






数据挖掘是指从大量数据中发现潜在的有价值的只是的过程,机器学习是一种利用数据训练模型的算法。可以理解为机器学习是数据挖掘的方法之一。
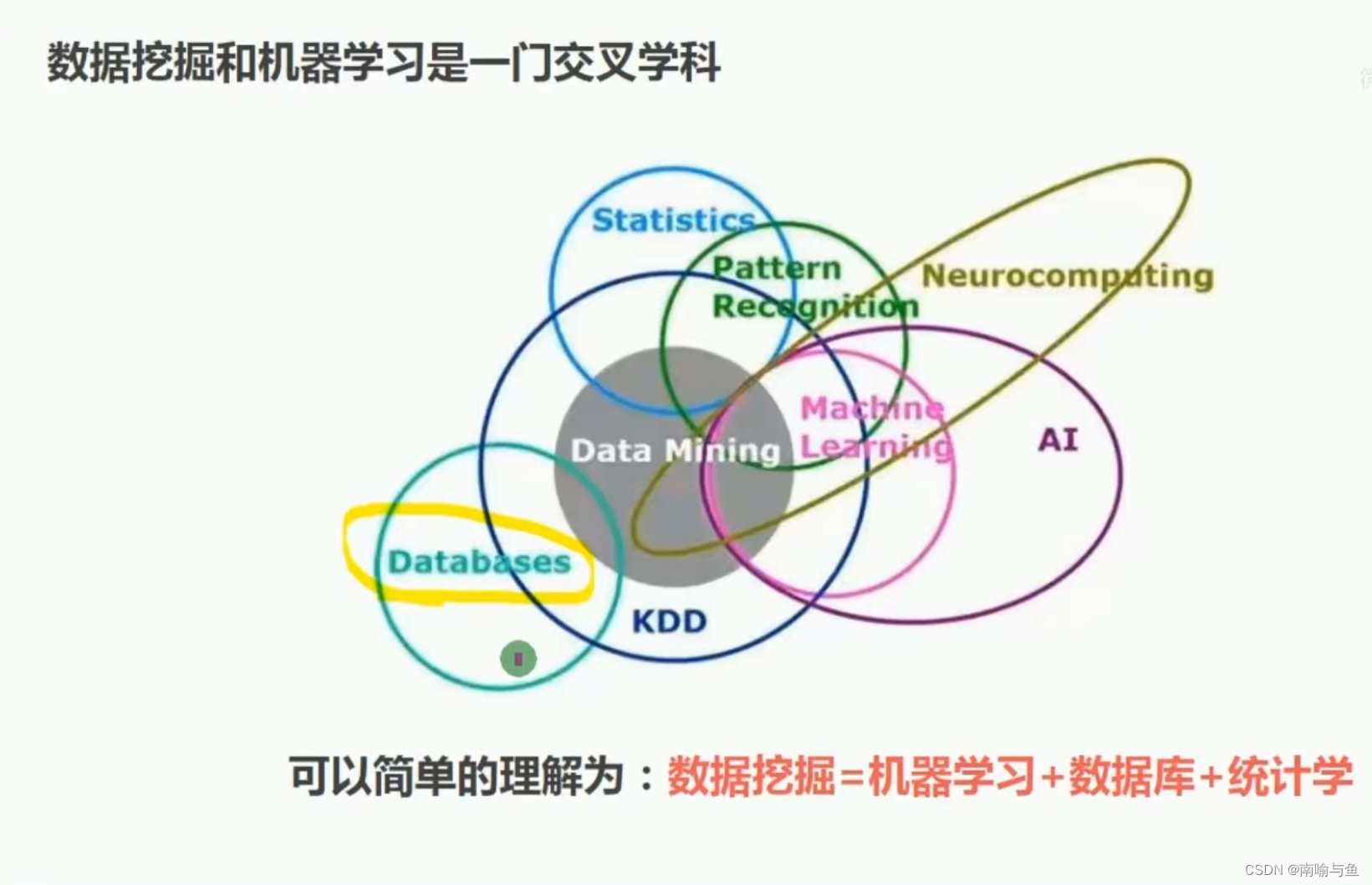
数据挖掘有一下六大任务,分别是:分类问题、聚类问题、回归问题、关联问题、序列问题、异常值检测问题。
分类问题是指从训练样本中学习,构建一个函数(分类器),对样本的所属类别进行判别。典型的分类问题有垃圾邮件识别、文本分类、信用评分、欺诈检测、图像识别、用户流失预测、营销响应预测、广告点击率预估、商品推荐等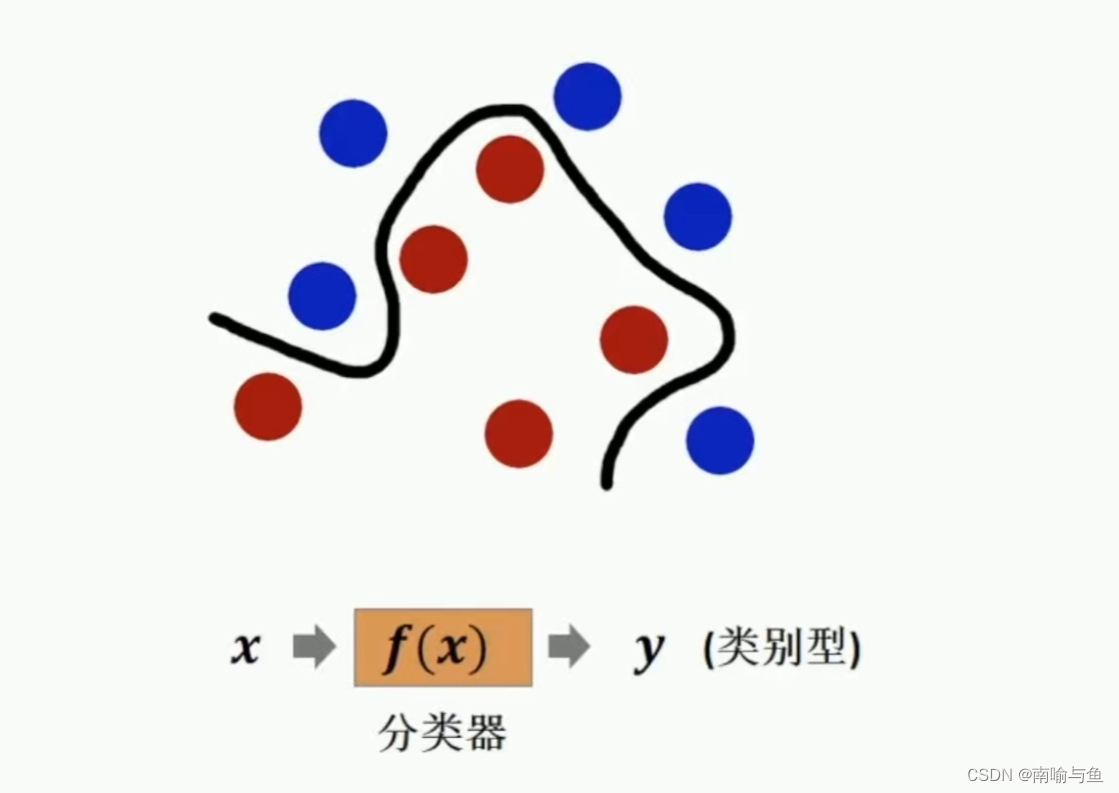
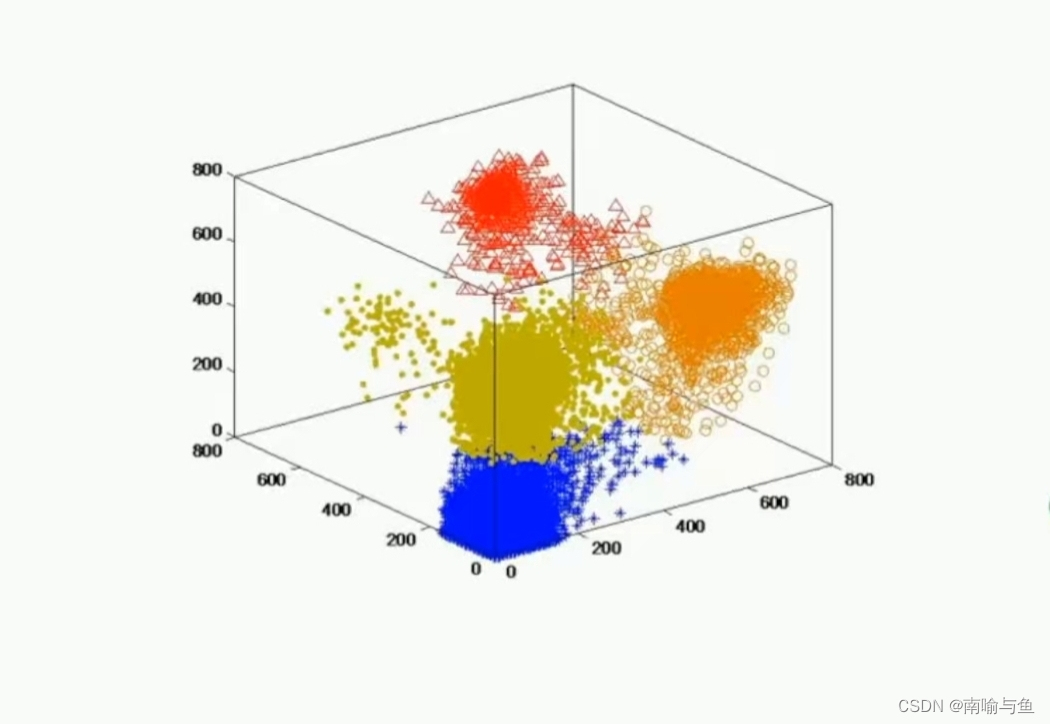
聚类问题是指从数据中探索样本之间的相似性,把特征相似的具为一类,是一种无目标的探索性分析。典型聚类问题包括用户分群,想死文档聚类等。
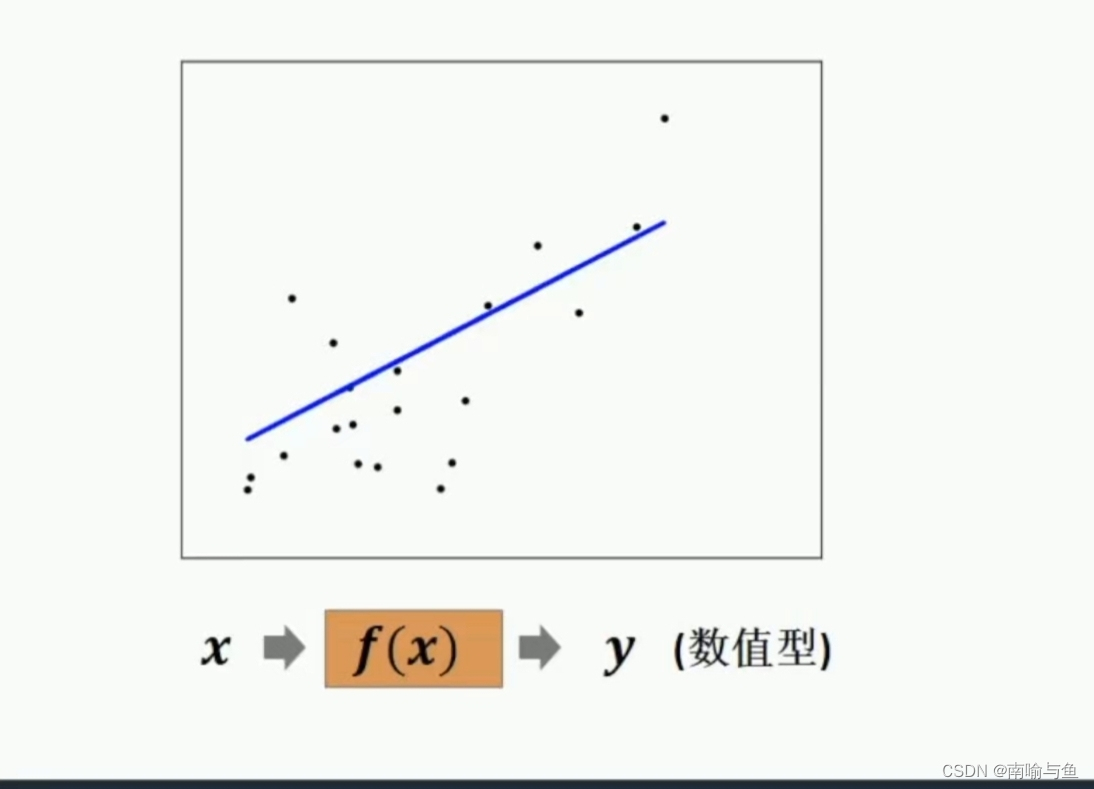
回归问题指从训练样本中学习,构建一个函数,对样本目标变量进行估值。典型回归问题有:房价预测,收入预测等。
关联问题是指从交易型数据中发现频繁关联出现的商品,又称购物篮分析。例如
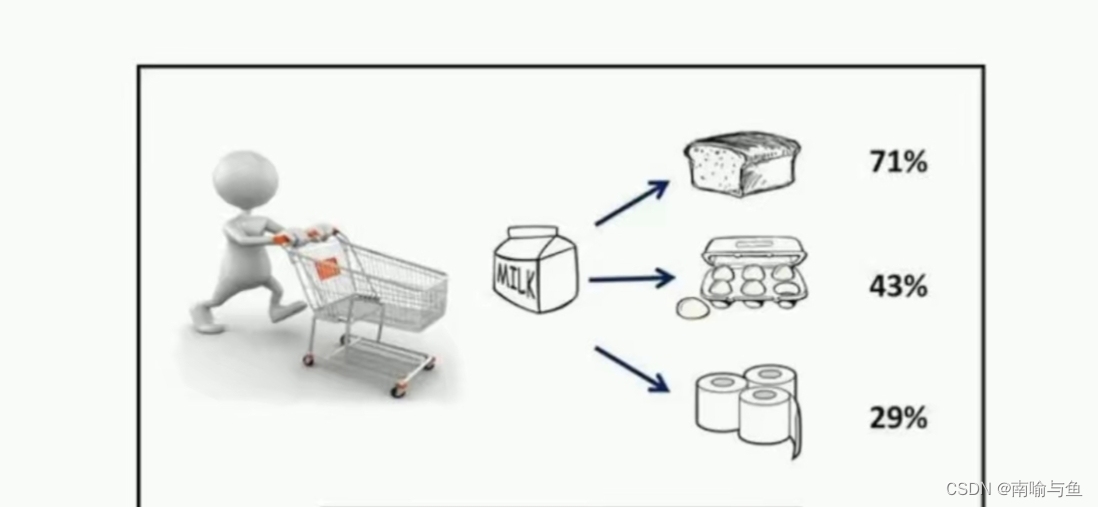
买牛奶的顾客往往同时会买面包和鸡蛋。典型的关联问题有商品买了还买,电影看了还看和商品推荐等。
序列问题是指从顺序型数据中发现序列模式,例图九个月前买了pc的用户往往下一个月会买一根内存条。典型序列问题包括购物模式预测、网站点击模式预测、中文分词、DNA序列分析。
异常值检测问题是指检测样本取值是否显著偏离常规,发现有意义的孤立点和异常值。
典型异常值检测问题包括信用卡行为检测、网络安全检测、不合格产品检测。


















 2025
2025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









