







本文作为自己学习李宏毅老师2021春机器学习课程所做笔记,记录自己身为入门阶段小白的学习理解,如果错漏、建议,还请各位博友不吝指教,感谢!!
逐层归一化
逐层归一化可以有效地提高训练效率,其原因有以下几个方面:
- 更好的尺度不变性:在深度神经网络中,一个神经层的输入是之前神经层的输出,给定一个神经层 l l l,它之前的神经层 ( 1 , ⋯ , l − 1 ) (1, \cdots, l-1) (1,⋯,l−1)的参数变化会导致其输入的分布发生较大的变化。当使用随机梯度下降来训练网络时,每次参数更新都会导致该神经层的输入分布发生改变。从机器学习角度来看,如果一个神经层的输入分布发生了改变,那么其参数需要重新学习,这种现象叫做内部协变量偏移(Internal Covariate Shift)。为了缓解这一问题,我们可以对神经层的输入做归一化,使其分布保持稳定。把每个神经层的输入分布都归一化为标准正态分布,可以使得每个神经层对其输入具有更好的尺度不变性。不论低层的参数怎么变化,高层的输入保持相对稳定。另外,尺度不变性可以使得我们更加高效的进行参数初始化以及超参选择。
- 更平滑的优化地形:逐层归一化一方面可以使得大部分神经层的输入处于不饱和区域,从而让梯度变大,避免梯度消失问题;另一方面还可以使得神经网络的优化地形(Optimization Landscape)更加平滑,以及使梯度变得更加稳定,从而允许使用更大的学习率,并提高收敛率。
批量归一化
批量归一化(Batch Normalization,BN)可以对神经网络中任意的中间层进行归一化操作。其实是对中间层的单个神经元进行归一化操作,所以要求小批量样本的数量(Batch size)不能太少,否则不能计算单个神经元的统计信息。对于一个深度神经网络,令第
l
l
l层的净输入为
z
(
l
)
z^{(l)}
z(l),神经元的输出为
a
(
l
)
a^{(l)}
a(l),即
a
(
l
)
=
f
(
z
(
l
)
)
=
f
(
W
a
(
l
−
1
)
+
b
)
a^{(l)} = f(z^{(l)}) = f(Wa^{(l-1)} + b)
a(l)=f(z(l))=f(Wa(l−1)+b)
其中
f
(
⋅
)
f(\cdot)
f(⋅)是激活函数,
W
W
W和
b
b
b是可学习的参数。批量归一化也就是对
z
(
l
)
z^{(l)}
z(l)进行归一化操作。一般使用标准化将净输入
z
(
l
)
z^{(l)}
z(l)的每一维都归一到标准正态分布。
z
^
(
l
)
=
z
(
l
)
−
E
[
z
(
l
)
]
v
a
r
(
z
(
l
)
)
+
ϵ
\hat{z}^{(l)} = \frac{z^{(l)}-\mathbb{E}[z^{(l)}]}{\sqrt{var(z^{(l)})+\epsilon}}
z^(l)=var(z(l))+ϵz(l)−E[z(l)]
其中
ϵ
\epsilon
ϵ是为了防止除数为0而设置的非常小的常数;
E
[
z
(
l
)
]
\mathbb{E}[z^{(l)}]
E[z(l)]和
v
a
r
(
z
(
l
)
)
var(z^{(l)})
var(z(l))是指当前参数下,
z
(
l
)
z^{(l)}
z(l)的每一维在整个训练集上的期望和方差。
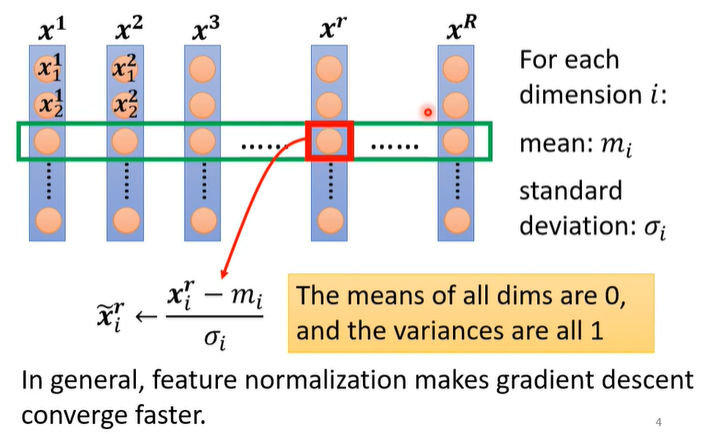
如上图所示,对整个数据集中的第
i
i
i维数据,首先计算这一维度上所有数据的期望
m
i
m_i
mi和标准差
σ
i
\sigma_i
σi,然后对这一个维度中的每一个数据进行归一化操作:
x
~
i
r
←
x
i
r
−
m
i
σ
i
\widetilde{x}_i^r \leftarrow \frac{x_i^r-m_i}{\sigma_i}
x
ir←σixir−mi
上述提到的算法都是针对整个数据集来进行归一化的,但是目前的主要优化算法是基于小批量的随机梯度下降法,所以准确地计算整个数据集上的期望和方差(标准差)是不可行的。因此,批量归一化中的期望和方差(标准差)通常用当前小批量样本集的均值和方差来近似的估计,方法如下:
给定一个包含K个样本的小批量样本集合,第
l
l
l层神经元的净输入
z
(
1
,
l
)
,
⋯
,
z
(
K
,
l
)
z^{(1,l)} , \cdots,z^{(K,l)}
z(1,l),⋯,z(K,l)的均值和方差为:
μ
=
1
K
∑
k
=
1
K
z
(
k
,
l
)
σ
2
=
1
K
∑
k
=
1
K
(
z
(
k
,
l
)
−
μ
)
⊙
(
z
(
k
,
l
)
−
μ
)
\begin{aligned} & \mu = \frac{1}{K} \sum_{k=1}^K z^{(k,l)} \\ & \sigma^2 = \frac{1}{K} \sum_{k=1}^K (z^{(k,l)}-\mu) \odot (z^{(k,l)}-\mu) \end{aligned}
μ=K1k=1∑Kz(k,l)σ2=K1k=1∑K(z(k,l)−μ)⊙(z(k,l)−μ)
对净输入
z
(
l
)
z^{(l)}
z(l)的标准归一化会使得其取值集中到0附近,如果使用sigmoid型激活函数时,这个取值区间刚好是接近线性变换区间,减弱了神经网络的非线性性质。因此,为了使得归一化不对网络的表示能力造成负面影响,可以通过一个附加的缩放和平移变换改变取值区间。
z
^
(
l
)
=
z
(
l
)
−
μ
σ
2
+
ϵ
⊙
γ
+
β
≜
B
N
γ
,
β
(
z
(
l
)
)
\begin{aligned} \hat{z}^{(l)} &= \frac{z^{(l)}-\mu}{\sqrt{\sigma^2 + \epsilon}} \odot \gamma + \beta \\ & \triangleq BN_{\gamma, \beta}(z^{(l)}) \end{aligned}
z^(l)=σ2+ϵz(l)−μ⊙γ+β≜BNγ,β(z(l))
其中
γ
\gamma
γ和
β
\beta
β分别代表缩放和平移的参数向量。而对于这两个参数向量的取值有两种讨论:
讨论一:《神经网络与深度学习》
从最保守的角度考虑,可以通过标准归一化的逆变换来使得归一化后的变量可以被还原为原来的值。即,当
γ
=
σ
2
,
β
=
μ
\gamma = \sqrt{\sigma^2},\beta=\mu
γ=σ2,β=μ时,
z
^
(
l
)
=
z
(
l
)
\hat{z}^{(l)}=z^{(l)}
z^(l)=z(l)。
PS:这样子不就相当于没有进行批量归一化吗?直接不再使用批量归一化就可以了吧?存疑,有路过的大佬还请指教一下,感谢!
讨论二:李宏毅老师
将
γ
\gamma
γ中的元素全部初始化为1,
β
\beta
β中的元素全部初始化为0,当在训练过程中找到合适的值后,再对其进行替换。
上述讨论的批量归一化算法都是用于train阶段的,在test阶段中,有时候batch size的值很小,是无法计算出
μ
\mu
μ和
σ
\sigma
σ的,对于这种情况在pytorch中是通过计算train中的
μ
\mu
μ和
σ
\sigma
σ的移动加权平均来实现的,具体如下:
μ
ˉ
=
p
μ
ˉ
+
(
1
−
p
)
μ
t
σ
ˉ
=
p
σ
ˉ
+
(
1
−
p
)
σ
t
\begin{aligned} & \bar{\mu} = p \bar{\mu} + (1-p)\mu^t \\ & \bar{\sigma} = p \bar{\sigma} + (1-p)\sigma^t \end{aligned}
μˉ=pμˉ+(1−p)μtσˉ=pσˉ+(1−p)σt
其中
t
t
t是在train过程中batch的下标,p一般取值为0.1,计算完成后再实行批量归一化。
层归一化
上边提到批量归一化是对中间层的某一个神经元进行归一化,而层归一化(Layer Normalization)则是对一个中间层的所有神经元进行归一化。
对于一个深度神经网络,令第
l
l
l层神经元的净输入为
z
(
l
)
z^{(l)}
z(l),其均值和方差为:
μ
(
l
)
=
1
M
l
∑
i
=
1
M
l
z
i
(
l
)
σ
(
l
)
2
=
1
M
l
∑
i
=
1
M
l
(
z
i
(
l
)
−
μ
(
l
)
)
2
\begin{aligned} & \mu^{(l)} = \frac{1}{M_l} \sum^{M_l}_{i=1} z^{(l)}_i \\ & \sigma^{(l)^2}= \frac{1}{M_l} \sum^{M_l}_{i=1}(z_i^{(l)}- \mu^{(l)})^2 \end{aligned}
μ(l)=Ml1i=1∑Mlzi(l)σ(l)2=Ml1i=1∑Ml(zi(l)−μ(l))2
其中
M
l
M_l
Ml为第
l
l
l层神经元的数量。
层归一化定位为:
z
^
(
l
)
=
z
(
l
)
−
μ
(
l
)
σ
(
l
)
2
+
ϵ
⊙
γ
+
β
≜
L
N
γ
,
β
(
z
(
l
)
)
\begin{aligned} \hat{z}^{(l)} & = \frac{z^{(l)}-\mu^{(l)}}{\sqrt{\sigma^{(l)^2}+ \epsilon}} \odot \gamma + \beta \\ & \triangleq LN_{\gamma,\beta}(z^{(l)}) \end{aligned}
z^(l)=σ(l)2+ϵz(l)−μ(l)⊙γ+β≜LNγ,β(z(l))
其中 γ \gamma γ和 β \beta β分别代表缩放和平移的参数向量,和 z ( l ) z^{(l)} z(l)维数相同。
注意与批量归一化的区别:批量归一化是不同训练数据之间对单个神经元的归一化,层归一化是单个训练数据对某一层所有神经元之间的归一化。 所以,应当注意这两个“之间”,搞清楚到底是谁与谁进行求平均、方差,乃至归一化。
BN和LN的区别
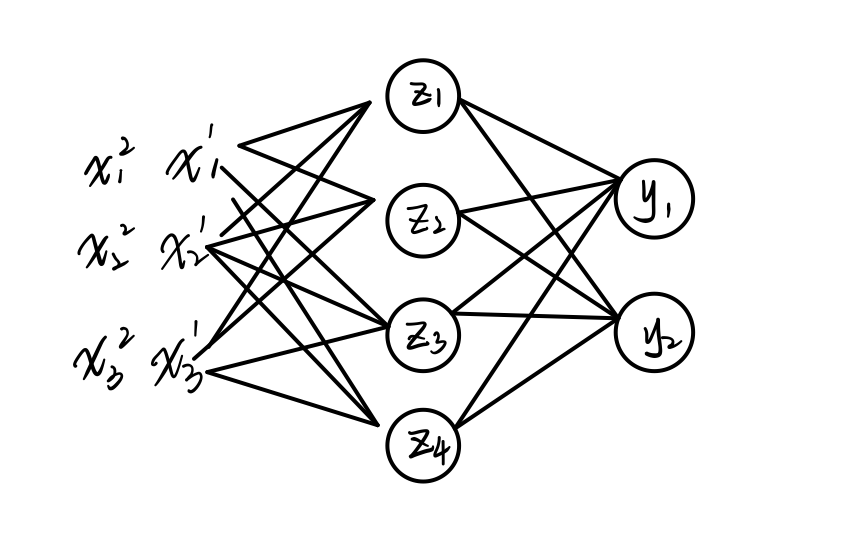
假设上图中,神经网络只有一个隐藏层( Z = [ z 1 , z 2 , z 3 , z 4 ] Z=[z_1, z_2, z_3, z_4] Z=[z1,z2,z3,z4]),在训练过程中,当前批次只有两个训练样本( X 1 = [ x 1 1 , x 2 1 , x 3 1 , x 4 1 ] , X 2 = [ x 2 1 , x 2 2 , x 3 2 , x 4 2 ] X_1=[x^1_1, x_2^1, x_3^1, x_4^1], X_2=[x^1_2, x_2^2, x_3^2, x_4^2] X1=[x11,x21,x31,x41],X2=[x21,x22,x32,x42])。
虽然BN和LN都采用如下公式,进行归一化:
z
^
(
l
)
=
z
(
l
)
−
μ
σ
2
+
ϵ
⊙
γ
+
β
(1)
\hat{z}^{(l)} = \frac{z^{(l)}-\mu}{\sqrt{\sigma^2 + \epsilon}} \odot \gamma + \beta \tag{1}
z^(l)=σ2+ϵz(l)−μ⊙γ+β(1)
但主要区别是不是在于两者的归一化对象不同,即期望 μ \mu μ和方差 σ 2 \sigma^2 σ2的计算方式不同:
BN的一次归一化过程:
- 使用 X 1 X_1 X1计算得到 z 1 1 z_1^1 z11
- 使用 X 2 X_2 X2计算得到 z 1 2 z_1^2 z12
- 计算 z 1 1 z_1^1 z11和 z 1 2 z_1^2 z12对应的 μ \mu μ和 σ 2 \sigma^2 σ2代入公式(1)进行归一化
LN的一次归一化过程:
- 使用 X 1 X_1 X1计算得到隐藏层所有神经元的净输入 Z 1 = [ z 1 1 , z 2 1 , z 3 1 , z 4 1 ] Z^1=[z_1^1, z_2^1, z_3^1, z_4^1] Z1=[z11,z21,z31,z41]
- 计算 Z 1 Z^1 Z1中所有元素对应的 μ \mu μ和 σ 2 \sigma^2 σ2,代入公式(1)进行归一化
综上所述,BN是使用不同的训练数据对同一个神经元进行归一化(同时,BN也可以看作是按通道进行归一化),LN是使用同样的训练数据对同一个隐藏层的所有神经元进行归一化
局部响应归一化
局部响应归一化(Local Response Normalization,LRN)引入的原因:
局部响应归一化和生物神经元中的侧抑制(lateral inhibition)现象比较类似,即活跃神经元对相邻神经元具有抑制作用.当使用ReLU作为激活函数时,神经元的活性值是没有限制的,局部响应归一化可以起到平衡和约束作用.如果一个神经元的活性值非常大,那么和它邻近的神经元就近似地归一化为 0,从而起到抑制作用,增强模型的泛化能力.
LRN公式
假设一个卷积层的输出特征映射
Y
∈
R
M
′
×
N
′
×
P
Y \in \mathbb{R}^{M' \times N' \times P}
Y∈RM′×N′×P为三维张量,其中每个切片矩阵
Y
p
∈
R
M
′
×
N
′
Y^p \in \mathbb{R}^{M' \times N'}
Yp∈RM′×N′为一个输出特征映射,
1
≤
p
≤
P
1 \le p \le P
1≤p≤P(P为输出的channel数)。
Y
^
p
=
Y
p
/
(
k
+
α
∑
j
=
max
(
1
,
p
−
n
2
)
min
(
P
,
p
+
n
2
)
(
Y
j
)
2
)
β
≜
L
R
N
n
,
k
,
α
,
β
(
Y
p
)
\begin{aligned} \hat{Y}^p &= Y^p / \left(k + \alpha\sum^{\min(P, p+\frac{n}{2})}_{j=\max(1, p-\frac{n}{2})}(Y^j)^2\right)^{\beta} \\ & \triangleq LRN_{n,k,\alpha,\beta}(Y^p) \end{aligned}
Y^p=Yp/⎝⎛k+αj=max(1,p−2n)∑min(P,p+2n)(Yj)2⎠⎞β≜LRNn,k,α,β(Yp)
其中除和幂运算都是按元素运算,
n
,
k
,
α
,
β
n, k, \alpha, \beta
n,k,α,β为超参,
n
n
n为局部归一化的特征窗口大小。
Y
Y
Y是卷积层的输出结果,这个输出结果的结构是一个思维数组[batch, height, width, channel],那么值为[a,b,c,d]的
Y
Y
Y可以理解为再第a张图(一个批次中只有一张图片)的第d个通道下的高度为b,宽度为c的点。而求和是在channel的方向上求和的,也就是这个点同方向的前面n/2个通道(最小为第0个通道)和后n/2个通道(最大为d-1个通道)的点的平方和(共n+1个点)。
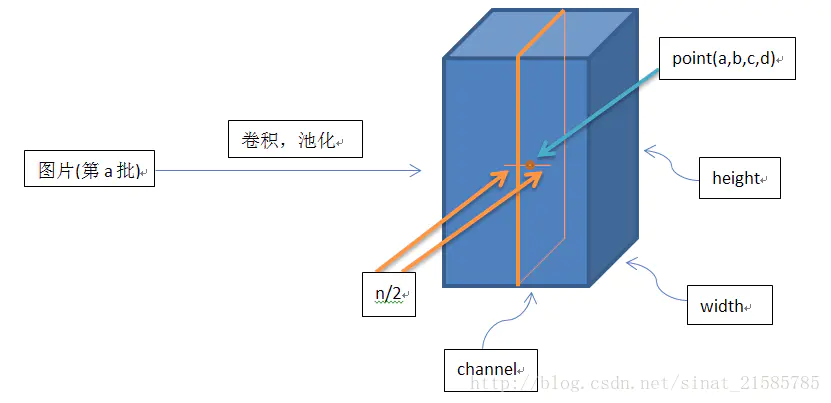
(图片来自:https://www.jianshu.com/p/c014f81242e7)
参考资料:
- 《神经网络与深度学习》 邱锡鹏
- 批量归一化与层归一化的区别参考处:https://blog.csdn.net/a1367666195/article/details/105360306
- 局部响应归一化:https://www.jianshu.com/p/c014f81242e7
- BN按通道归一化:https://zhuanlan.zhihu.com/p/74476637















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









