







一、前言
你是否有在为数据集少的问题而困扰,那么半自动化标注的技能就能解决现有问题,思路就是先用已经训练好的一个模型,使用yolov5 detect.py 再去对新图片进行识别,识别自动生成classes文件,然后用labelimg打开识别好数据集再进一步调整标签,最后再拿去训练,这样就能保证自己训练模型的数据够多,提升识别准确率,更新迭代模型也更方便。
我为什么叫半自动化标注,因为是否全自动化就取决与前置模型识别的准确性,识别准确性高也可以全自动化,半自动化还需要人工对新生成数据集进行核验,不过这种方式也能节省不少时间,废话不多说直接讲解实战过程。
二、实战过程
首先使用第一次训练好的模型,在detect.py上使用模型识别新的图片集即可,我一般喜欢把配置直接在代码里面修改,主要修改–weights、–source、–data 这三个参数值,然后运行代码时带上–save-txt即可保存识别图片的labels文件。
直接运行带参数:
detect.py --save-txt
修改为detect.py配置文件:
arse.ArgumentParser()
parser.add_argument("--weights", nargs="+", type=str, default=ROOT / "runs/train/exp2/weights/best.pt", help="model path or triton URL")
parser.add_argument("--source", type=str, default=ROOT / "/Users/stephen/Documents/dnf/mdnf/mdnf_yolov/data/1/train/images", help="file/dir/URL/glob/screen/0(webcam)")
parser.add_argument("--data", type=str, default=ROOT / "data/data.yaml", help="(optional) dataset.yaml path")
parser.add_argument("--imgsz", "--img", "--img-size", nargs="+", type=int, default=[640], help="inference size h,w")
parser.add_argument("--conf-thres", type=float, default=0.25, help="confidence threshold")
parser.add_argument("--iou-thres", type=float, default=0.45, help="NMS IoU threshold")
parser.add_argument("--max-det", type=int, default=1000, help="maximum detections per image")
parser.add_argument("--device", default="", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")
parser.add_argument("--view-img", action="store_true", help="show results")
parser.add_argument("--save-txt", action="store_true", help="save results to *.txt")
parser.add_argument("--save-csv", action="store_true", help="save results in CSV format")
parser.add_argument("--save-conf", action="store_true", help="save confidences in --save-txt labels")
parser.add_argument("--save-crop", action="store_true", help="save cropped prediction boxes")
parser.add_argument("--nosave", action="store_true", help="do not save images/videos")
parser.add_argument("--classes", nargs="+", type=int, help="filter by class: --classes 0, or --classes 0 2 3")
parser.add_argument("--agnostic-nms", action="store_true", help="class-agnostic NMS")
parser.add_argument("--augment", action="store_true", help="augmented inference")
parser.add_argument("--visualize", action="store_true", help="visualize features")
parser.add_argument("--update", action="store_true", help="update all models")
parser.add_argument("--project", default=ROOT / "runs/detect", help="save results to project/name")
parser.add_argument("--name", default="exp", help="save results to project/name")
parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment")
parser.add_argument("--line-thickness", default=3, type=int, help="bounding box thickness (pixels)")
parser.add_argument("--hide-labels", default=False, action="store_true", help="hide labels")
parser.add_argument("--hide-conf", default=False, action="store_true", help="hide confidences")
parser.add_argument("--half", action="store_true", help="use FP16 half-precision inference")
parser.add_argument("--dnn", action="store_true", help="use OpenCV DNN for ONNX inference")
parser.add_argument("--vid-stride", type=int, default=1, help="video frame-rate stride")
opt = parser.parse_args()
运行效果如下:
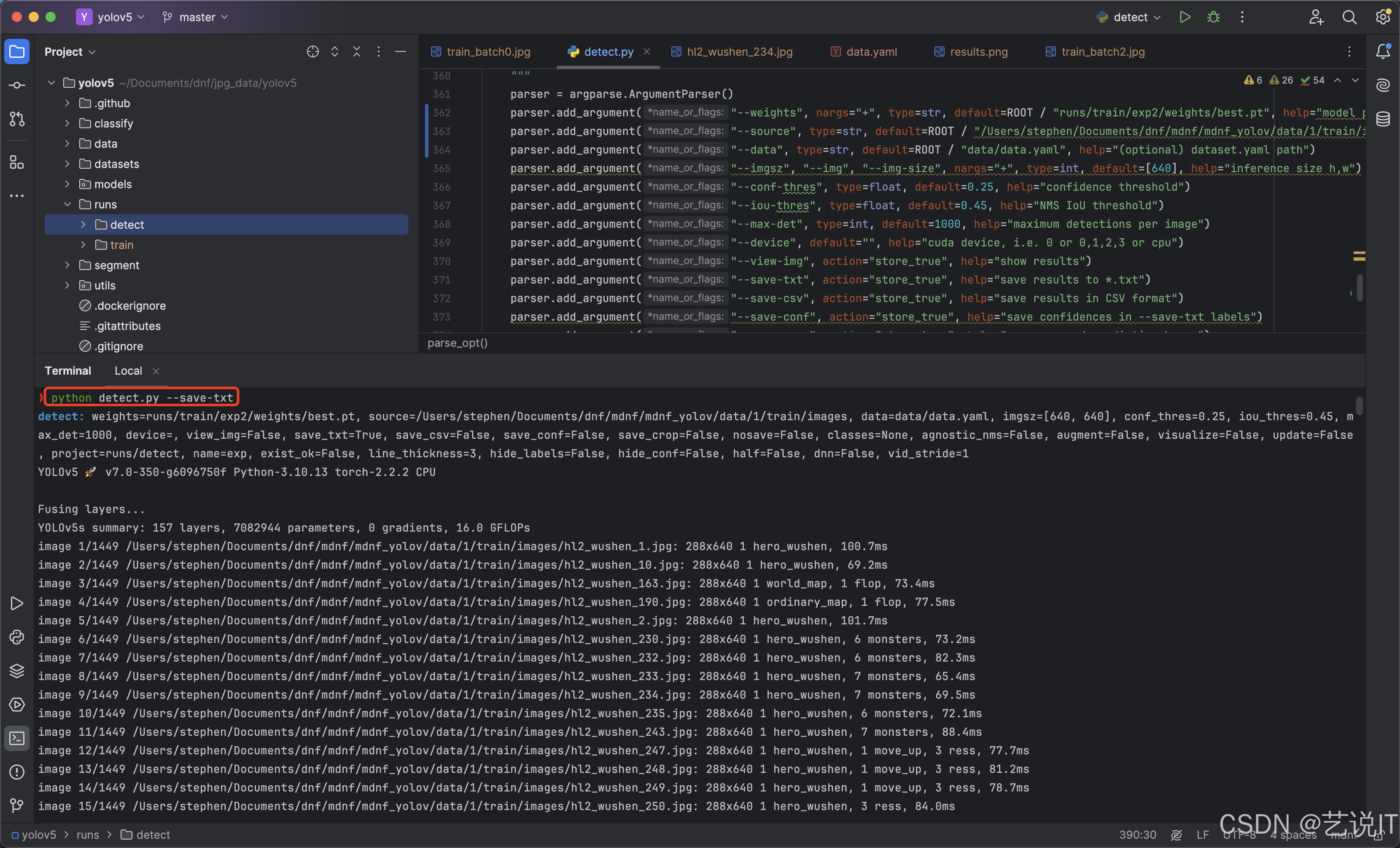
当识别跑完,就可以看到detect目录下生成有对应图片名称的labels。
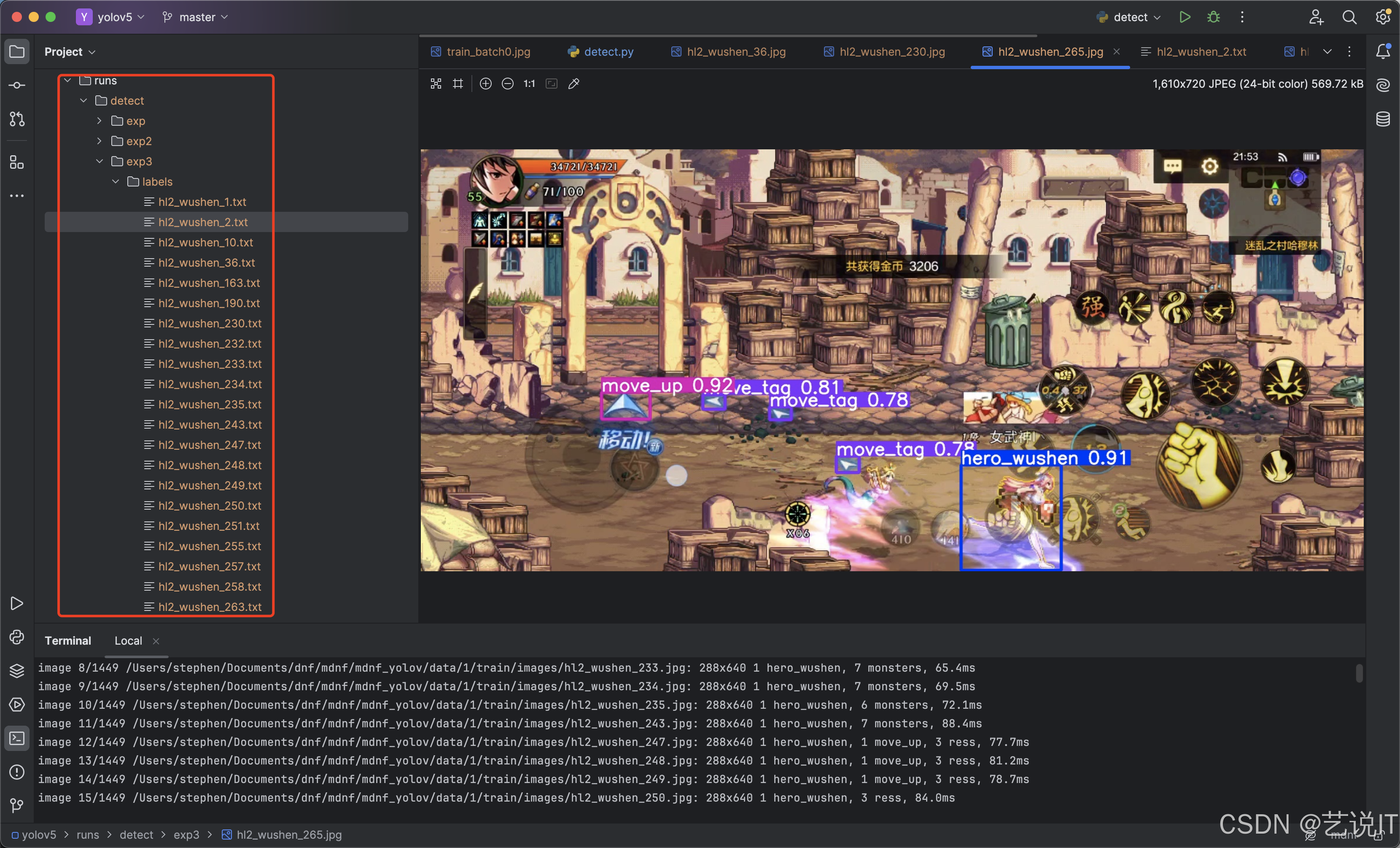
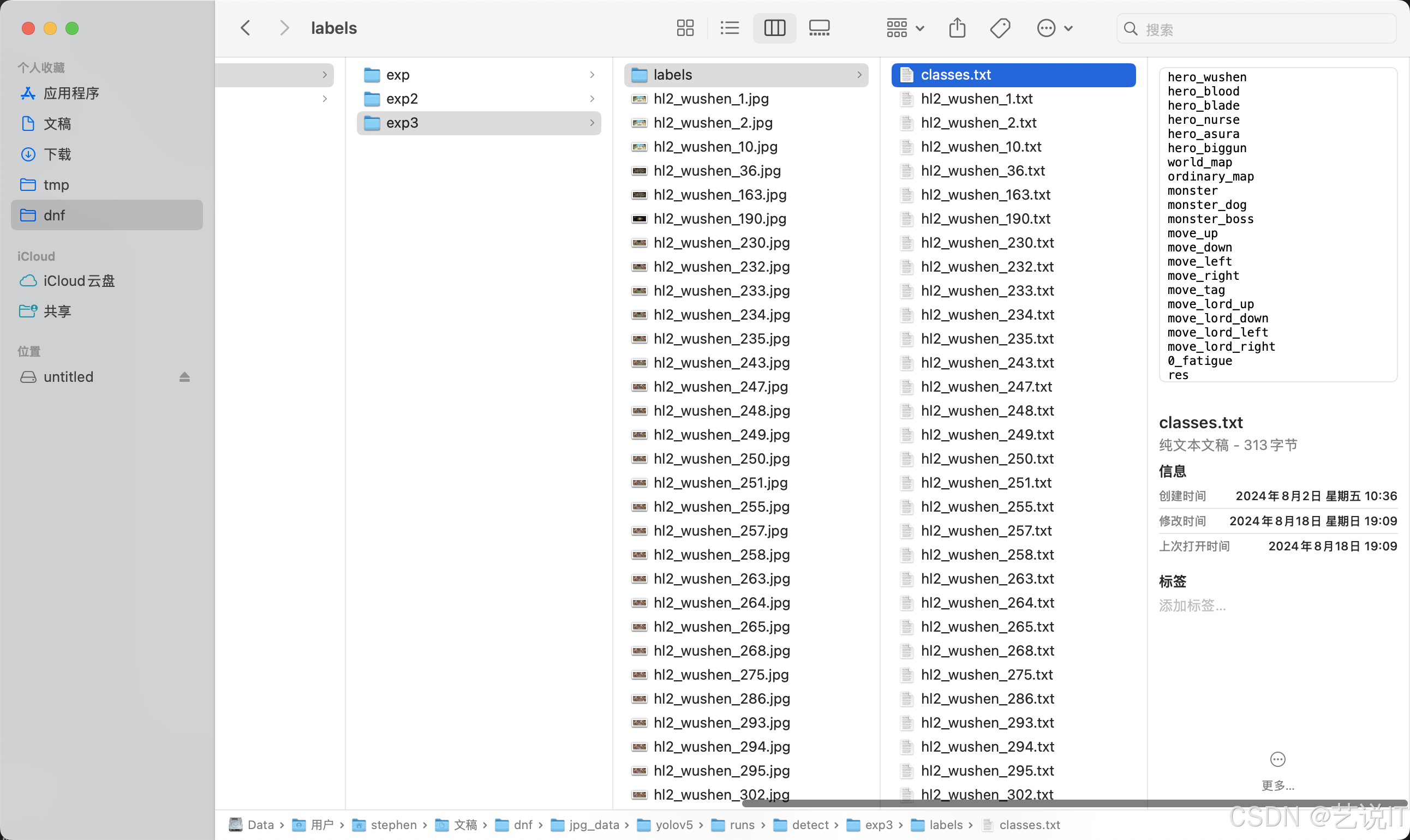
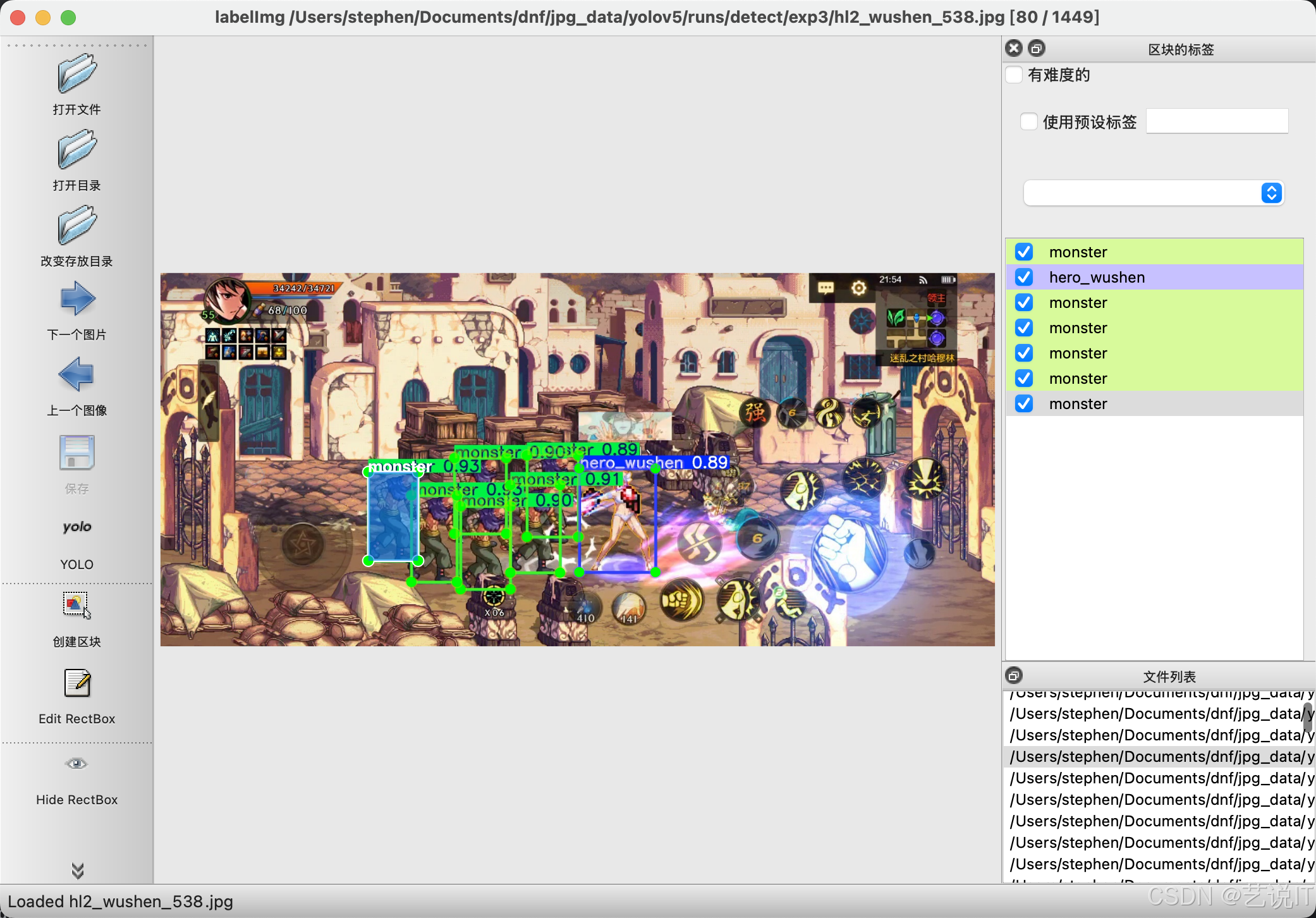
在把classes文件放入到labels中,就可以使用labelimg打开文件夹进行核验标注是否准确,进行微调即可。
三、总结
半自动化标注的方式能给你节省不少时间,增加了数据集后期的模型识别能力也就增强,换一种思路解决重复枯燥的问题。微信公众号搜索关注艺说IT,分享各种原创技术干货文章,对你有用的话请一键三连,感谢🙏。



















 123
123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









