






最近在利用python进行实践训练,但是跟着参考书学习到SVM的时候,示例代码里突然出现了一个函数——decision_function(),让我很懵逼,帮助文档里的英文翻译过来说啥决策函数、ovr、ovo之类的,让我整个人更晕了,因为我在理论部分参考的是周志华老师的《西瓜书》,而《西瓜书》中并没有对这些进行说明。然后,我去查阅了一些资料,梳理了一下,并结合个人理解在此写下一些个人的思考,如果有误请见谅,欢迎一起探讨。当然,如果这篇文章还能入得了各位“看官”的法眼,麻烦点赞、关注、收藏,支持一下!
注意:并不是所有的分类算法都有decision_function()方法
本文中SVM的核函数均为线性核函数,即对大家最常见、最普通的SVM分类器进行讨论
一、决策函数是什么?
顾名思义它就是一个函数,一个可以帮助我们决策,或者说帮我们进行分类的函数。因为决策的本质就是先分类,然后从所分出的类中选择其一。
对于决策函数的定义我查了蛮多资料,个人感觉还是百度百科的上的解释让我更容易理解,即:对于分类问题,边界线就是一个决策函数,这同样也在说明,在SVM中超平面方程其实也可以看做一个决策函数。
比如说在学习SVM时,函数![]() ,它就是一个决策函数,我们可以将样本点带入到这个方程中进行计算,即给决策函数一个输入,如果这个方程算出的结果>0,即输出结果>0,那么这个样本点将被分到“正样本”这一类;如果输出结果<0,那么这个样本点将被分到“负样本”这一类;如果输出结果=0,那么就表示这个样本点位于分类面上,或者说位于超平面上。同时,结合下图,不难发现,样本点带入到决策函数后,输出结果的绝对值越大,则表明样本点距离分类边界线(超平面)越远,也进一步说明样本分类结果越正确,越可信。
,它就是一个决策函数,我们可以将样本点带入到这个方程中进行计算,即给决策函数一个输入,如果这个方程算出的结果>0,即输出结果>0,那么这个样本点将被分到“正样本”这一类;如果输出结果<0,那么这个样本点将被分到“负样本”这一类;如果输出结果=0,那么就表示这个样本点位于分类面上,或者说位于超平面上。同时,结合下图,不难发现,样本点带入到决策函数后,输出结果的绝对值越大,则表明样本点距离分类边界线(超平面)越远,也进一步说明样本分类结果越正确,越可信。
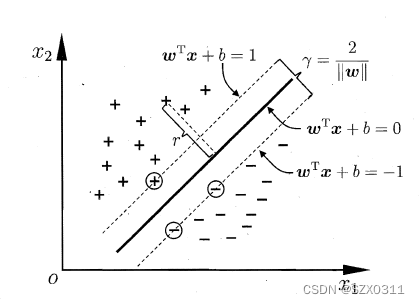
二、决策函数、ovr、ovo有啥关系?
上面我们已经聊过了,决策函数本质上就是在进行分类,既然是分类,那么就会出现两种分类情况:二分类问题、多分类问题。二分类问题很好办,直接可以根据决策函数输出结果的正负性来对样本所属类别进行判别,进而明确分类;但是,多分类问题就相对复杂。因此,需要引入一些策略帮助我们解决多分类问题,而ovr,ovo就是针对多分类问题的策略,其本质上还是先将多分类问题先转换成二分类问题,然后进行分类。
既然ovr和ovo是将多分类问题转换成二分类问题的策略,那么两个策略的具体做法是什么?下面举例说明一下:
(PS:在下面的举例中,假设样本的类别有四类,分别是a类、b类、c类、d类)
1、ovr:通过重新定义类别划分,将四分类转化成四种情况的二分类,即:分别从四类中选取一类为"正样本"类,另外三类为"负样本"类,具体来说:
情况1:正样本:a类;负样本:b类+c类+d类
情况2:正样本:b类;负样本:a类+c类+d类
情况3:正样本:c类;负样本:a类+b类+d类
情况4:正样本:d类;负样本:a类+b类+c类
由此可知,当样本的类别有n类的时候,可以将n分类转化成n种情况的二分类
2、ovo:通过重新定义类别划分,将四分类转化成六种情况的二分类问题,即:分别从四类中选取两类,然后对这两类进行二分类,具体来说:
情况1:正样本:a类;负样本:b类
情况2:正样本:a类;负样本:c类
情况3:正样本:a类;负样本:d类
情况4:正样本:b类;负样本:c类
情况5:正样本:b类;负样本:d类
情况6:正样本:c类;负样本:d类
为什么分成了六种情况不是十二种情况?因为存在重复情况,比如说{正样本:a类,负样本:b类}和{正样本:b类,负样本:a类}其分类情况都是一致的,都可以将a类和b类分开
由此可知,当样本的类别有n类的时候,可以将n分类转换成![]() 种情况的二分类
种情况的二分类
三、decision_function()函数的输入和输出
输入:样本点的特征数组
输出:需要分二分类问题和多分类问题讨论,多分类又需要分ovr和ovo两种模式讨论
1、二分类:在SVM中,进行二分类时,就是将样本点带入决策函数![]() 中计算,计算所得结果即函数decision_function()对于该样本的输出(核函数为线性核函数,下同)
中计算,计算所得结果即函数decision_function()对于该样本的输出(核函数为线性核函数,下同)
2、多分类问题:
①ovr:以上面的例子进行说明,模型会根据四种情况,生成四个的决策函数,这四个决策函数的决策系数w和截距b是不同的,将样本点X分别带入四个决策函数中进行计算,计算所得的四个结果即函数decision_function()对于样本点X的输出,根据四个值的大小,我们就可以判断样本点X属于a、b、c、d四类中的哪一类,即函数decision_function()输出的最大值对应的正样本类别就是样本点X所属的类别,比如说:函数decision_function()输出结果是[-2,-1,0,1],那么样本点X属于d类
②ovo:继续以上面的例子进行说明,模型会根据六种情况,生成六个的决策函数,这六个决策函数的决策系数w和截距b是不同的,将样本点X分别带入六个决策函数中进行计算,计算所得的六个结果即函数decision_function()对于样本点X的输出,根据六个值的符号,再结合投票法,我们就可以判断样本点X属于a、b、c、d四类中的哪一类,其中符号正负性表示,样本点X在不同分类情况下是属于正样本还是负样本,比如说:函数decision_function()输出结果是[-2,1,2,3,4,-5],“-2”表示在情况1中样本点X属于负样本:b类,那么就要为b类投一票,“1”表示在情况2中样本点X属于正样本:a类,那么就要为a类投一票,“2”表示情况3中样本点X属于正样本:a类,那么就要为a类投一票……以此类推最后的投票结果如下:
{a类:2票,b类:3票,c类:0票,d类:1票}
由此,可以判断样本点X属于b类
当然,decision_function()函数并不会对类别进行判别,只是说我们可以根据他的输出值来进行类别判别
本文图片来源:《西瓜书》
本文参考借鉴的相关文章有:
scikit-learn工具包中分类模型predict_proba、predict、decision_function用法详解_sklearn predict-CSDN博客
SVM 决策函数(Decision Function) - 一亩三分地 (mengbaoliang.cn)
当然,在搜索相关问题时,有些文章中可能会出现“函数距离”、“几何距离”等概念,有些小伙伴可能不太明白,所以下面附一个个人认为描述较好的文章链接:
















 2166
2166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









