挡或不在图像中,我们的body+foot模型依然可以检测到双腿和脚部。并且我们发现,脚部关节点潜在提升了身体关节点的检测精度,尤其是腿部关节点,比如脚踝位置,例子见Fig9(b)和Fig9(c)。

5. 数据集和评估
我们在多人姿态估计的3个benchmark上进行了评估:1)MPII数据集,包含3844个training groups和1758个testing groups,标注了14个身体关节点;2)COCO数据集,标注了17个关节点(12个身体关节点+5个面部关节点);3)我们自己的脚部数据集。我们的方法在COCO 2016 keypoints challenge中取得了第一名,在MPII上也大大超过了其他SOTA方法。
5.1.Results on the MPII Multi-Person Dataset
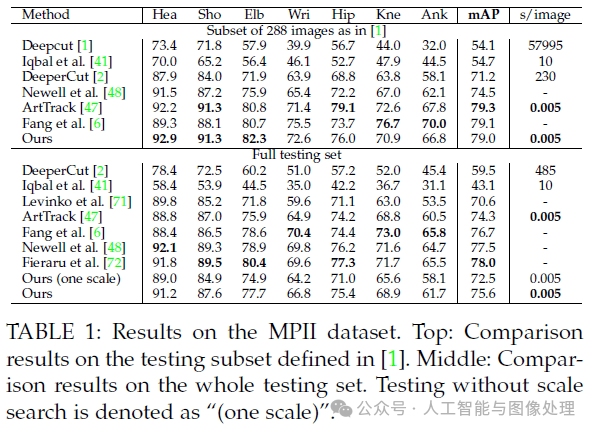
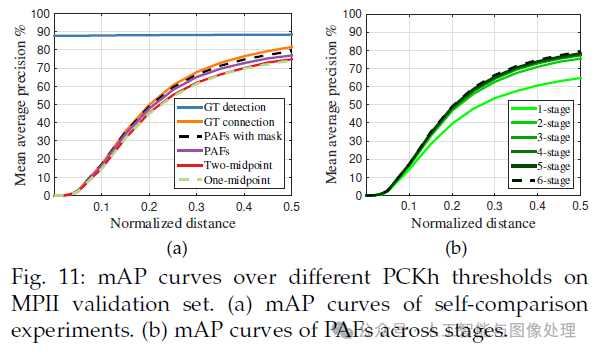
表1中”Ours(one scale)”表示没有使用scale search,”Ours”表示使用了3种scale search(×0.7,×1,×1.3)。
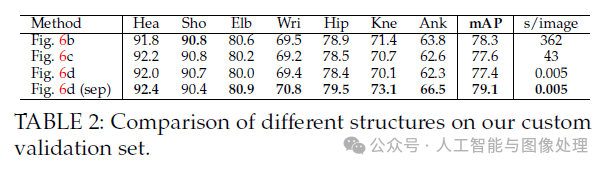
表2是Fig6中不同匹配策略的测试结果。我们从原始的MPII训练集中选取了343张图像作为我们的自定义验证集。Fig6(d)是本文提出的方法。这几种策略得到了相似的结果,说明使用最小边(minimal edges)就足够了。我们训练我们的最终模型,只学习最小边以充分利用network capacity,见Fig. 6d (sep)。
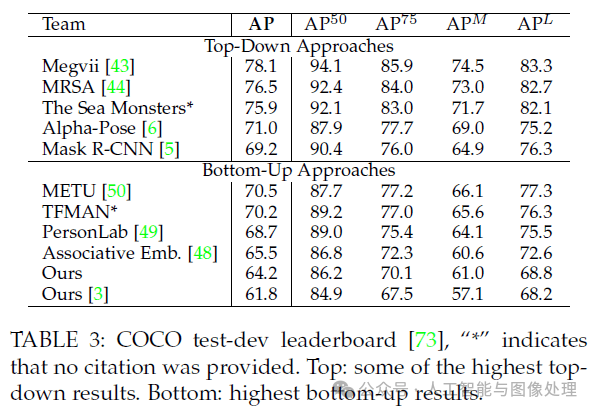
5.2.Results on the COCO Keypoints Challenge
COCO训练集包括超过100K个人物实例,共计超1百万个标注关节点。测试集包含”test-challenge”和”test-dev”子集,每个子集约20K张图像。
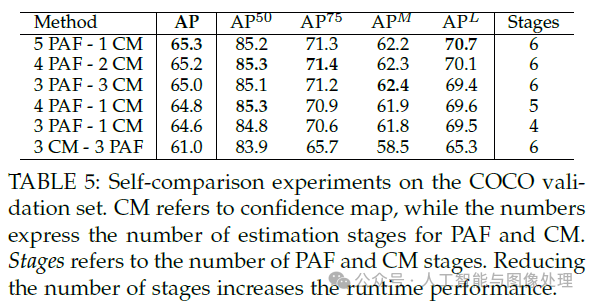
5.3.Inference Runtime Analysis
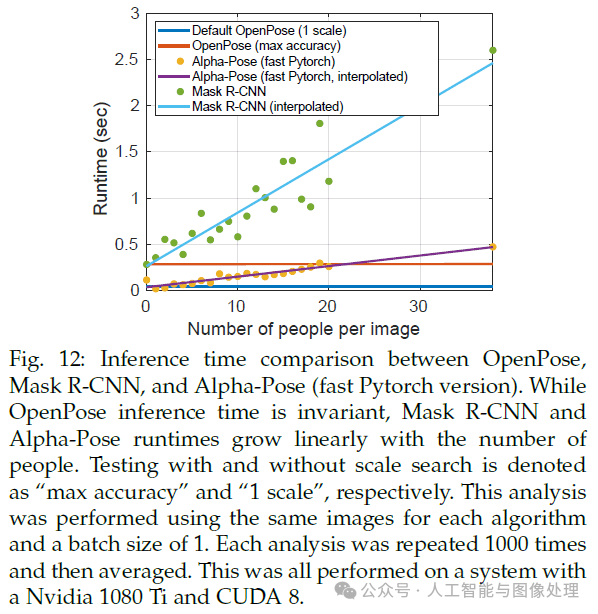
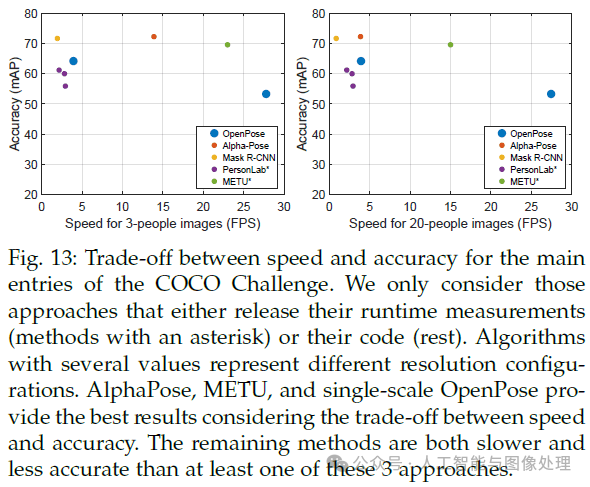
5.4.Trade-off between Speed and Accuracy
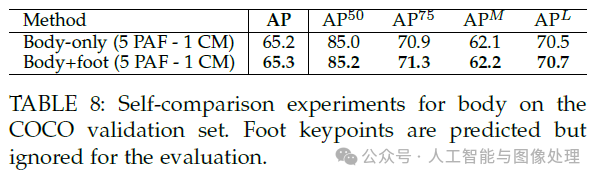
5.5.Results on the Foot Keypoint Dataset

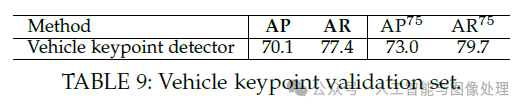
5.6.Vehicle Pose Estimation
OpenPose还可以用于车辆关键点的检测。

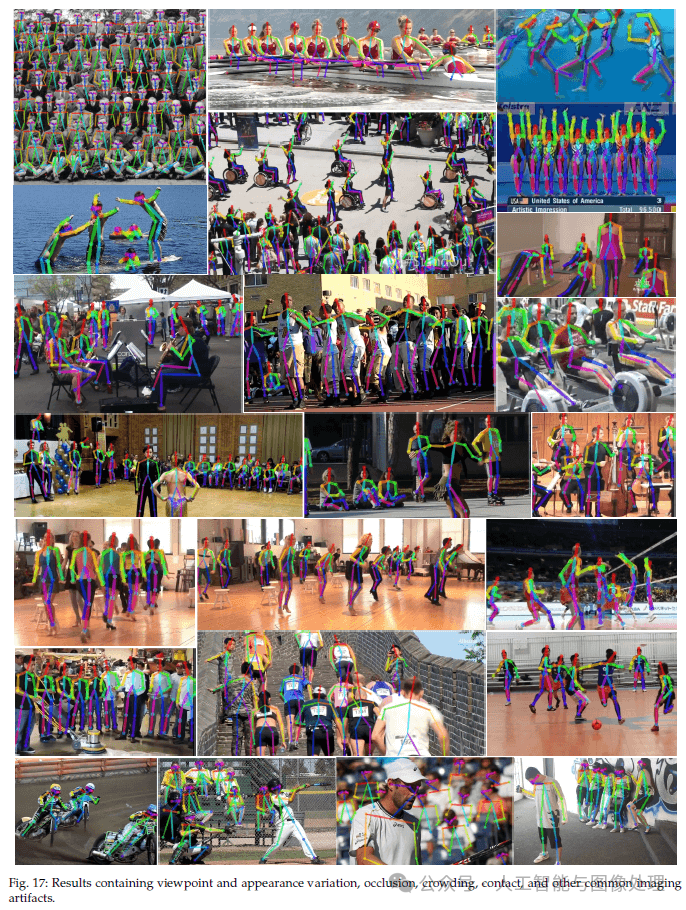
5.7.Failure Case Analysis

6. 结论
OpenPose已经被集成到OpenCV里了。
调用封装到opencv里的openpose库函数处理图像
# -*-coding: utf-8 -*-
import cv2 as cvimport osimport glob
BODY_PARTS = {"Nose": 0, "Neck": 1, "RShoulder": 2, "RElbow": 3, "RWrist": 4, "LShoulder": 5, "LElbow": 6, "LWrist": 7, "RHip": 8, "RKnee": 9, "RAnkle": 10, "LHip": 11, "LKnee": 12, "LAnkle": 13, "REye": 14, "LEye": 15, "REar": 16, "LEar": 17, "Background": 18}
POSE_PAIRS = [["Neck", "RShoulder"], ["Neck", "LShoulder"], ["RShoulder", "RElbow"], ["RElbow", "RWrist"], ["LShoulder", "LElbow"], ["LElbow", "LWrist"], ["Neck", "RHip"], ["RHip", "RKnee"], ["RKnee", "RAnkle"], ["Neck", "LHip"], ["LHip", "LKnee"], ["LKnee", "LAnkle"], ["Neck", "Nose"], ["Nose", "REye"], ["REye", "REar"], ["Nose", "LEye"], ["LEye", "LEar"]]
def detect_key_point(model_path, image_path, out_dir, inWidth=368, inHeight=368, threshhold=0.2): net = cv.dnn.readNetFromTensorflow(model_path) frame = cv.imread(image_path) frameWidth = frame.shape[1] frameHeight = frame.shape[0] scalefactor = 2.0 net.setInput( cv.dnn.blobFromImage(frame, scalefactor, (inWidth, inHeight), (127.5, 127.5, 127.5), swapRB=True, crop=False)) out = net.forward() out = out[:, :19, :, :] # MobileNet output [1, 57, -1, -1], we only need the first 19 elements assert (len(BODY_PARTS) == out.shape[1]) points = [] for i in range(len(BODY_PARTS)): # Slice heatmap of corresponging body's part. heatMap = out[0, i, :, :] # Originally, we try to find all the local maximums. To simplify a sample # we just find a global one. However only a single pose at the same time # could be detected this way. _, conf, _, point = cv.minMaxLoc(heatMap) x = (frameWidth * point[0]) / out.shape[3] y = (frameHeight * point[1]) / out.shape[2] # Add a point if it's confidence is higher than threshold. points.append((int(x), int(y)) if conf > threshhold else None) for pair in POSE_PAIRS: partFrom = pair[0] partTo = pair[1] assert (partFrom in BODY_PARTS) assert (partTo in BODY_PARTS)
idFrom = BODY_PARTS[partFrom] idTo = BODY_PARTS[partTo]
if points[idFrom] and points[idTo]: cv.line(frame, points[idFrom], points[idTo], (0, 255, 0), 5) cv.ellipse(frame, points[idFrom], (5, 5), 0, 0, 360, (0, 0, 255), cv.FILLED) cv.ellipse(frame, points[idTo], (5, 5), 0, 0, 360, (0, 0, 255), cv.FILLED)
t, _ = net.getPerfProfile() freq = cv.getTickFrequency() / 1000 cv.putText(frame, '%.2fms' % (t / freq), (10, 20), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
cv.imwrite(os.path.join(out_dir, os.path.basename(image_path)), frame) # cv.imshow('OpenPose using OpenCV', frame) # cv.waitKey(0)
def detect_image_list_key_point(image_dir, out_dir, inWidth=480, inHeight=480, threshhold=0.3): image_list = glob.glob(image_dir) for image_path in image_list: detect_key_point(image_path, out_dir, inWidth, inHeight, threshhold)
if __name__ == "__main__": model_path = "pb/graph_opt.pb" # image_path = "body/*.jpg" out_dir = "result" # detect_image_list_key_point(image_path,out_dir) image_path = "./test4.jpeg" detect_key_point(model_path, image_path, out_dir, inWidth=368, inHeight=368, threshhold=0.1) print("结束!")

图片来自网络(侵删)
三,相关地址:
论文地址:https://arxiv.org/abs/1812.08008
代码地址:https://github.com/tensorboy/pytorch_Realtime_Multi-Person_Pose_Estimation
四,参考文章:
论文翻译 || openpose -- Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields-CSDN博客
https://shichaoxin.com/2024/03/10/%E8%AE%BA%E6%96%87%E9%98%85%E8%AF%BB-OpenPose-Realtime-Multi-Person-2D-Pose-Estimation-using-Part-Affinity-Fields/

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









