








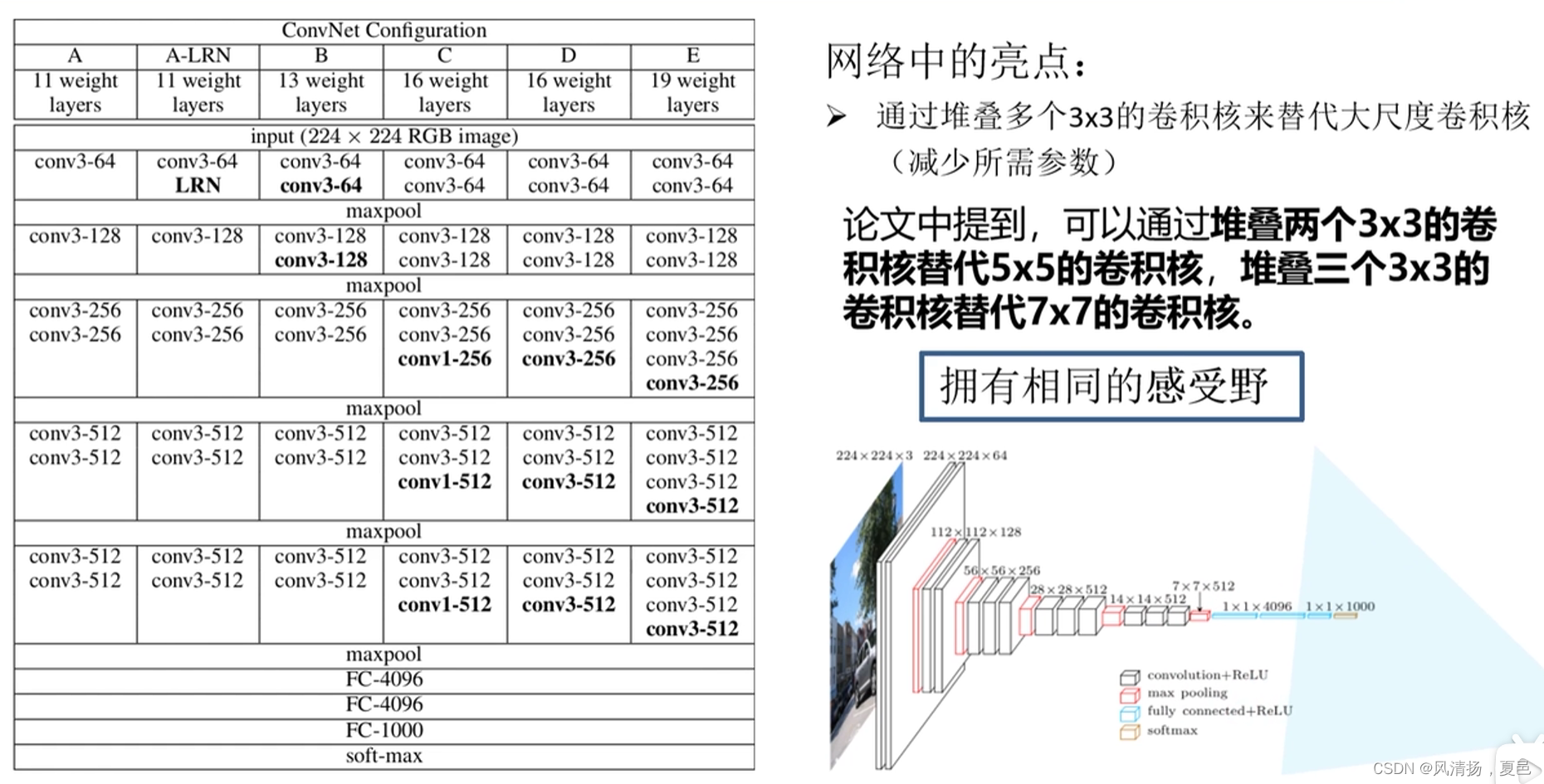
VGG网络具体的网络结构
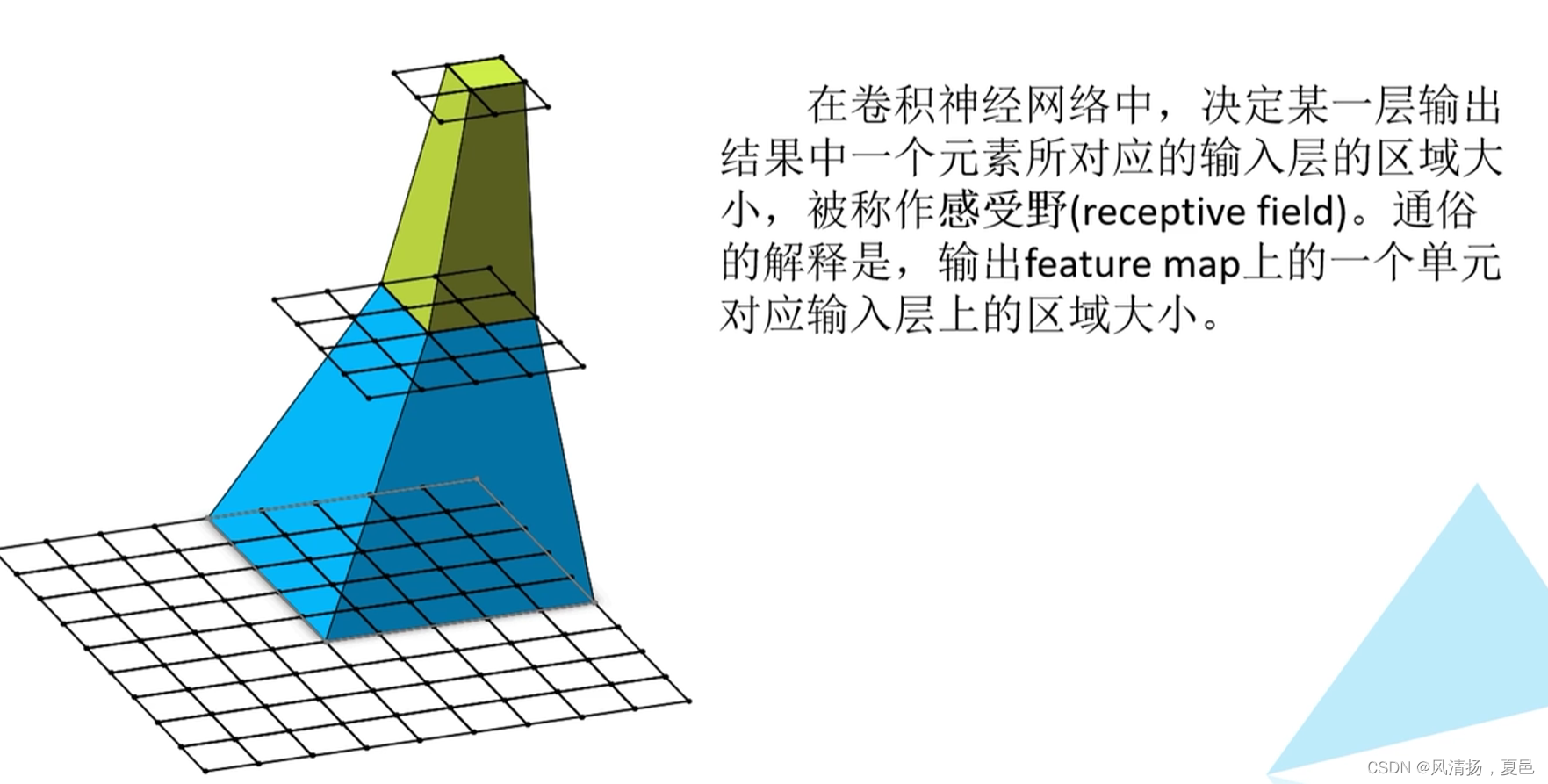
感受野概念
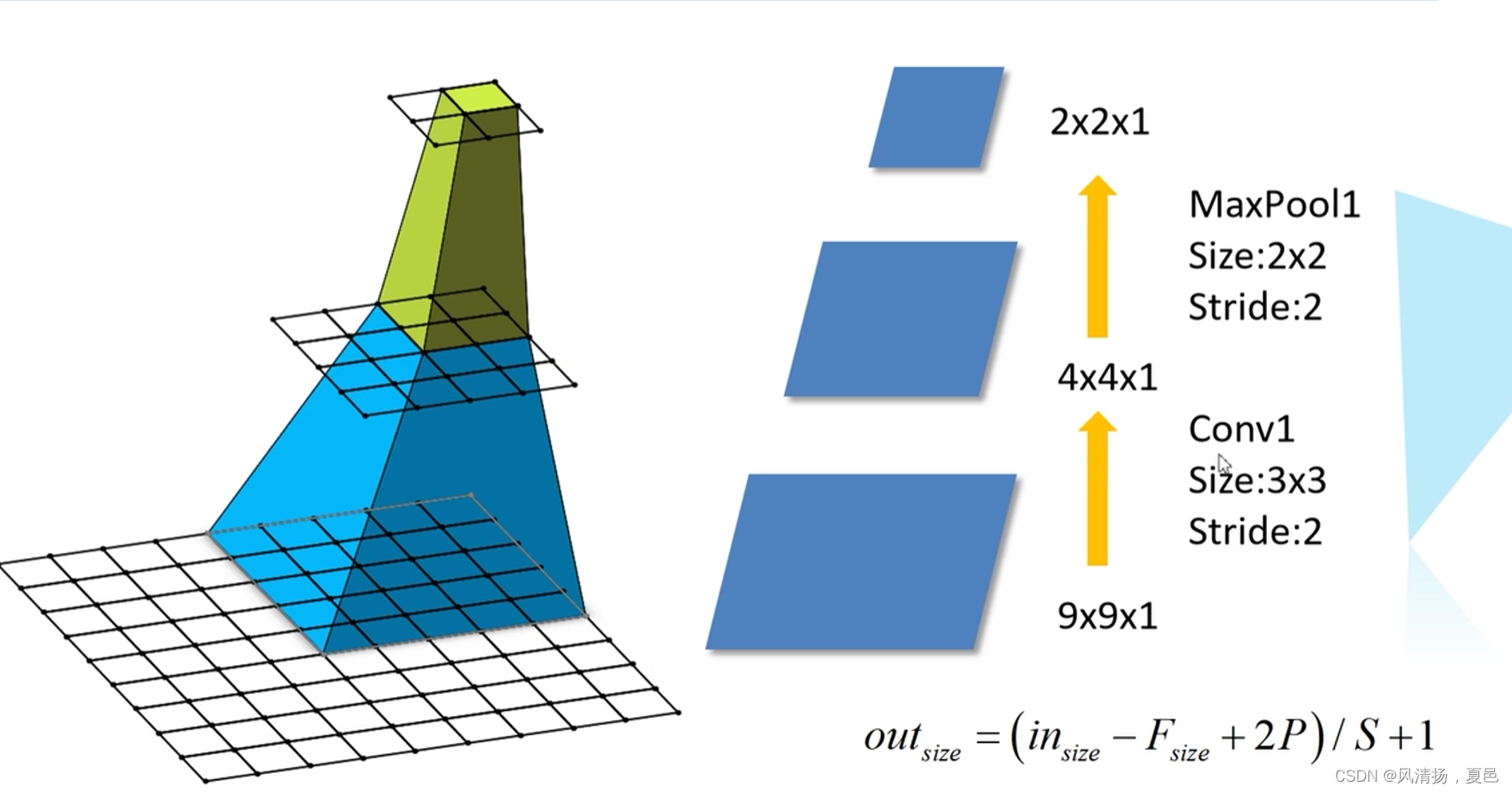
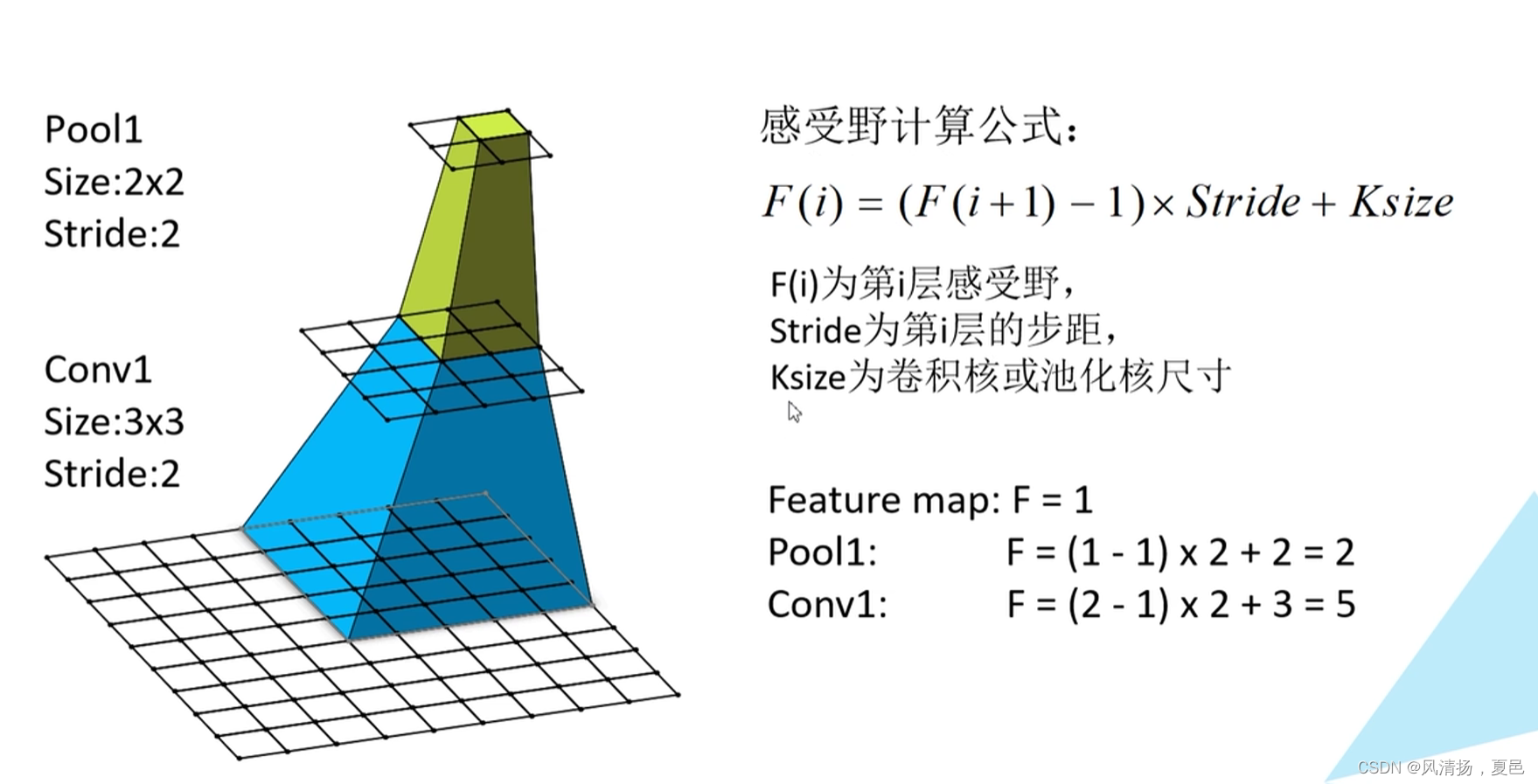
感受野的计算
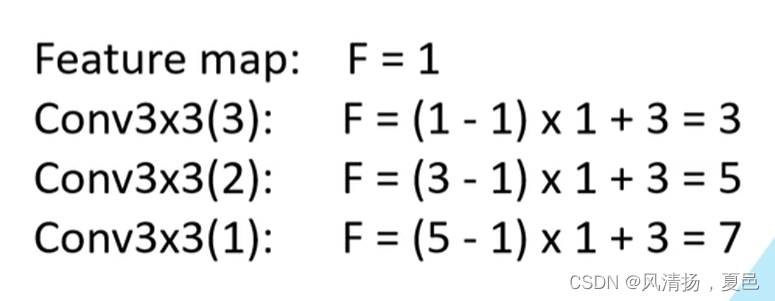


写入模型的脚本
model
import torch.nn as nn
import torch
# official pretrain weights
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
class VGG(nn.Module): #定义VGG,继承自nn.Module
def __init__(self, features, num_classes=1000, init_weights=False): #初始化构造函数传入的参数有提取网络特征的features,类别数,是否初始化权重
super(VGG, self).__init__()
self.features = features
#生成三层全连接层
self.classifier = nn.Sequential( #nn.Sequential生成分类网络结构
nn.Linear(512*7*7, 4096), #全连接层展平处理
nn.ReLU(True), #全连接层加入激活函数
nn.Dropout(p=0.5), #展平之后加入dropout函数,目的是为了减少过拟合,50%比例随机失活神经元
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights: #是否参数权重的初始化,如果为true,进入到初始化函数_initialize_weights()当中
self._initialize_weights()
def forward(self, x): #输入数据x
# N x 3 x 224 x 224
x = self.features(x) #将数据通过定义好的提取特征方法,得到输出
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1) #将输出进行展平处理,通过维度1开始展平
# N x 512*7*7
x = self.classifier(x) #展平之后送人我们定义好的分类网络函数中,得到输出
return x
def _initialize_weights(self):
for m in self.modules(): #遍历每一个子模块
if isinstance(m, nn.Conv2d): #如果遍历的当前层是卷积层
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight) #使用xavier初始化方法初始化卷积核的权重
if m.bias is not None: #如果采用偏执,偏执初始化为0
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear): #如果遍历的是全连接层,初始化全连接层的参数,如果有偏执,初始化为0
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
#通过make_features()生成提取特征网络层结构
def make_features(cfg: list): #传入对应配置的列表
layers = [] #创建空列表,用来传入我们所定义的每一层的结构
in_channels = 3 #输入的是RGB彩色图片,所以输入通道为3
for v in cfg: #遍历配置列表
if v == "M": #如果是最大池化层
layers += [nn.MaxPool2d(kernel_size=2, stride=2)] #创建一个最大池化下采样层nn.MaxPool2d,池化核和步距都是2
else: #否则的话就是卷积层,创建一个卷积操作nn.Conv2d
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)#in_channels=3,输出的特征矩阵深度对应卷积核的个数
layers += [conv2d, nn.ReLU(True)] #卷积核大小3*3,步距和padding都为1,默认步距为1 的话可以不写
in_channels = v #将定义好的卷积层和relu激活函数拼接在一起,并添加到事先定义好的layers当中。特征矩阵变成的输出深度变成了卷积后的v
#下次遍历的时候卷积层的输入就变成了上层的输出
return nn.Sequential(*layers) #nn.Sequential将列表通过非关键字的形式传入,*代表是通过非关键字传入的
#定义模型的字典文件,每个key代表着模型的配置文件。例如vgg11代表着表格中的A的配置,也就是11层的网络结构
#数字代表那一层卷积核的个数,M代表着最大下采样池化层
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs): #通过vgg实例化我们所需要配置的模型
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name] #将key值传入文件中,得到我们想要的配置列表
model = VGG(make_features(cfg), **kwargs) #通过类VGG实例化VGG网络,传入features参数,features通过make_features函数定义的
return model #两个*是可变长度的字典变量
训练脚本
train
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import vgg
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
epochs = 30
best_acc = 0.0
save_path = './{}Net.pth'.format(model_name)
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
预测脚本
predict
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import vgg
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = vgg(model_name="vgg16", num_classes=5).to(device)
# load model weights
weights_path = "./vgg16Net.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()















 6834
6834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









