






K最近邻算法的原理正如标题所说——近朱者赤近墨者黑,我们数据集一半是朱(下图浅色点),一般是墨(下图深色点)。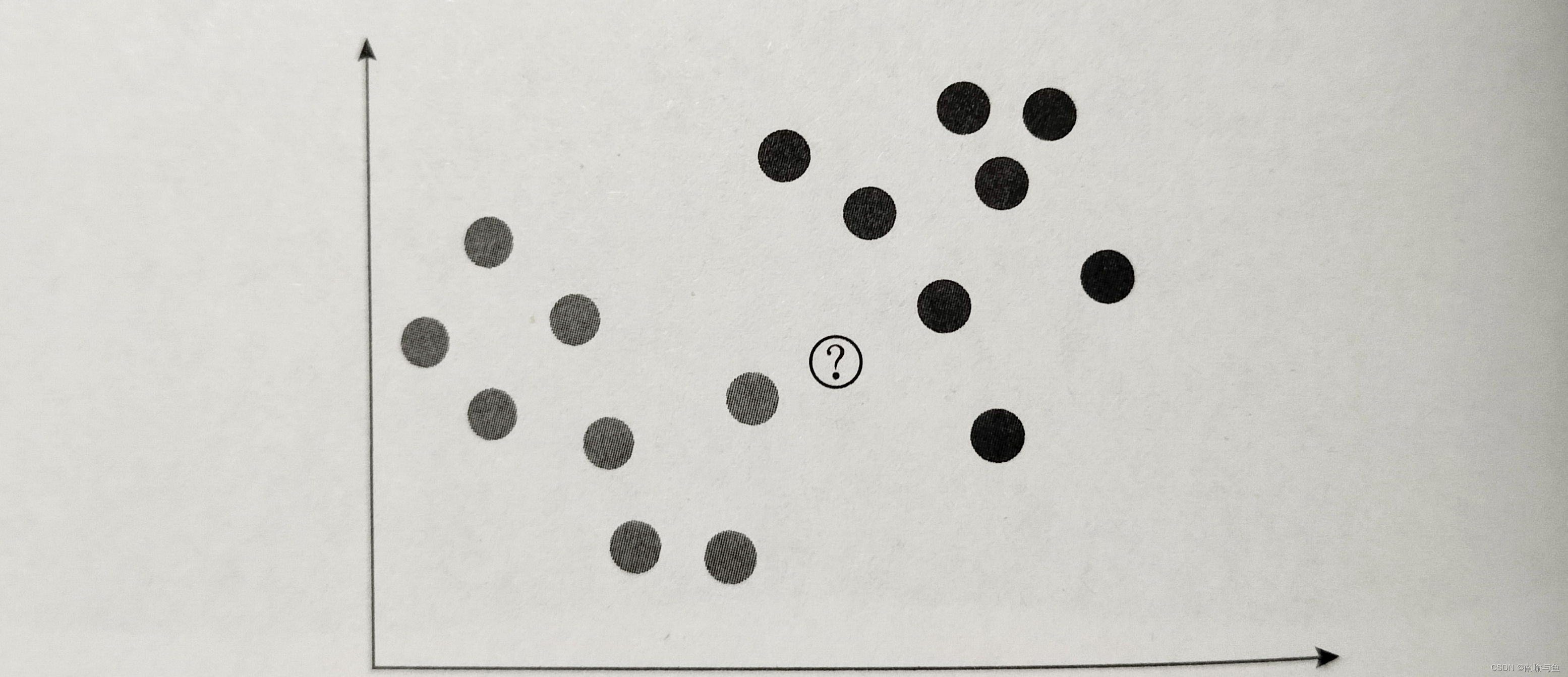
现在有个一个新的数据点,我们如何判断它属于那一类呢?对于K最邻近算法来说,新数据点离谁近,就和谁属于同一类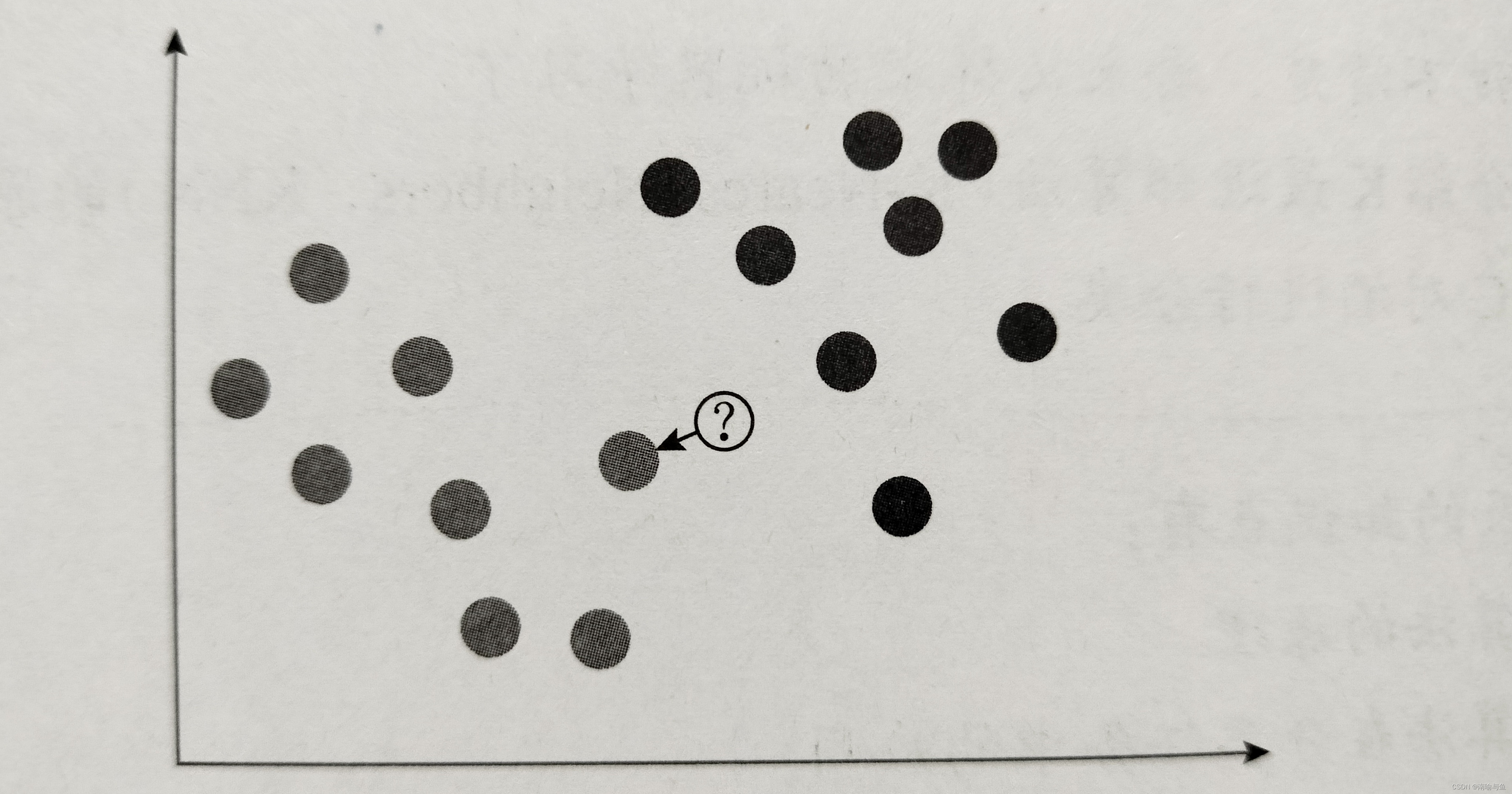
如上图所示,我们选的最邻近数为1,但是我们如果在训练模型过程中让最近邻数等于1的话,那么就很可能犯一叶障目不见泰山的错误,万一新数据点最近的数据恰好是个测试错误点呢?所以我们要增加最近邻的数量,例如把最近邻数增加到3,然后让新数据点的分类和3个当中最多的数据点所处的分类一致,如下图所示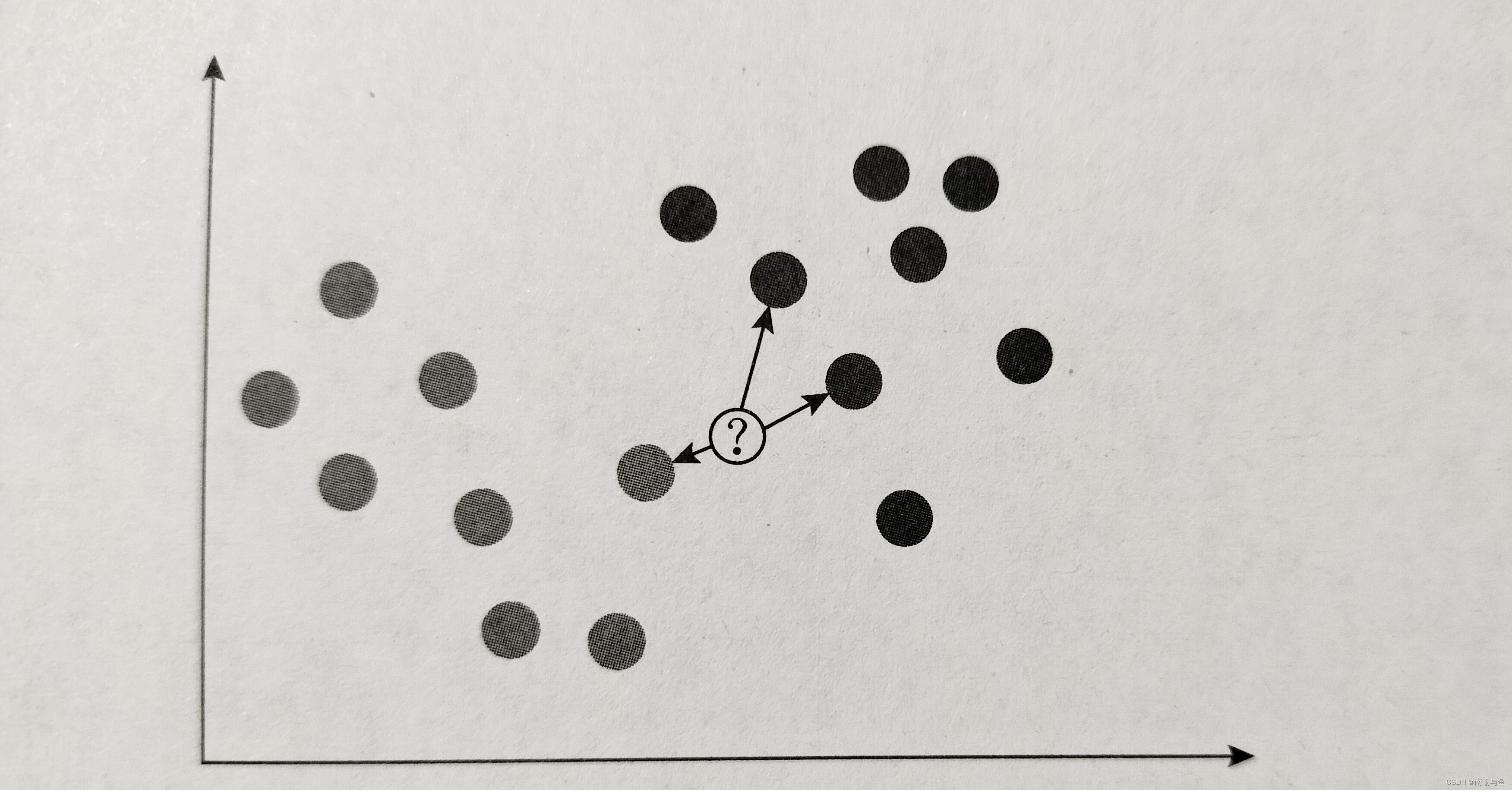
当我们令新数据点的最近邻数为3时,在于新数据点最近的三个点中,有两个是深色,一个是浅色,这样一来,K最近邻算法把新数据点放到深色的分类中。
在scikit-learn中,内置了若干玩具数据集(Toy Datasets),还有一些API让我们展示。
在这段代码中,我们用scikit-learn的make_blobs函数生成一个样本数量为200,分类为2的数据集,并将其复制给x,y,然后我们用matplotlib讲数据用图形表示出来,如下图所示
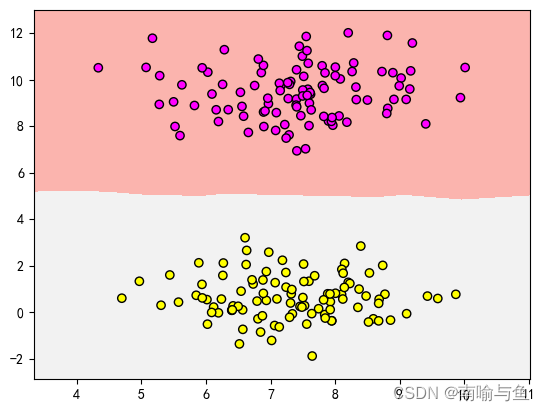
make_blods生成的数据集一共有两类,其中一类用深色表示,另一类用浅色表示。我们这里生成的数据集,可以看作为机器学习的训练数据集,是已知数据,我们基于这些数据用算法进行模型训练,然后再对未知数据进行分类和回归。下面我们用K最近邻算法来拟合这些数据,输入代码如下
运行结果为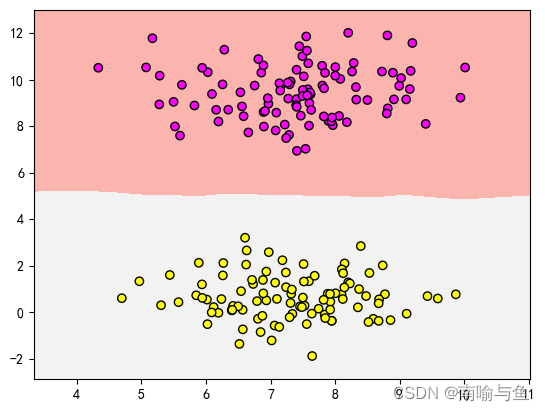
从中我们可以看出,K最近邻算法基于数据集创建了一个分类模型,就是图中粉色区域和灰色区域组成部分,如果有新数据输入的话,模型就会自动讲新数据分到对应分类中。
假设有一个新数据点,它的两个特征值分别是6.75和4.82,我们来测试一下模型能不能讲它放到正确的分类中,输入一下代码

得到图形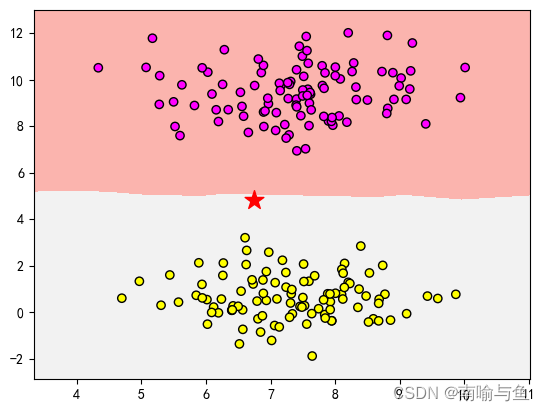
图中五角星就代表了新数据点所在位置,可以看出K最近邻算法将它放在了下方区域,和浅色数据归为一类。我们再验证一下,输入代码

可以看出,K最近邻算法工作成果还是很不错的。
下面 我们用K最近邻算法处理多元分类任务
接下来,为让任务难度加大,我们修改make_blods的centers参数,把数据类型增加到5个,同时修改n_samlpes参数,把样本量也增加到500个,输入代码
得到结果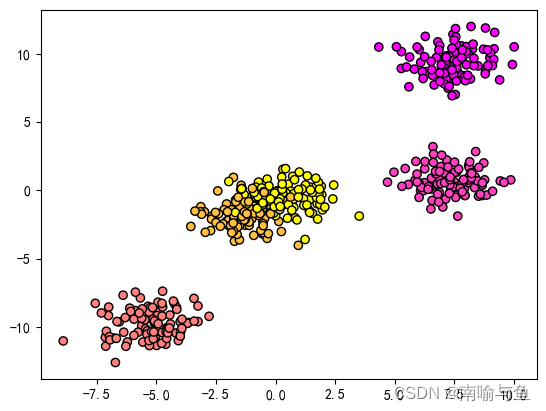
我们再次用K最近邻算法建立模型拟合这些数据
得到结果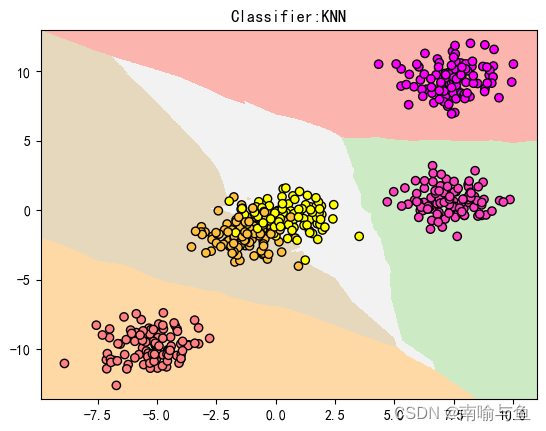
从中可以看出,K最近邻算法仍然把大部分数据点置于正确分类,小部分进入了错误分类,这些错误分类的数据点基本都是相互重合的位于图像中心位置的点。为了查看模型正确率 我们运行一下代码
可以看出,这个结果是相当不错的。
明天 我会接着使用K最近邻算法来进行回归分析















 1220
1220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









