









文章目录
一、前言
这里简单介绍一下yolov是什么东西,yolov 是高效的单阶段目标检测算法系列,经多版本迭代优化,可快速精准识别图像或视频中目标的类别与位置,广泛用于安防监控、自动驾驶、工业质检、智能零售等领域。那这里为什么选择yolov5,yolov5在性能和准确性之间取得了很好的平衡,yolov5用于学习计算机图像识别还是很好上手的。接下来介绍yolov5搭建、训练模型、使用模型的操作,后续文章将使用训练好的模型进行游戏的自动化实战,以及GPU云服务器训练yolov5模型的教程,请持续关注。废话不多说,开始操作教程。
二、环境搭建
获取yolov5项目代码
git clone https://github.com/ultralytics/yolov5.git
安装项目依赖
pip install -r requirements.txt
三、训练模型
3.1 yolov5 目录文件讲解
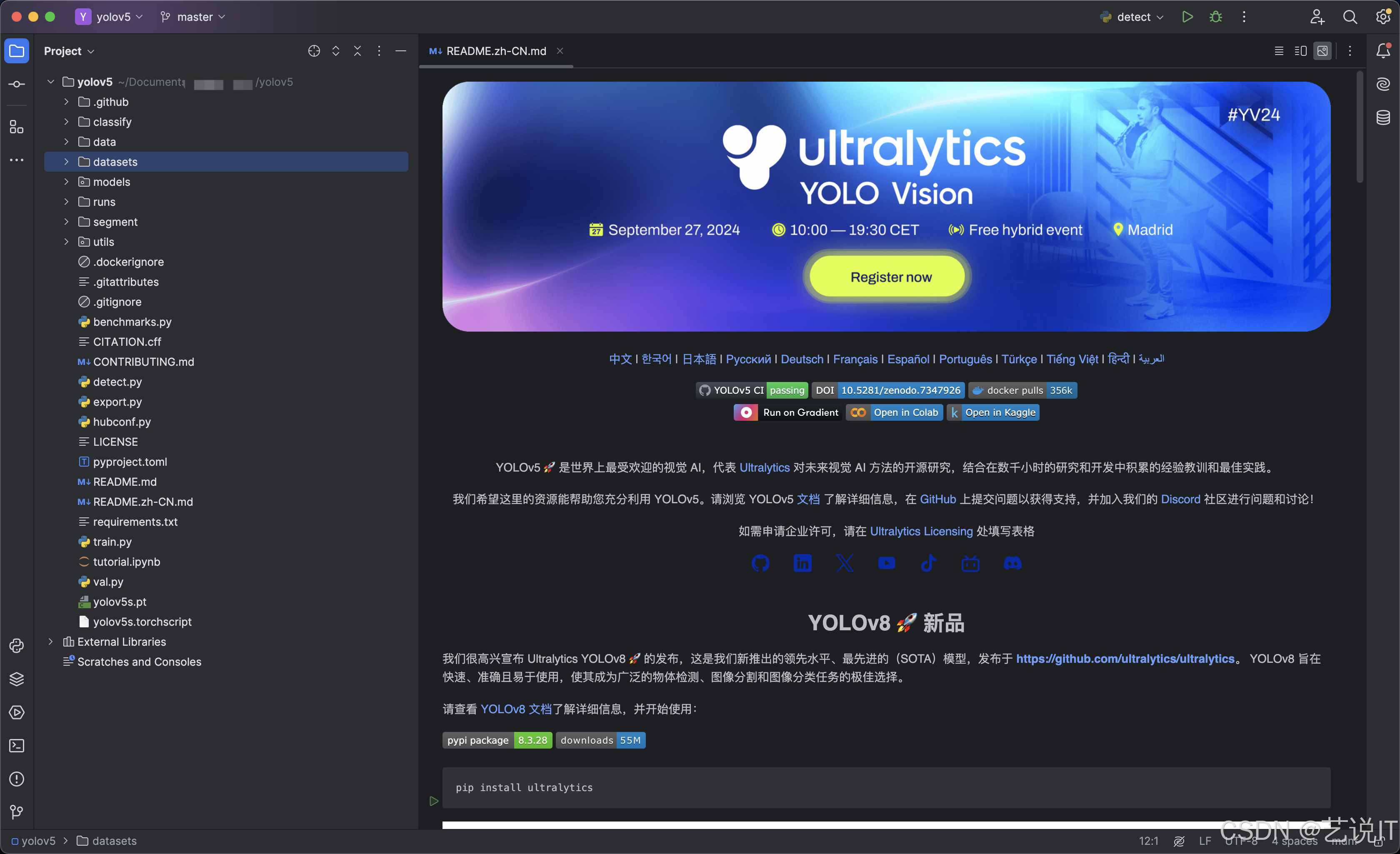
# 重点使用到这些文件与目录,其余兴趣可以自行研究
data --- 训练数据集配置文件
models --- 模型文件
datasets --- 训练的数据集文件(该目录自己创建)
train.py --- 训练生成自己的模型
detect.py --- 使用模型进行测试
export.py --- 将训练好的模型转换为ONNX格式
3.2 模型训练
3.2.1 放入自己要训练的数据集
不明白怎么创建数据集看➡️labelimg图片标注工具详解⬅️这一篇文章。使用 labelimg进行图片标注后,会自动生成yolov格式的标注文件,再网上搜索数据集自动分割训练集和验证集脚本,跑一下数据集的文件就可以拿去用了。
脚本也是网上找的,出处忘了,感谢作者的无私奉献。
import os
import random
from shutil import copy2
#如需更改训练集、验证集和测试集比例在此修改
def data_set_split(src_images_folder, src_labels_folder, target_data_folder, train_scale=0.9, val_scale=0.1, test_scale=0.1):
'''
读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行
:param src_images_folder: 总图片目录
:param src_labels_folder: 总标签目录
:param target_data_folder: 存放划分数据集文件夹
:param train_scale: 训练集比例
:param val_scale: 验证集比例
:param test_scale: 测试集比例
:return:
'''
print("开始数据集划分")
# 在目标目录下创建文件夹
split_names = ['train', 'val', 'test']
for split_name in split_names:
split_path = os.path.join(target_data_folder, split_name)
split_images_path = os.path.join(split_path, 'images')
split_labels_path = os.path.join(split_path, 'labels')
if os.path.isdir(split_path):
pass
else:
os.mkdir(split_path)
if os.path.isdir(split_images_path):
pass
else:
os.mkdir(split_images_path)
if os.path.isdir(split_labels_path):
pass
else:
os.mkdir(split_labels_path)
# 按照比例划分数据集,并进行数据图片的复制
# 首先进行分类遍历
current_all_images = os.listdir(src_images_folder)
current_images_length = len(current_all_images)
current_images_index_list = list(range(current_images_length))
random.shuffle(current_images_index_list)
#存放train、val、test中image和labels的路径
train_images_folder = os.path.join(target_data_folder, 'train/images')
val_images_folder = os.path.join(target_data_folder, 'val/images')
test_images_folder = os.path.join(target_data_folder, 'test/images')
train_labels_folder = os.path.join(target_data_folder, 'train/labels')
val_labels_folder = os.path.join(target_data_folder, 'val/labels')
test_labels_folder = os.path.join(target_data_folder, 'test/labels')
train_stop_flag = current_images_length * train_scale
val_stop_flag = current_images_length * (train_scale + val_scale)
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
for i in current_images_index_list:
src_img_path = os.path.join(src_images_folder, current_all_images[i])
# 如果图片格式不是jpg,更换则可
src_labels_path = os.path.join(src_labels_folder, current_all_images[i].replace('jpg','txt'))
if current_idx <= train_stop_flag:
copy2(src_img_path, train_images_folder)
if os.path.isdir(split_path):# 防止有些图片没有label
try:
copy2(src_labels_path, train_labels_folder)
except Exception as e:
print("手动",e)
continue
else:
print("缺少图片{}的label".format(current_all_images[i]))
train_num = train_num + 1
elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag):
copy2(src_img_path, val_images_folder)
if os.path.isdir(split_path):
copy2(src_labels_path, val_labels_folder)
else:
print("缺少图片{}的label".format(current_all_images[i]))
val_num = val_num + 1
else:
copy2(src_img_path, test_images_folder)
if os.path.isdir(split_path):
copy2(src_labels_path, test_labels_folder)
else:
print("缺少图片{}的label".format(current_all_images[i]))
test_num = test_num + 1
current_idx = current_idx + 1
print("按照{}:{}:{}的比例划分完成,一共{}张图片".format( train_scale, val_scale, test_scale, current_images_length))
print("训练集{}:{}张".format(train_images_folder, train_num))
print("验证集{}:{}张".format(val_images_folder, val_num))
print("测试集{}:{}张".format(test_images_folder, test_num))
if __name__ == '__main__':
src_images_folder = "/Users/xxx/Documents/dnf/jpg_data/yolov5/datasets/images" # 图片地址
src_labels_folder = "/Users/xxx/Documents/dnf/jpg_data/yolov5/datasets/labels" # 标签地址
target_data_folder = "/Users/xx/Documents/dnf/jpg_data/yolov5/datasets" #
data_set_split(src_images_folder,src_labels_folder, target_data_folder)
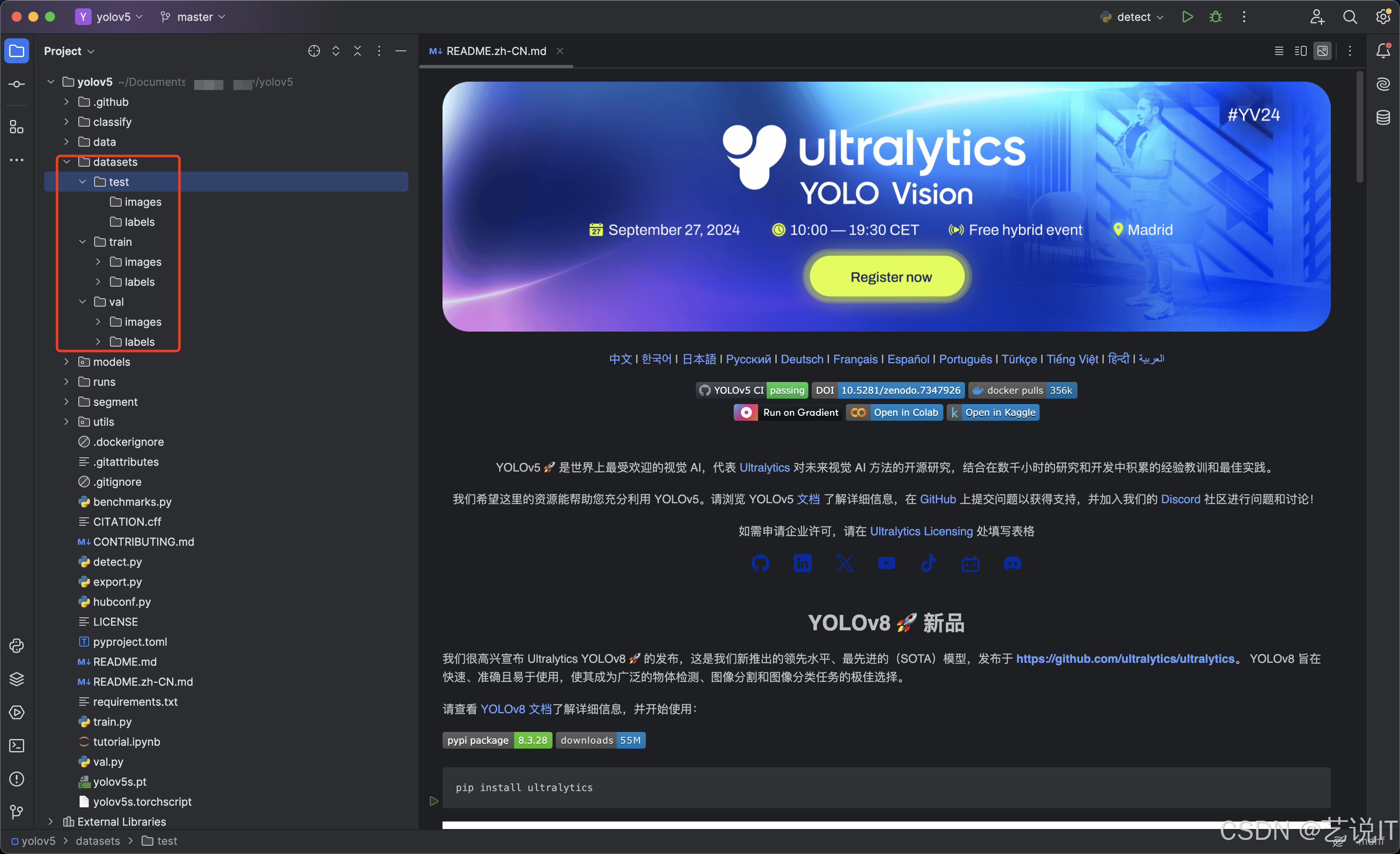
分割好训练集、验证集和测试集就可以放到datasets目录下,放到其他目录下也是可以的,问题不大,主要用于训练数据集配置文件的路径引用。
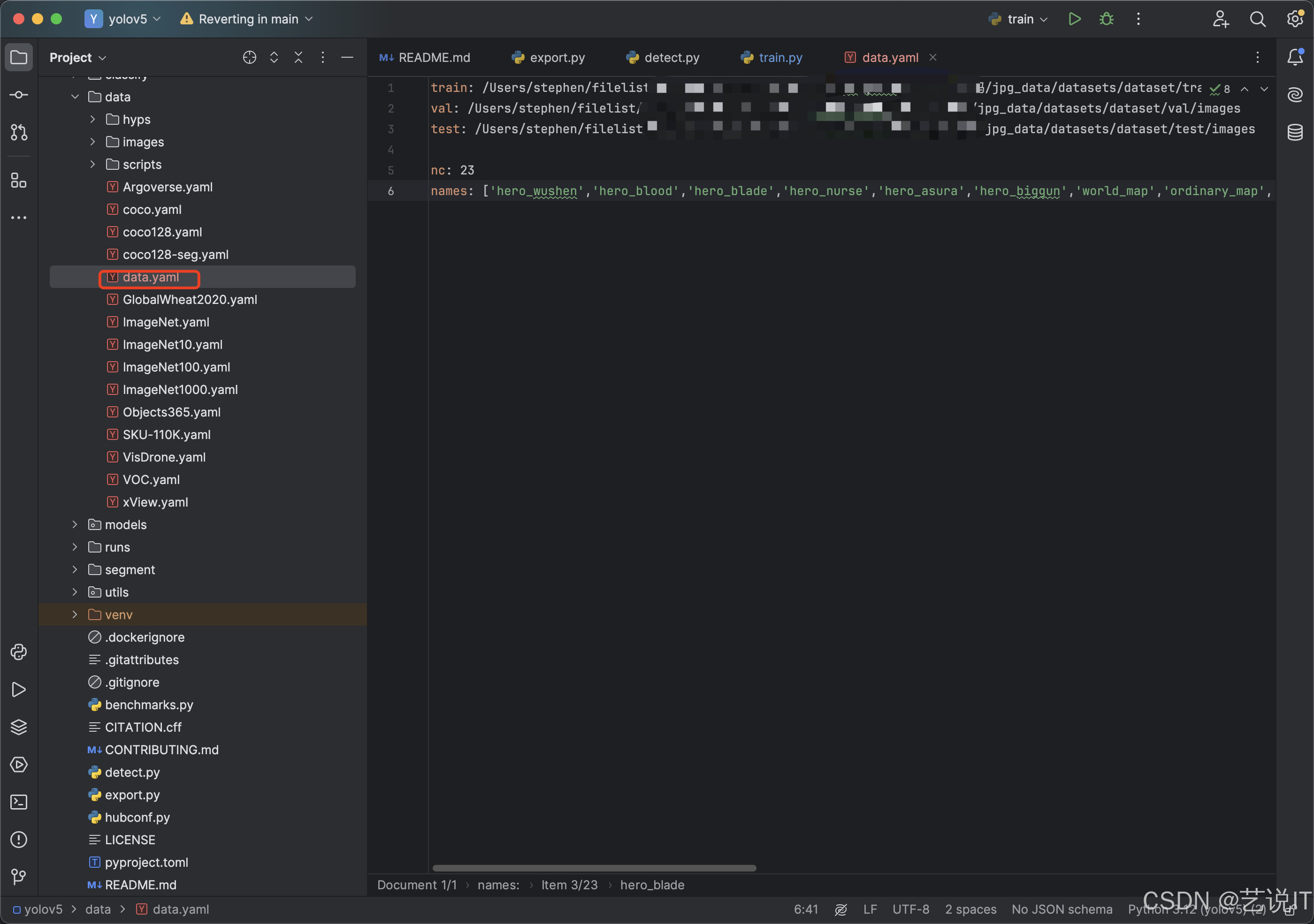
3.2.2 修改训练配置文件
YOLOv5使用train, val, test三个文件夹来存储训练、验证和测试数据集。
训练数据集 (train):包含用于训练模型的图像。
验证数据集 (val):包含用于在训练过程中验证模型性能的图像。
测试数据集 (test):包含用于最终测试模型性能的图像。
nc: 标注有多少种类就填多少。
names: 标注的类别名称有哪些都放入到names list里
3.2.3 运行训练模型脚本
方法1:
执行train.py 指定参数,
train.py --cfg models/yolov5n.yaml --data models/data.yaml --device cpu
参数解析:
--cfg 模型推理解析的配置文件,配置文件对应不同规模的 YOLOv5 模型,通常以 n(nano)、s(small)、m(medium)、l(large)、x(extra - large) 命名,规模依次增大。要了解具体区别可网上搜索查看。
--data 训练数据集的配置文件
--device 使用cpu还是gpu,作者电脑没有独显卡,所以用cpu训练
方法2:
修改train.py parser.add_argument里的default默认参数,然后运行(我这里就只改了,–cfg、–data、–device),个人比较喜欢使用方法2。
parser = argparse.ArgumentParser()
parser.add_argument("--weights", type=str, default="yolov5n.pt",
help="initial weights path")
parser.add_argument("--cfg", type=str, default="models/yolov5n.yaml",
help="model.yaml path")
parser.add_argument("--data", type=str, default="models/data.yaml",
help="dataset.yaml path")
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path")
parser.add_argument("--epochs", type=int, default=1000, help="total training epochs")
parser.add_argument("--batch-size", type=int, default=16, help="total batch size for all GPUs, -1 for autobatch")
parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=640, help="train, val image size (pixels)")
parser.add_argument("--rect", action="store_true", help="rectangular training")
parser.add_argument("--resume", nargs="?", const=True, default=False, help="resume most recent training")
parser.add_argument("--nosave", action="store_true", help="only save final checkpoint")
parser.add_argument("--noval", action="store_true", help="only validate final epoch")
parser.add_argument("--noautoanchor", action="store_true", help="disable AutoAnchor")
parser.add_argument("--noplots", action="store_true", help="save no plot files")
parser.add_argument("--evolve", type=int, nargs="?", const=300, help="evolve hyperparameters for x generations")
parser.add_argument(
"--evolve_population", type=str, default=ROOT / "data/hyps", help="location for loading population"
)
parser.add_argument("--resume_evolve", type=str, default=None, help="resume evolve from last generation")
parser.add_argument("--bucket", type=str, default="", help="gsutil bucket")
parser.add_argument("--cache", type=str, nargs="?", const="ram", help="image --cache ram/disk")
parser.add_argument("--image-weights", action="store_true", help="use weighted image selection for training")
parser.add_argument("--device", default="cpu", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")
parser.add_argument("--multi-scale", action="store_true", help="vary img-size +/- 50%%")
parser.add_argument("--single-cls", action="store_true", help="train multi-class data as single-class")
parser.add_argument("--optimizer", type=str, choices=["SGD", "Adam", "AdamW"], default="SGD", help="optimizer")
parser.add_argument("--sync-bn", action="store_true", help="use SyncBatchNorm, only available in DDP mode")
parser.add_argument("--workers", type=int, default=8, help="max dataloader workers (per RANK in DDP mode)")
parser.add_argument("--project", default=ROOT / "runs/train", help="save to project/name")
parser.add_argument("--name", default="exp", help="save to project/name")
parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment")
parser.add_argument("--quad", action="store_true", help="quad dataloader")
parser.add_argument("--cos-lr", action="store_true", help="cosine LR scheduler")
parser.add_argument("--label-smoothing", type=float, default=0.0, help="Label smoothing epsilon")
parser.add_argument("--patience", type=int, default=0, help="EarlyStopping patience (epochs without improvement)")
parser.add_argument("--freeze", nargs="+", type=int, default=[0], help="Freeze layers: backbone=10, first3=0 1 2")
parser.add_argument("--save-period", type=int, default=-1, help="Save checkpoint every x epochs (disabled if < 1)")
parser.add_argument("--seed", type=int, default=0, help="Global training seed")
parser.add_argument("--local_rank", type=int, default=-1, help="Automatic DDP Multi-GPU argument, do not modify")
# Logger arguments
parser.add_argument("--entity", default=None, help="Entity")
parser.add_argument("--upload_dataset", nargs="?", const=True, default=False, help='Upload data, "val" option')
parser.add_argument("--bbox_interval", type=int, default=-1, help="Set bounding-box image logging interval")
parser.add_argument("--artifact_alias", type=str, default="latest", help="Version of dataset artifact to use")
# NDJSON logging
parser.add_argument("--ndjson-console", action="store_true", help="Log ndjson to console")
parser.add_argument("--ndjson-file", action="store_true", help="Log ndjson to file")
开始模型训练,本地机器配置低的机器训练百来张图片还是很吃力的,我的是macbbok2018 i9款,本地训练1000多张图片,跑一个晚上,这里只是做操作演示,真正要训练还是要有GPU服务器才行,后续会有文章介绍云GPU使用教程。
训练完成再runs -> train -> exp 目录下就可以看到bast.pt文件,这就是已经训练好的模型文件
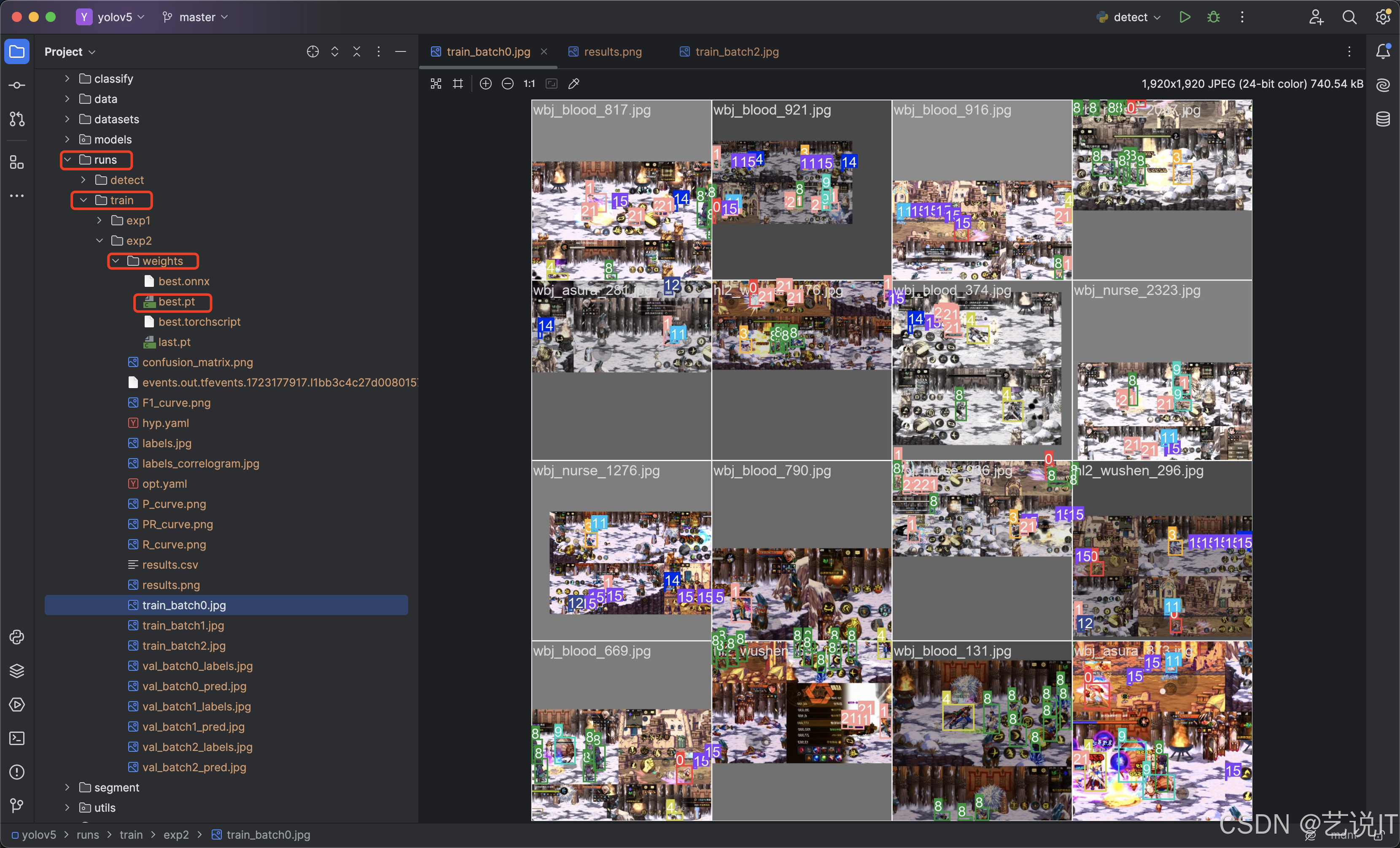
四、使用模型
可以用torch加载本地模型实现实时检测识别,也可以使用自带detect.py对图片与文件进行识别。
detect.py
--weights 模型文件路径
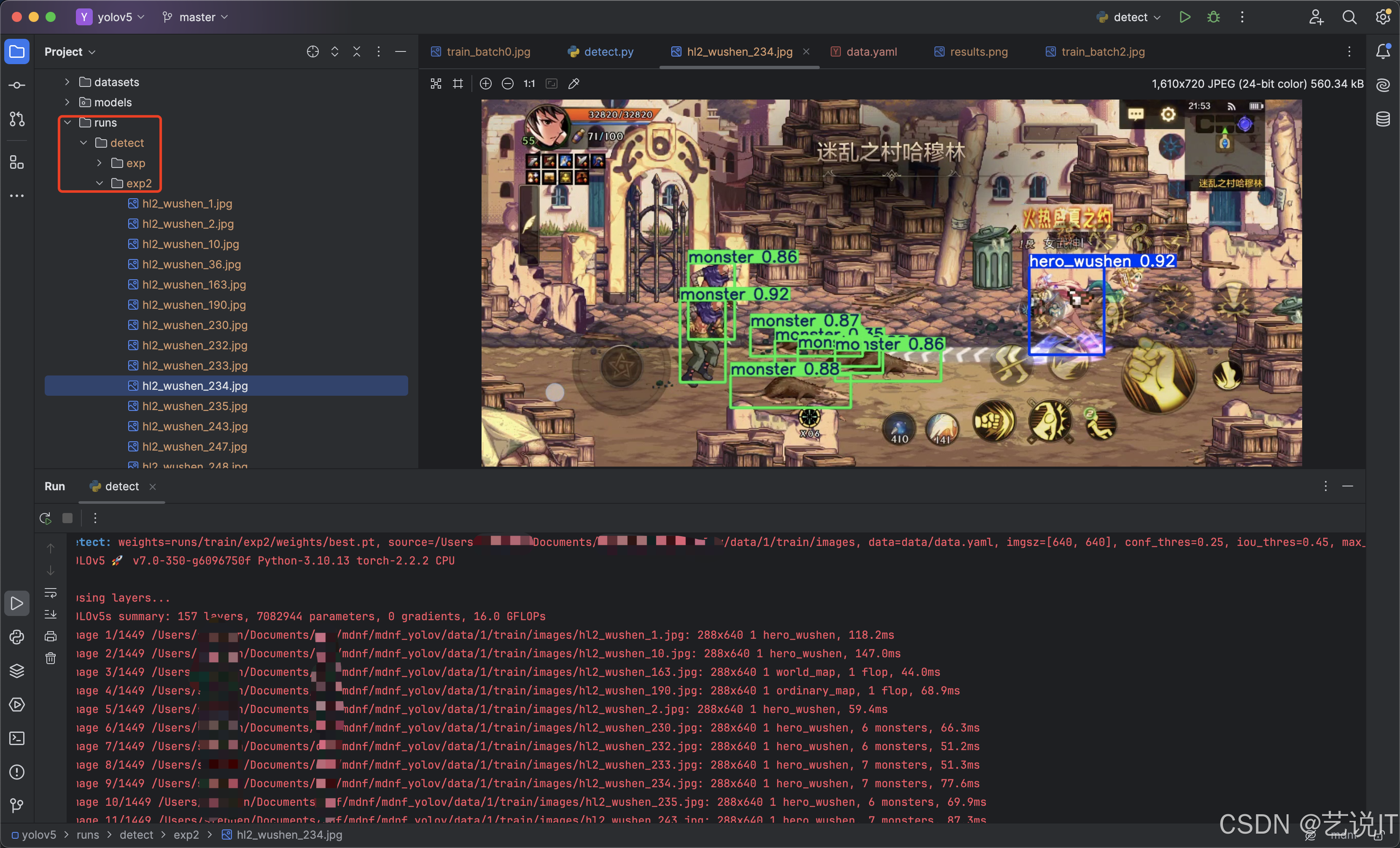
运行完之后,就能在runs —> detect 运行模型识别图片的结果。
五、总结
文章大致演示了yolov5的基础使用,感兴趣的同学多实践才方便理解,后续文章将使用训练好的模型进行游戏的自动化实战,以及GPU云服务器训练yolov5模型的教程,请持续关注。微信公众号搜索关注艺说IT,分享各种原创技术干货文章,对你有用的话请一键三连,感谢🙏。



















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









