









一、用自己的语言解释以下概念
1.局部感知、权值共享
局部感知是指:在神经网络中,每个神经元只关注输入数据的局部区域,而不是整体图像或序列。这种方式可以帮助网络更好地理解输入数据中的局部特征,从而提高模型对于复杂数据的理解能力。
权值共享是指:在神经网络的不同位置使用相同的参数来处理输入数据。这样做有助于减少模型的参数数量,并且可以更好地捕捉到输入数据中的重要模式和特征。通过权值共享,神经网络可以更有效地学习并泛化到不同的输入情况,从而提高模型的鲁棒性和泛化能力。
局部感知与权值共享_局部感受野和权值共享_Le0v1n的博客-CSDN博客这是学长的具体描述还是很详细的。
2.池化(子采样、降采样、汇聚)。会带来那些好处和坏处?
池化,也称为子采样、降采样或汇聚,是在神经网络中常用的一种技术。它的主要目的是通过对输入数据进行压缩和抽象,来减少数据的维度,降低计算复杂度,并且提取输入数据中最重要的特征。
好处:
- 减少计算量:池化可以减少后续神经网络层的计算量,加快训练速度和推理速度。
- 降低过拟合风险:通过减少特征数量,池化有助于减少模型的过拟合风险,提高模型的泛化能力。
- 保持平移不变性:池化操作在一定程度上保持了输入数据的平移不变性,使得模型对输入数据的位置变化更具鲁棒性。
- 特征提取:池化有助于提取输入数据中最显著的特征,从而有助于模型更好地理解输入数据。
坏处:
- 信息丢失:池化可能会导致一定程度上的信息丢失,因为它会丢弃输入数据中某些细节信息。
- 分辨率降低:池化会导致输入数据的分辨率降低,这可能会影响模型对于细节的识别能力。
3.全卷积网络(课上讲的这个概念不准确,同学们查资料纠正一下)
全卷积网络(Fully Convolutional Network, FCN)是一种用于图像语义分割的神经网络架构。它最初由Jonathan Long等人在2015年提出,旨在解决图像语义分割任务中的像素级分类问题。相较于传统的卷积神经网络(CNN),全卷积网络具有以下特点:
-
卷积神经网络的转化:全卷积网络将原本用于图像分类的卷积神经网络进行了改造,使其能够接受任意大小的输入,并输出与输入同样大小的密集特征图,这使得全卷积网络可以直接用于图像语义分割任务。
-
上采样与跳跃连接:为了实现输出特征图与输入图像相同大小的目标,全卷积网络使用了转置卷积(transposed convolution)或反卷积(deconvolution)等上采样操作,同时结合跳跃连接(skip connections)等结构,以获得更好的多尺度特征信息,提高语义分割的精度。
-
密集预测:全卷积网络通过对输入图像的每个像素进行分类,从而可以实现像素级的语义分割,即将图像分割成具有语义信息的不同区域。
-
多尺度特征融合:为了更好地捕获图像中的多尺度信息,全卷积网络通常会引入多尺度的特征融合机制,以提高对不同大小目标和细节的识别能力。
全卷积网络(Fully Convolutional Network, FCN)是一种专门用于处理图像语义分割任务的神经网络架构。相较于传统的卷积神经网络(CNN),全卷积网络的最大特点在于它可以接受任意大小的输入,并且输出相应尺寸的密集特征图,而不会受限于固定大小的输入图像。
全卷积网络通常采用卷积层和转置卷积层来进行特征提取和上采样操作,通过多次上采样得到与输入图像相同大小的语义分割结果。此外,全卷积网络还使用了跳跃连接(skip connections)等结构,以帮助网络更好地捕获多尺度的特征信息,提高语义分割的精度。
全卷积网络 FCN 详解 - 知乎 (zhihu.com)这个知乎将全卷积网络讲解的很详细,想要深入了解可以看看。
4.低级特征、中级特征、高级特征
低级特征:低级特征通常指的是图像中的边缘、纹理、颜色等基本信息,它们是从原始像素值中提取的简单特征。低级特征对应于图像的局部信息,能够帮助捕获图像中的细微结构和基本纹理特征,通常由卷积神经网络(CNN)中的浅层卷积层提取而来。
中级特征:中级特征是在低级特征基础上进一步组合和抽象而成的特征,包括了一些更加抽象的视觉概念,例如边界、角点、纹理块等。中级特征通常对应于图像的一些局部结构或者简单的物体部分,能够帮助识别局部目标和场景信息,通常由CNN中间层的卷积层和池化层提取而来。
高级特征:高级特征是在中级特征的基础上进行更深层次的抽象和组合得到的特征,它们对应于更加抽象和复杂的语义概念,例如整个物体、物体之间的关系、场景语义等。高级特征能够帮助理解图像中的整体内容和语义信息,通常由CNN中的深层卷积层和全连接层提取而来。
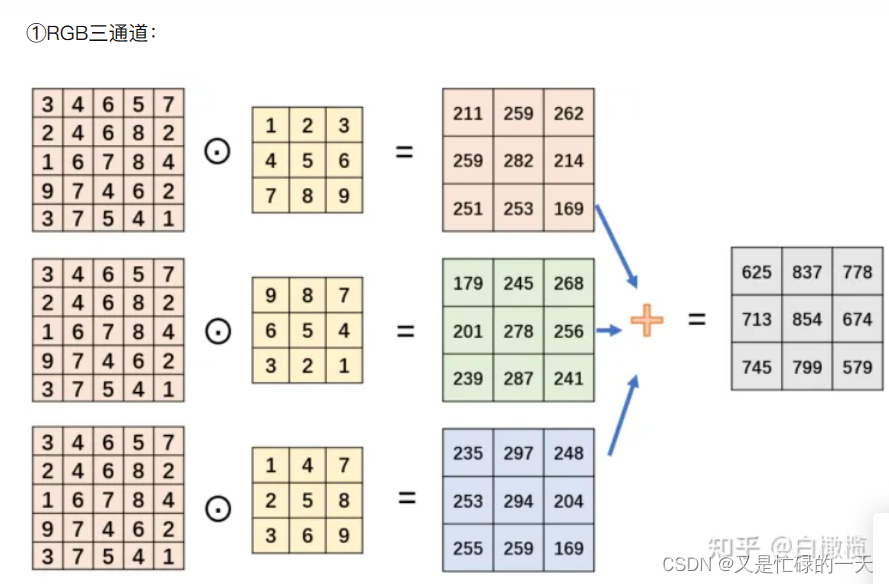
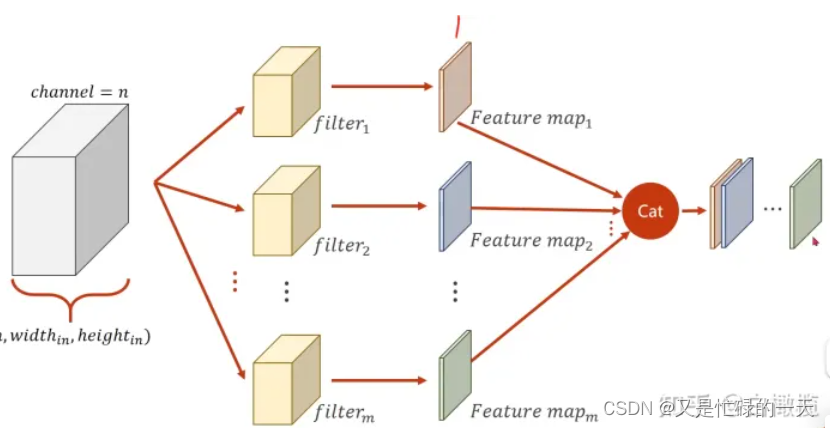
5.多通道N输入,M输出是如何实现的?
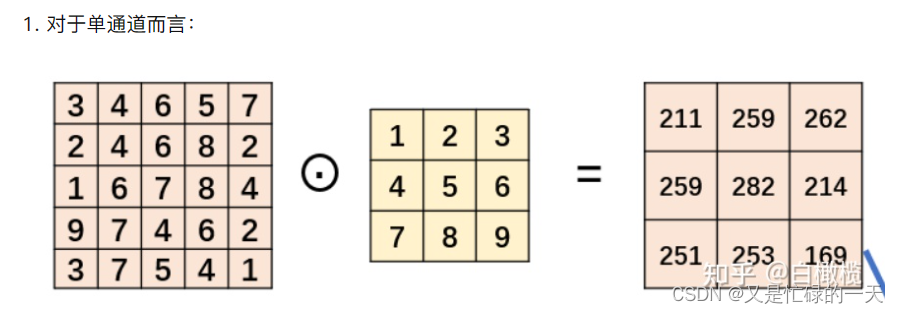
多通道:
对于多通道的N输入,例如一个包含N个通道的输入特征图,卷积核也可以是多通道的。在卷积操作中,可以使用具有相同通道数的多通道卷积核来对输入的每个通道进行卷积操作,然后将每个通道的结果相加得到最终的输出。这样就能够有效地处理多通道的输入,保留了不同通道之间的信息,并且能够学习到多通道特征之间的关联。
对于M输出通道,每个输出通道对应于一个卷积核,这些卷积核会分别作用于输入的多通道特征图,然后将每个通道的结果累加得到最终的M通道输出特征图。这样就能够同时学习多个通道之间的特征表示,提高了模型对输入数据的表征能力。
在实际的卷积神经网络中,多通道的输入和输出能够帮助网络更好地捕获图像、视频等复杂数据中的多模态特征,增强了模型的表示能力和泛化能力。通过多通道的卷积操作,神经网络可以更好地适应不同通道之间的相关性,更准确地提取并表征数据中的信息。
6.1×1的卷积核有什么作用
-
降维和升维:通过使用1×1的卷积核,可以在不改变特征图大小的情况下,减少或增加特征图的通道数。这种操作被称为通道维度的降维和升维,能够帮助减少模型参数数量、提高计算效率,也有利于增强网络的表征能力。
-
线性变换:1×1卷积其实就是对输入进行线性变换,可以理解为对每一个像素点上的向量做线性变换。
-
引入非线性:虽然1×1卷积本身是一个线性变换,但当结合非线性激活函数(如ReLU)时,可以引入非线性,从而增强网络的表达能力。
-
融合多个特征图:可以用1×1卷积来融合多个特征图,将它们的信息整合在一起,从而生成新的特征表示。这有助于网络学习到更抽象和复杂的特征。
1×1卷积核的简单讲解_1*1的卷积核-CSDN博客实列加图片解析更容易理解
二、使用CNN进行XO识别
1.复现参考资料中的代码
1、实现卷积-池化-激活
import numpy as np
import torch
import torch.nn as nn
# 定义输入张量 x,表示一个单通道的 9x9 图像
x = torch.tensor([[[[-1, -1, -1, -1, -1, -1, -1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, -1, -1, 1, -1, -1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, -1, -1, -1, -1, -1, -1, -1]]]], dtype=torch.float)
print(x.shape) # 打印张量 x 的形状
print(x)
print("--------------- 卷积 ---------------")
# 定义三个卷积层,每个卷积层有一个 3x3 的卷积核
conv1 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel, out_channel, kernel_size, stride
conv1.weight.data = torch.Tensor([[[[1, -1, -1], [-1, 1, -1], [-1, -1, 1]]]]) # 设置卷积核权重
conv2 = nn.Conv2d(1, 1, (3, 3), 1)
conv2.weight.data = torch.Tensor([[[[1, -1, 1], [-1, 1, -1], [1, -1, 1]]]])
conv3 = nn.Conv2d(1, 1, (3, 3), 1)
conv3.weight.data = torch.Tensor([[[[-1, -1, 1], [-1, 1, -1], [1, -1, -1]]]])
# 对输入张量 x 分别应用这三个卷积核,得到三个特征图
feature_map1 = conv1(x)
feature_map2 = conv2(x)
feature_map3 = conv3(x)
print(feature_map1 / 9) # 打印第一个特征图
print(feature_map2 / 9) # 打印第二个特征图
print(feature_map3 / 9) # 打印第三个特征图
print("--------------- 池化 ---------------")
max_pool = nn.MaxPool2d(2, padding=0, stride=2) # 最大池化层
zeroPad = nn.ZeroPad2d(padding=(0, 1, 0, 1)) # 零填充层
# 对特征图进行零填充和最大池化操作
feature_map_pad_0_1 = zeroPad(feature_map1)
feature_pool_1 = max_pool(feature_map_pad_0_1)
feature_map_pad_0_2 = zeroPad(feature_map2)
feature_pool_2 = max_pool(feature_map_pad_0_2)
feature_map_pad_0_3 = zeroPad(feature_map3)
feature_pool_3 = max_pool(feature_map_pad_0_3)
print(feature_pool_1.size()) # 打印池化后的特征图形状
print(feature_pool_1 / 9) # 打印池化后的第一个特征图
print(feature_pool_2 / 9) # 打印池化后的第二个特征图
print(feature_pool_3 / 9) # 打印池化后的第三个特征图
print("--------------- 激活 ---------------")
activation_function = nn.ReLU() # ReLU 激活函数
# 对特征图进行 ReLU 激活
feature_relu1 = activation_function(feature_map1)
feature_relu2 = activation_function(feature_map2)
feature_relu3 = activation_function(feature_map3)
print(feature_relu1 / 9) # 打印激活后的第一个特征图
print(feature_relu2 / 9) # 打印激活后的第二个特征图
print(feature_relu3 / 9) # 打印激活后的第三个特征图
torch.Size([1, 1, 9, 9])
tensor([[[[-1., -1., -1., -1., -1., -1., -1., -1., -1.],
[-1., 1., -1., -1., -1., -1., -1., 1., -1.],
[-1., -1., 1., -1., -1., -1., 1., -1., -1.],
[-1., -1., -1., 1., -1., 1., -1., -1., -1.],
[-1., -1., -1., -1., 1., -1., -1., -1., -1.],
[-1., -1., -1., 1., -1., 1., -1., -1., -1.],
[-1., -1., 1., -1., -1., -1., 1., -1., -1.],
[-1., 1., -1., -1., -1., -1., -1., 1., -1.],
[-1., -1., -1., -1., -1., -1., -1., -1., -1.]]]])
--------------- 卷积 ---------------
tensor([[[[ 0.7706, -0.1183, 0.1040, 0.3262, 0.5484, -0.1183, 0.3262],
[-0.1183, 0.9928, -0.1183, 0.3262, -0.1183, 0.1040, -0.1183],
[ 0.1040, -0.1183, 0.9928, -0.3405, 0.1040, -0.1183, 0.5484],
[ 0.3262, 0.3262, -0.3405, 0.5484, -0.3405, 0.3262, 0.3262],
[ 0.5484, -0.1183, 0.1040, -0.3405, 0.9928, -0.1183, 0.1040],
[-0.1183, 0.1040, -0.1183, 0.3262, -0.1183, 0.9928, -0.1183],
[ 0.3262, -0.1183, 0.5484, 0.3262, 0.1040, -0.1183, 0.7706]]]],
grad_fn=<DivBackward0>)
tensor([[[[ 0.3064, -0.5824, 0.0842, -0.1380, 0.0842, -0.5824, 0.3064],
[-0.5824, 0.5287, -0.5824, 0.3064, -0.5824, 0.5287, -0.5824],
[ 0.0842, -0.5824, 0.5287, -0.8047, 0.5287, -0.5824, 0.0842],
[-0.1380, 0.3064, -0.8047, 0.9731, -0.8047, 0.3064, -0.1380],
[ 0.0842, -0.5824, 0.5287, -0.8047, 0.5287, -0.5824, 0.0842],
[-0.5824, 0.5287, -0.5824, 0.3064, -0.5824, 0.5287, -0.5824],
[ 0.3064, -0.5824, 0.0842, -0.1380, 0.0842, -0.5824, 0.3064]]]],
grad_fn=<DivBackward0>)
tensor([[[[ 0.3616, -0.0828, 0.5838, 0.3616, 0.1394, -0.0828, 0.8061],
[-0.0828, 0.1394, -0.0828, 0.3616, -0.0828, 1.0283, -0.0828],
[ 0.5838, -0.0828, 0.1394, -0.3051, 1.0283, -0.0828, 0.1394],
[ 0.3616, 0.3616, -0.3051, 0.5838, -0.3051, 0.3616, 0.3616],
[ 0.1394, -0.0828, 1.0283, -0.3051, 0.1394, -0.0828, 0.5838],
[-0.0828, 1.0283, -0.0828, 0.3616, -0.0828, 0.1394, -0.0828],
[ 0.8061, -0.0828, 0.1394, 0.3616, 0.5838, -0.0828, 0.3616]]]],
grad_fn=<DivBackward0>)
--------------- 池化 ---------------
torch.Size([1, 1, 4, 4])
tensor([[[[0.9928, 0.3262, 0.5484, 0.3262],
[0.3262, 0.9928, 0.3262, 0.5484],
[0.5484, 0.3262, 0.9928, 0.1040],
[0.3262, 0.5484, 0.1040, 0.7706]]]], grad_fn=<DivBackward0>)
tensor([[[[0.5287, 0.3064, 0.5287, 0.3064],
[0.3064, 0.9731, 0.5287, 0.0842],
[0.5287, 0.5287, 0.5287, 0.0842],
[0.3064, 0.0842, 0.0842, 0.3064]]]], grad_fn=<DivBackward0>)
tensor([[[[0.3616, 0.5838, 1.0283, 0.8061],
[0.5838, 0.5838, 1.0283, 0.3616],
[1.0283, 1.0283, 0.1394, 0.5838],
[0.8061, 0.3616, 0.5838, 0.3616]]]], grad_fn=<DivBackward0>)
--------------- 激活 ---------------
tensor([[[[0.7706, 0.0000, 0.1040, 0.3262, 0.5484, 0.0000, 0.3262],
[0.0000, 0.9928, 0.0000, 0.3262, 0.0000, 0.1040, 0.0000],
[0.1040, 0.0000, 0.9928, 0.0000, 0.1040, 0.0000, 0.5484],
[0.3262, 0.3262, 0.0000, 0.5484, 0.0000, 0.3262, 0.3262],
[0.5484, 0.0000, 0.1040, 0.0000, 0.9928, 0.0000, 0.1040],
[0.0000, 0.1040, 0.0000, 0.3262, 0.0000, 0.9928, 0.0000],
[0.3262, 0.0000, 0.5484, 0.3262, 0.1040, 0.0000, 0.7706]]]],
grad_fn=<DivBackward0>)
tensor([[[[0.3064, 0.0000, 0.0842, 0.0000, 0.0842, 0.0000, 0.3064],
[0.0000, 0.5287, 0.0000, 0.3064, 0.0000, 0.5287, 0.0000],
[0.0842, 0.0000, 0.5287, 0.0000, 0.5287, 0.0000, 0.0842],
[0.0000, 0.3064, 0.0000, 0.9731, 0.0000, 0.3064, 0.0000],
[0.0842, 0.0000, 0.5287, 0.0000, 0.5287, 0.0000, 0.0842],
[0.0000, 0.5287, 0.0000, 0.3064, 0.0000, 0.5287, 0.0000],
[0.3064, 0.0000, 0.0842, 0.0000, 0.0842, 0.0000, 0.3064]]]],
grad_fn=<DivBackward0>)
tensor([[[[0.3616, 0.0000, 0.5838, 0.3616, 0.1394, 0.0000, 0.8061],
[0.0000, 0.1394, 0.0000, 0.3616, 0.0000, 1.0283, 0.0000],
[0.5838, 0.0000, 0.1394, 0.0000, 1.0283, 0.0000, 0.1394],
[0.3616, 0.3616, 0.0000, 0.5838, 0.0000, 0.3616, 0.3616],
[0.1394, 0.0000, 1.0283, 0.0000, 0.1394, 0.0000, 0.5838],
[0.0000, 1.0283, 0.0000, 0.3616, 0.0000, 0.1394, 0.0000],
[0.8061, 0.0000, 0.1394, 0.3616, 0.5838, 0.0000, 0.3616]]]],
grad_fn=<DivBackward0>)
可视化:
# https://blog.csdn.net/qq_26369907/article/details/88366147
# https://zhuanlan.zhihu.com/p/405242579
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 #有中文出现的情况,需要u'内容
x = torch.tensor([[[[-1, -1, -1, -1, -1, -1, -1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, -1, -1, 1, -1, -1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, -1, -1, -1, -1, -1, -1, -1]]]], dtype=torch.float)
print(x.shape)
print(x)
img = x.data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.title('原图')
plt.show()
print("--------------- 卷积 ---------------")
conv1 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv1.weight.data = torch.Tensor([[[[1, -1, -1],
[-1, 1, -1],
[-1, -1, 1]]
]])
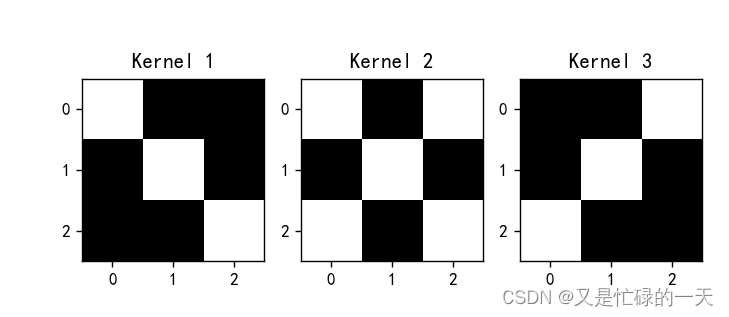
img = conv1.weight.data.squeeze().numpy() # 将输出转换为图片的格式
plt.figure()
plt.subplot(131)
plt.imshow(img, cmap='gray')
plt.title('Kernel 1')
conv2 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv2.weight.data = torch.Tensor([[[[1, -1, 1],
[-1, 1, -1],
[1, -1, 1]]
]])
img = conv2.weight.data.squeeze().numpy() # 将输出转换为图片的格式
plt.subplot(132)
plt.imshow(img, cmap='gray')
plt.title('Kernel 2')
conv3 = nn.Conv2d(1, 1, (3, 3), 1) # in_channel , out_channel , kennel_size , stride
conv3.weight.data = torch.Tensor([[[[-1, -1, 1],
[-1, 1, -1],
[1, -1, -1]]
]])
img = conv3.weight.data.squeeze().numpy() # 将输出转换为图片的格式
plt.subplot(133)
plt.imshow(img, cmap='gray')
plt.title('Kernel 3')
plt.show()
feature_map1 = conv1(x)
feature_map2 = conv2(x)
feature_map3 = conv3(x)
print(feature_map1 / 9)
print(feature_map2 / 9)
print(feature_map3 / 9)
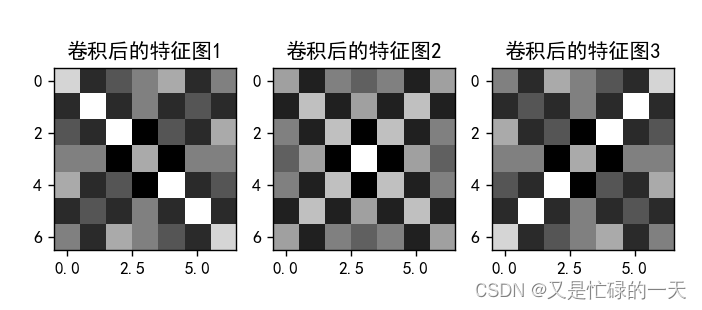
plt.figure()
img = feature_map1.data.squeeze().numpy() # 将输出转换为图片的格式
plt.subplot(131)
plt.imshow(img, cmap='gray')
plt.title('卷积后的特征图1')
img = feature_map2.data.squeeze().numpy() # 将输出转换为图片的格式
plt.subplot(132)
plt.imshow(img, cmap='gray')
plt.title('卷积后的特征图2')
img = feature_map3.data.squeeze().numpy() # 将输出转换为图片的格式
plt.subplot(133)
plt.imshow(img, cmap='gray')
plt.title('卷积后的特征图3')
plt.show()
print("--------------- 池化 ---------------")
max_pool = nn.MaxPool2d(2, padding=0, stride=2) # Pooling
zeroPad = nn.ZeroPad2d(padding=(0, 1, 0, 1)) # pad 0 , Left Right Up Down
feature_map_pad_0_1 = zeroPad(feature_map1)
feature_pool_1 = max_pool(feature_map_pad_0_1)
feature_map_pad_0_2 = zeroPad(feature_map2)
feature_pool_2 = max_pool(feature_map_pad_0_2)
feature_map_pad_0_3 = zeroPad(feature_map3)
feature_pool_3 = max_pool(feature_map_pad_0_3)
print(feature_pool_1.size())
print(feature_pool_1 / 9)
print(feature_pool_2 / 9)
print(feature_pool_3 / 9)
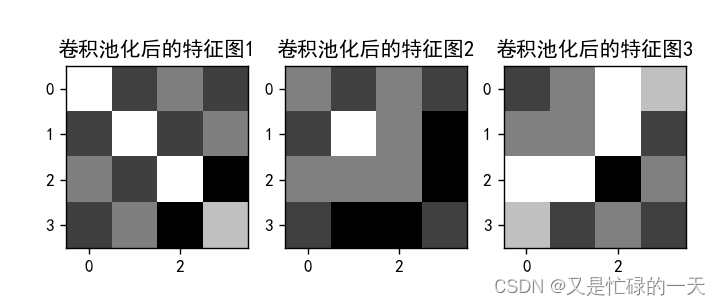
img = feature_pool_1.data.squeeze().numpy() # 将输出转换为图片的格式
plt.figure()
plt.subplot(131)
plt.imshow(img, cmap='gray')
plt.title('卷积池化后的特征图1')
img = feature_pool_2.data.squeeze().numpy() # 将输出转换为图片的格式
plt.subplot(132)
plt.imshow(img, cmap='gray')
plt.title('卷积池化后的特征图2')
img = feature_pool_3.data.squeeze().numpy() # 将输出转换为图片的格式
plt.subplot(133)
plt.imshow(img, cmap='gray')
plt.title('卷积池化后的特征图3')
plt.show()
print("--------------- 激活 ---------------")
activation_function = nn.ReLU()
feature_relu1 = activation_function(feature_map1)
feature_relu2 = activation_function(feature_map2)
feature_relu3 = activation_function(feature_map3)
print(feature_relu1 / 9)
print(feature_relu2 / 9)
print(feature_relu3 / 9)
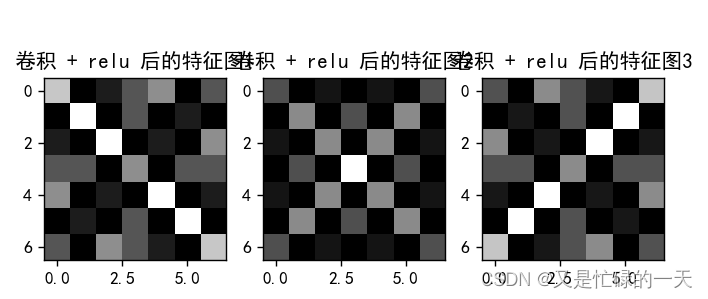
plt.figure()
img = feature_relu1.data.squeeze().numpy() # 将输出转换为图片的格式
plt.subplot(131)
plt.imshow(img, cmap='gray')
plt.title('卷积 + relu 后的特征图1')
img = feature_relu2.data.squeeze().numpy() # 将输出转换为图片的格式
plt.subplot(132)
plt.imshow(img, cmap='gray')
plt.title('卷积 + relu 后的特征图2')
img = feature_relu3.data.squeeze().numpy() # 将输出转换为图片的格式
plt.subplot(133)
plt.imshow(img, cmap='gray')
plt.title('卷积 + relu 后的特征图3')
plt.show()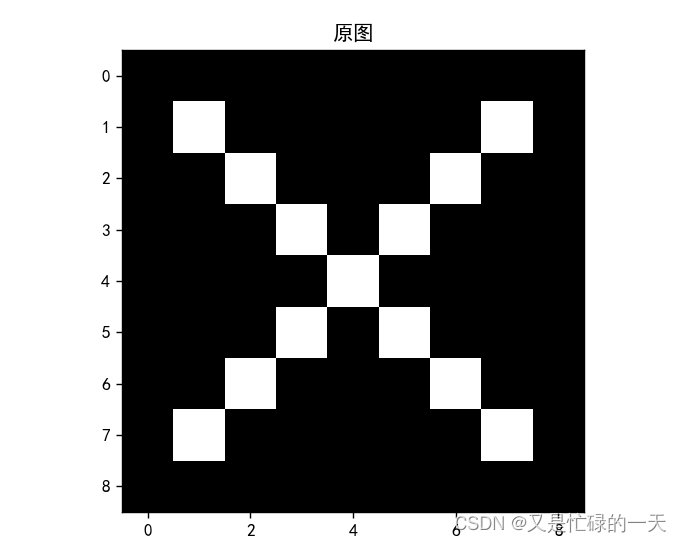
2、基于CNN的XO识别
创建文档
下载的数据集没有分测试集和训练集。共2000张图片,X、O各1000张。
从X、O文件夹,分别取出150张作为测试集。
文件夹train_data:放置训练集 1700张图片
文件夹test_data: 放置测试集 300张图片
1. 数据集
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
data_train = datasets.ImageFolder('train_data', transforms)
data_test = datasets.ImageFolder('test_data', transforms)
train_loader = DataLoader(data_train, batch_size=64, shuffle=True)
test_loader = DataLoader(data_test, batch_size=64, shuffle=True)
for i, data in enumerate(train_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
for i, data in enumerate(test_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
可视化一下数据集
import matplotlib.pyplot as plt
a=0
plt.figure()
index=0
for i in labels:
if i == 0 and a<5:
plt.subplot(151+a)
plt.imshow(images[index].data.squeeze().numpy(),cmap='gray')
plt.title('circle '+str(a+1))
a+=1
if a==5:
break
index+=1
plt.show()
a=0
plt.figure()
index=0
for i in labels:
if i == 1 and a<5:
plt.subplot(151+a)
plt.imshow(images[index].data.squeeze().numpy(),cmap='gray')
plt.title('crosses '+str(a+1))
a+=1
if a==5:
break
index+=1
plt.show()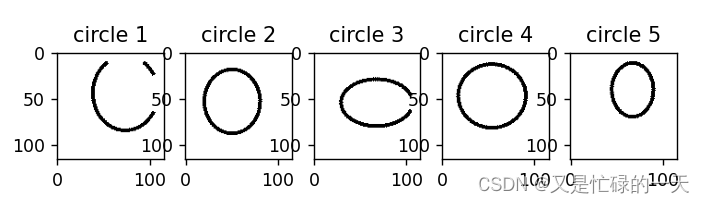
2. 构建模型
import torch.nn as nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200)
self.fc2 = nn.Linear(1200, 64)
self.fc3 = nn.Linear(64, 2)
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x3、训练模型
model = CNN()
loss = nn.CrossEntropyLoss()
opti = torch.optim.SGD(model.parameters(), lr=0.1)
epochs = 10
for epoch in range(epochs):
total_loss = 0
for i, data in enumerate(train_loader):
images, labels = data
out = model(images)
one_loss = loss(out, labels)
opti.zero_grad()
one_loss.backward()
opti.step()
total_loss += one_loss
if (i + 1) % 10 == 0:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, total_loss / 100))
total_loss = 0.0
print('finished train')
# 保存模型
torch.save(model, 'model.pth') # 保存的是模型, 不止是w和b权重值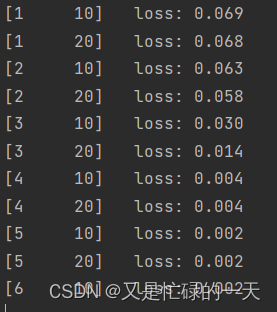
4、模型测试
import matplotlib.pyplot as plt
# 读取模型
model_load = torch.load('model.pth')
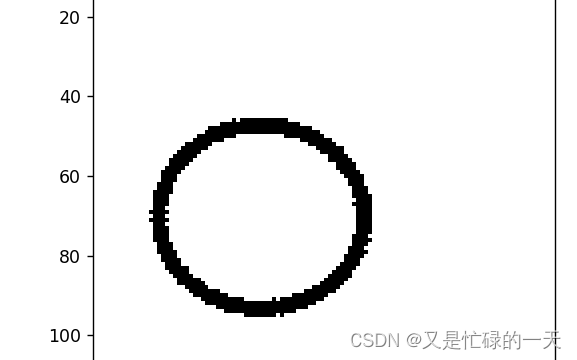
# 读取一张图片 images[0],测试
print("labels[0] truth:\t", labels[0])
x = images[0].unsqueeze(0)
predicted = torch.max(model_load(x), 1)
print("labels[0] predict:\t", predicted.indices)
img = images[0].data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.show()
5. 计算模型的准确率
# 读取模型
model_load = torch.load('model.pth')
correct = 0
total = 0
with torch.no_grad(): # 进行评测的时候网络不更新梯度
for data in test_loader: # 读取测试集
images, labels = data
outputs = model_load(images)
_, predicted = torch.max(outputs.data, 1) # 取出 最大值的索引 作为 分类结果
total += labels.size(0) # labels 的长度
correct += (predicted == labels).sum().item() # 预测正确的数目
print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))6、查看训练好的模型特征图
import torch.optim
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
data_train = datasets.ImageFolder('train_data', transforms)
data_test = datasets.ImageFolder('test_data', transforms)
train_loader = DataLoader(data_train, batch_size=64, shuffle=True)
test_loader = DataLoader(data_test, batch_size=64, shuffle=True)
for i, data in enumerate(train_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
for i, data in enumerate(test_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
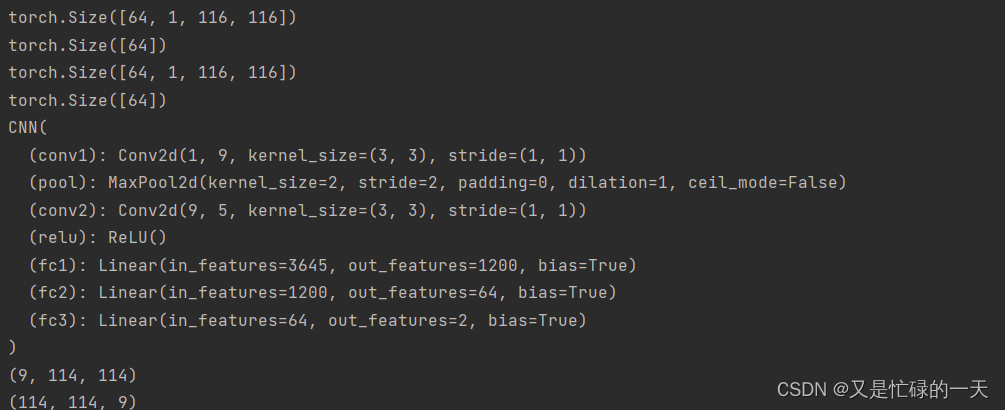
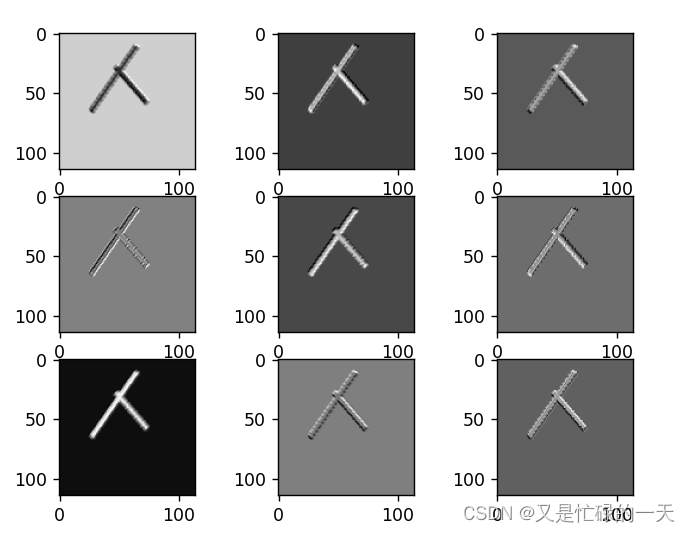
import torch.nn as nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200)
self.fc2 = nn.Linear(1200, 64)
self.fc3 = nn.Linear(64, 2)
def forward(self, x):
outputs = []
x = self.conv1(x)
outputs.append(x)
x = self.relu(x)
outputs.append(x)
x = self.pool(x)
outputs.append(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return outputs
import matplotlib.pyplot as plt
import numpy as np
# 读取模型
model = torch.load('model.pth')
print(model)
x = images[0].unsqueeze(0)
# forward正向传播过程
out_put = model(x)
for feature_map in out_put:
# [N, C, H, W] -> [C, H, W] 维度变换
im = np.squeeze(feature_map.detach().numpy())
print(im.shape)
# [C, H, W] -> [H, W, C]
im = np.transpose(im, [1, 2, 0])
print(im.shape)
# show 9 feature maps
plt.figure()
for i in range(9):
ax = plt.subplot(3, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
# [H, W, C]
# 特征矩阵每一个channel对应的是一个二维的特征矩阵,就像灰度图像一样,channel=1
# plt.imshow(im[:, :, i])
plt.imshow(im[:, :, i], cmap='gray')
plt.show()
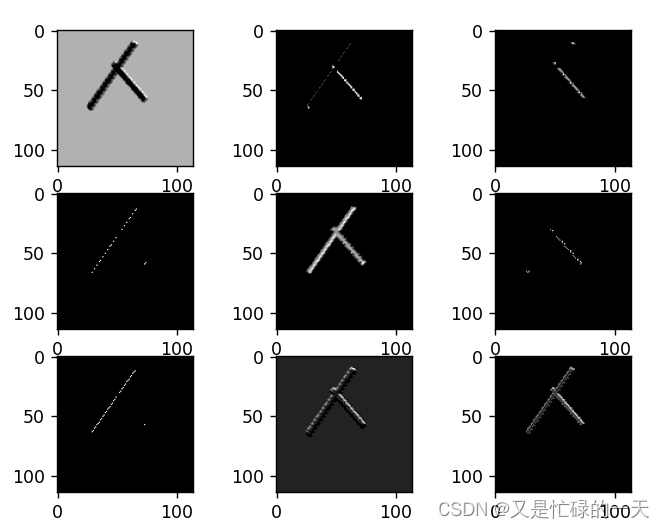
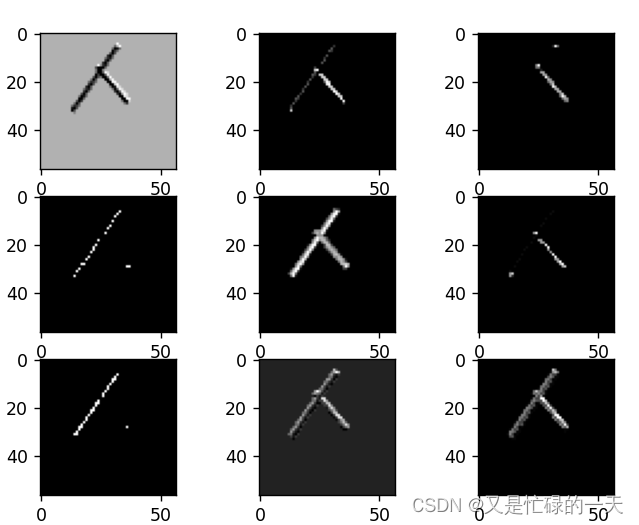
7. 查看训练好的模型的卷积核
import matplotlib.pyplot as plt
import torch
import torch.optim
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
data_train = datasets.ImageFolder('train_data', transforms)
data_test = datasets.ImageFolder('test_data', transforms)
train_loader = DataLoader(data_train, batch_size=64, shuffle=True)
test_loader = DataLoader(data_test, batch_size=64, shuffle=True)
for i, data in enumerate(train_loader):
images, labels = data
break
for i, data in enumerate(test_loader):
images, labels = data
break
import matplotlib.pyplot as plt
import numpy as np
# 读取模型
model = torch.load('model.pth')
print(model)
x = images[0].unsqueeze(0)
# forward正向传播过程
out_put = model(x)
for feature_map in out_put:
# [N, C, H, W] -> [C, H, W] 维度变换
im = np.squeeze(feature_map.detach().numpy())
print(im.shape)
# [C, H, W] -> [H, W, C]
im = np.transpose(im, [1, 2, 0])
print(im.shape)
# show 9 feature maps
plt.figure()
for i in range(9):
ax = plt.subplot(3, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
# [H, W, C]
# 特征矩阵每一个channel对应的是一个二维的特征矩阵,就像灰度图像一样,channel=1
# plt.imshow(im[:, :, i])
plt.imshow(im[:, :, i], cmap='gray')
plt.show()
# 读取模型
model = torch.load('model.pth')
print(model)
x = images[0].unsqueeze(0)
# forward正向传播过程
out_put = model(x)
weights_keys = model.state_dict().keys()
for key in weights_keys:
print("key :", key)
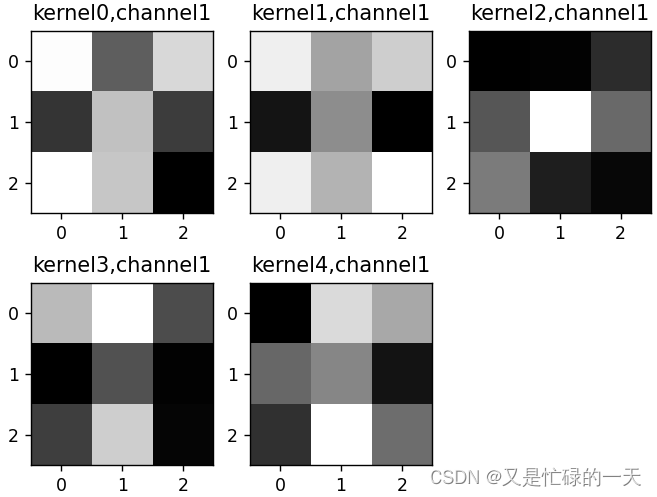
# 卷积核通道排列顺序 [kernel_number, kernel_channel, kernel_height, kernel_width]
if key == "conv1.weight":
weight_t = model.state_dict()[key].numpy()
print("weight_t.shape", weight_t.shape)
k = weight_t[:, 0, :, :] # 获取第一个卷积核的信息参数
# show 9 kernel ,1 channel
plt.figure()
for i in range(9):
ax = plt.subplot(3, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
plt.imshow(k[i, :, :], cmap='gray')
title_name = 'kernel' + str(i) + ',channel1'
plt.title(title_name)
plt.show()
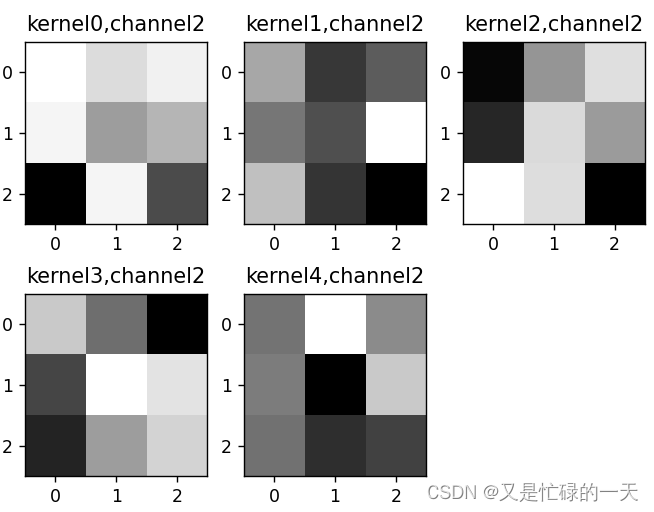
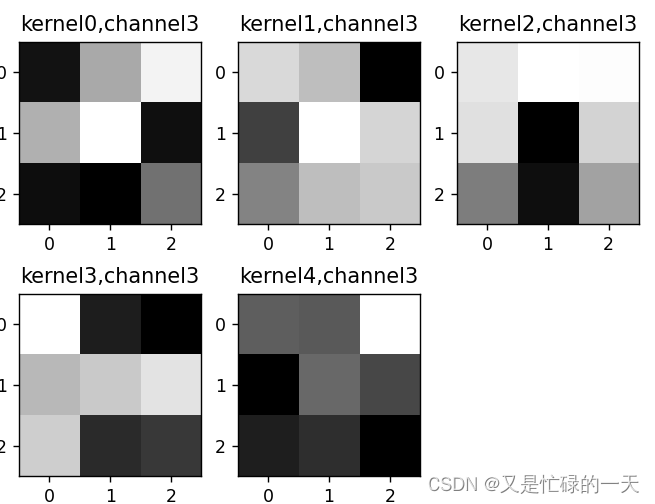
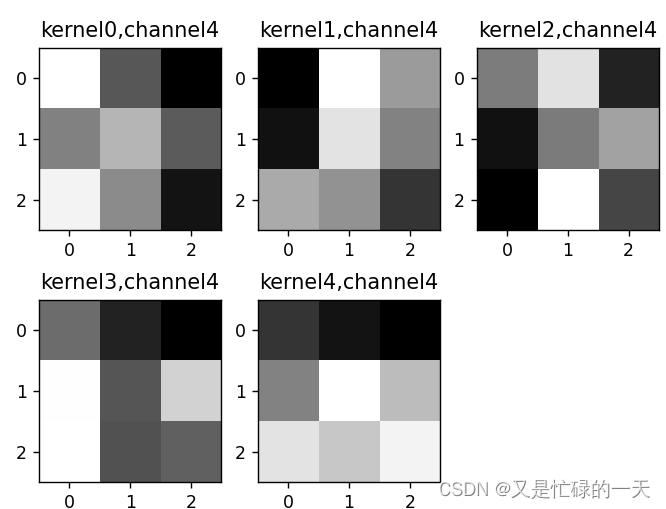
if key == "conv2.weight":
weight_t = model.state_dict()[key].numpy()
print("weight_t.shape", weight_t.shape)
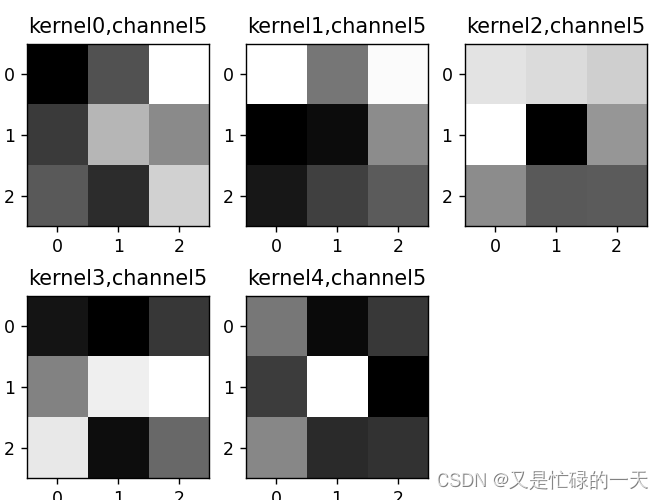
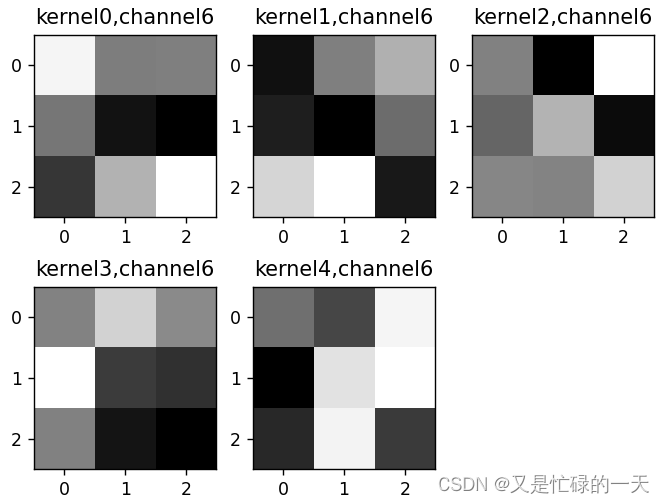
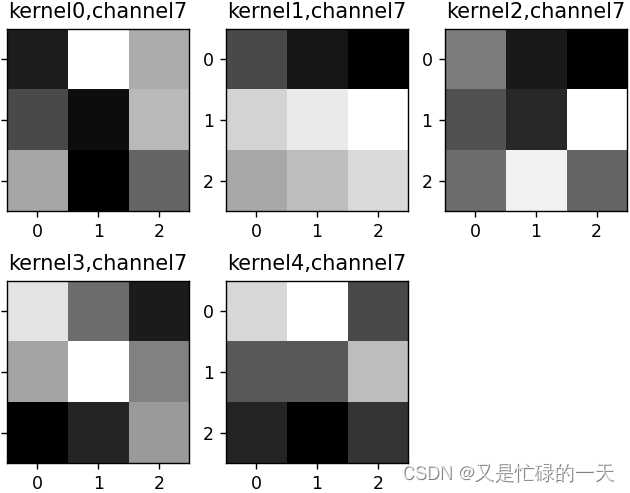
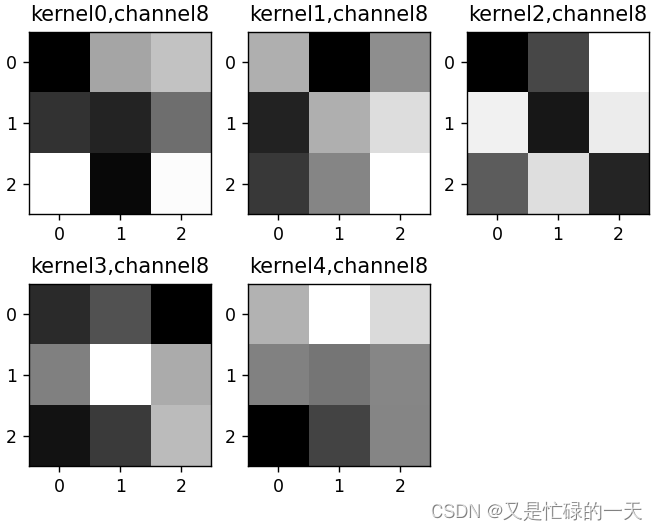
k = weight_t[:, :, :, :] # 获取第一个卷积核的信息参数
print(k.shape)
print(k)
plt.figure()
for c in range(9):
channel = k[:, c, :, :]
for i in range(5):
ax = plt.subplot(2, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
plt.imshow(channel[i, :, :], cmap='gray')
title_name = 'kernel' + str(i) + ',channel' + str(c)
plt.title(title_name)
plt.show()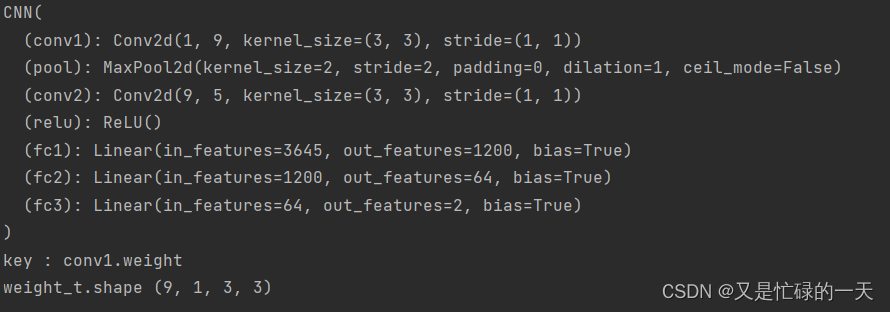

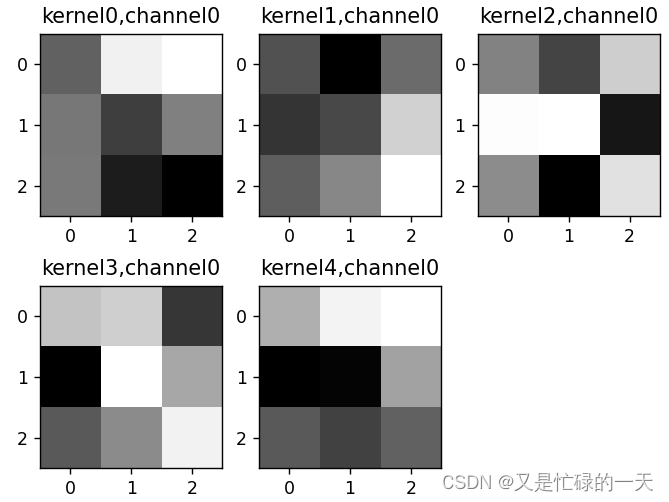
2.重新设计网络结构
至少增加一个卷积层,卷积层达到三层以上
import torch.nn as nn
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
# 将输入的图片先转换为灰度图,然后将其转换为 Tensor,并进行归一化处理。这样处理后的数据可以直接作为模型的输入。
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
# dataset.ImageFolder 将数据集封装为dataset类型
# root (string): 数据集的根目录路径。在这个根目录下,每个类别的图像应该被存放在一个单独的子文件夹中。每个子文件夹的名称将被视为一个类别,并且其中的图像将被标记为该类别。
# transform (callable, optional): 一个对图像进行变换的函数或转换操作。可以使用 transforms 模块中的函数来对图像进行预处理、数据增强等操作,例如将图像转换为 Tensor 类型、调整大小、裁剪等。
data_train = datasets.ImageFolder('train_data', transforms)
data_test = datasets.ImageFolder('test_data', transforms)
train_loader = DataLoader(data_train, batch_size=64, shuffle=True)
test_loader = DataLoader(data_test, batch_size=64, shuffle=True)
for i, data in enumerate(train_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
for i, data in enumerate(test_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=9, kernel_size=3)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=9, out_channels=9, kernel_size=3)
self.conv3 = nn.Conv2d(in_channels=9, out_channels=5, kernel_size=3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(in_features=12 * 12 * 5, out_features=300)
self.fc2 = nn.Linear(in_features=300, out_features=64)
self.fc3 = nn.Linear(in_features=64, out_features=2)
def forward(self, input):
# 116 * 116
output = self.pool(self.relu(self.conv1(input)))
# 114 * 114 --> 57 * 57
output = self.pool(self.relu(self.conv2(output)))
# 57 * 57 --> 55 * 55 -- > 27 * 27
output = self.pool(self.relu(self.conv3(output)))
# 25 * 25 --> 12 * 12
output = output.view(-1, 12 * 12 * 5)
output = self.relu(self.fc1(output))
output = self.relu(self.fc2(output))
output = self.fc3(output)
return output
model = CNN()
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epochs = 30
for epoch in range(epochs):
total_loss = 0.0
for i, data in enumerate(train_loader):
images, labels = data
out = model(images)
one_loss = loss(out, labels)
optimizer.zero_grad()
one_loss.backward()
optimizer.step()
total_loss += one_loss
if (i + 1) % 10 == 0:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, total_loss / 100))
total_loss = 0.0
print('train finish')
torch.save(model, 'model.pth') # 保存的是模型, 不止是w和b权重值
torch.save(model.state_dict(), 'model_name1.pth') # 保存的是w和b权重值
correct = 0
total = 0
with torch.no_grad(): # 进行评测的时候网络不更新梯度
for data in test_loader: # 读取测试集
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 取出 最大值的索引 作为 分类结果
total += labels.size(0) # labels 的长度
correct += (predicted == labels).sum().item() # 预测正确的数目
print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))
# 损失降低的很快,但是最后的时候收敛很慢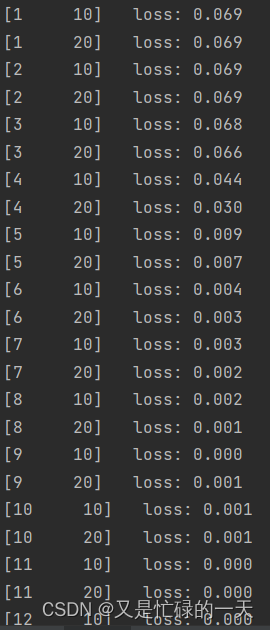
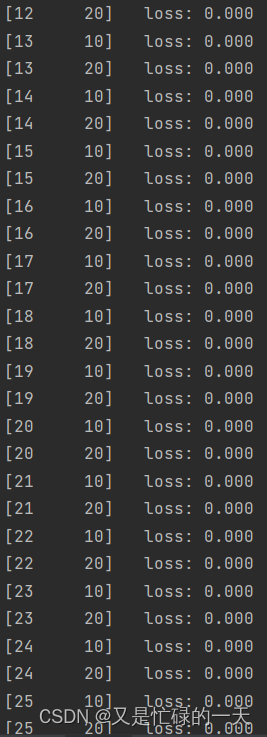
去掉池化层,对比“有无池化”的效果
import torch.nn as nn
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
# 将输入的图片先转换为灰度图,然后将其转换为 Tensor,并进行归一化处理。这样处理后的数据可以直接作为模型的输入。
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
# dataset.ImageFolder 将数据集封装为dataset类型
# root (string): 数据集的根目录路径。在这个根目录下,每个类别的图像应该被存放在一个单独的子文件夹中。每个子文件夹的名称将被视为一个类别,并且其中的图像将被标记为该类别。
# transform (callable, optional): 一个对图像进行变换的函数或转换操作。可以使用 transforms 模块中的函数来对图像进行预处理、数据增强等操作,例如将图像转换为 Tensor 类型、调整大小、裁剪等。
data_train = datasets.ImageFolder('train_data', transforms)
data_test = datasets.ImageFolder('test_data', transforms)
train_loader = DataLoader(data_train, batch_size=64, shuffle=True)
test_loader = DataLoader(data_test, batch_size=64, shuffle=True)
for i, data in enumerate(train_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
for i, data in enumerate(test_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=9, kernel_size=3)
self.conv2 = nn.Conv2d(in_channels=9, out_channels=5, kernel_size=3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(in_features=112 * 112 * 5, out_features=1200)
self.fc2 = nn.Linear(in_features=1200, out_features=64)
self.fc3 = nn.Linear(in_features=64, out_features=2)
def forward(self, input):
output = self.relu(self.conv1(input))
output = self.relu(self.conv2(output))
output = output.view(-1, 112 * 112 * 5)
output = self.relu(self.fc1(output))
output = self.relu(self.fc2(output))
output = self.fc3(output)
return output
model = CNN()
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epochs = 30
for epoch in range(epochs):
total_loss = 0.0
for i, data in enumerate(train_loader):
images, labels = data
out = model(images)
one_loss = loss(out, labels)
optimizer.zero_grad()
one_loss.backward()
optimizer.step()
total_loss += one_loss
if (i + 1) % 10 == 0:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, total_loss / 100))
total_loss = 0.0
print('train finish')
torch.save(model, 'model.pth') # 保存的是模型, 不止是w和b权重值
torch.save(model.state_dict(), 'model_name1.pth') # 保存的是w和b权重值
correct = 0
total = 0
with torch.no_grad(): # 进行评测的时候网络不更新梯度
for data in test_loader: # 读取测试集
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 取出 最大值的索引 作为 分类结果
total += labels.size(0) # labels 的长度
correct += (predicted == labels).sum().item() # 预测正确的数目
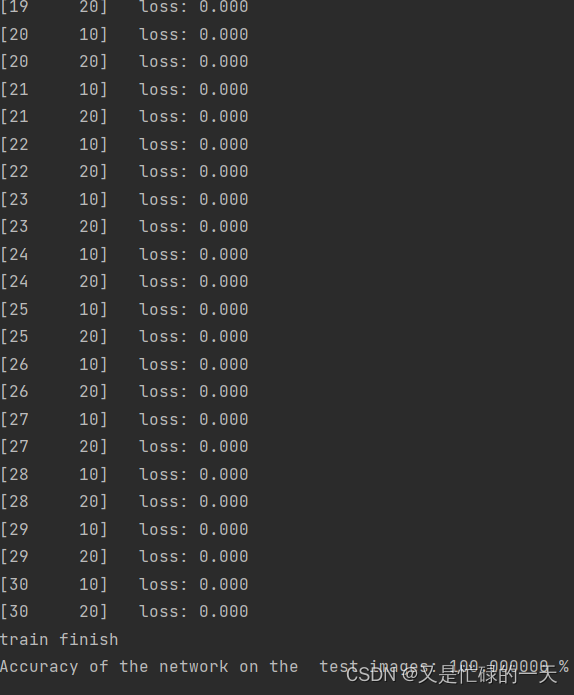
print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))
# 损失降低的很快,但是最后的时候收敛很慢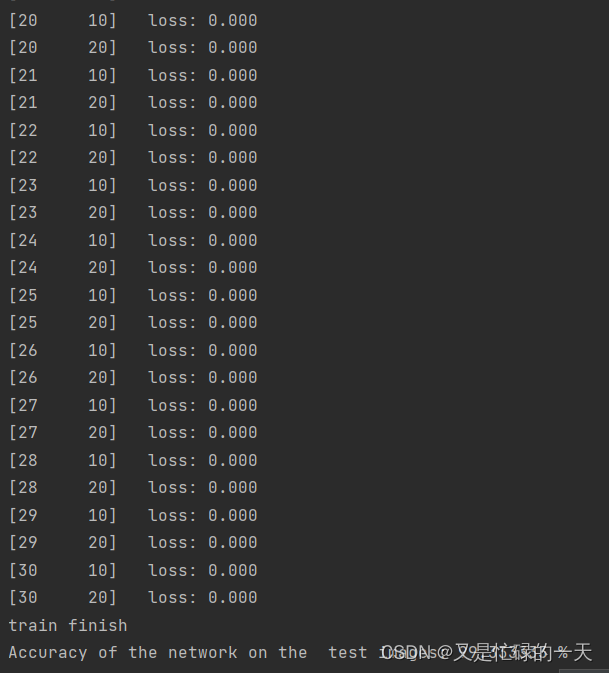
性能几乎不变,但是在实验过程中,明显发现因为没有池化层对图像的压缩处理,图片到全连接层依旧还有 112*112的大小,那么就依旧需要112*112*5的参数,相比于具有池化层,不仅大大减少了参数的数量,并且大大提升了运行的效率。
修改“通道数”等超参数,观察变化
import torch.nn as nn
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
# 将输入的图片先转换为灰度图,然后将其转换为 Tensor,并进行归一化处理。这样处理后的数据可以直接作为模型的输入。
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
# dataset.ImageFolder 将数据集封装为dataset类型
# root (string): 数据集的根目录路径。在这个根目录下,每个类别的图像应该被存放在一个单独的子文件夹中。每个子文件夹的名称将被视为一个类别,并且其中的图像将被标记为该类别。
# transform (callable, optional): 一个对图像进行变换的函数或转换操作。可以使用 transforms 模块中的函数来对图像进行预处理、数据增强等操作,例如将图像转换为 Tensor 类型、调整大小、裁剪等。
data_train = datasets.ImageFolder('train_data', transforms)
data_test = datasets.ImageFolder('test_data', transforms)
train_loader = DataLoader(data_train, batch_size=64, shuffle=True)
test_loader = DataLoader(data_test, batch_size=64, shuffle=True)
for i, data in enumerate(train_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
for i, data in enumerate(test_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=18, kernel_size=3)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=18, out_channels=5, kernel_size=3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(in_features=27 * 27 * 5, out_features=1200)
self.fc2 = nn.Linear(in_features=1200, out_features=64)
self.fc3 = nn.Linear(in_features=64, out_features=2)
def forward(self, input):
output = self.pool(self.relu(self.conv1(input)))
output = self.pool(self.relu(self.conv2(output)))
output = output.view(-1, 27 * 27 * 5)
output = self.relu(self.fc1(output))
output = self.relu(self.fc2(output))
output = self.fc3(output)
return output
model = CNN()
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epochs = 10
for epoch in range(epochs):
total_loss = 0.0
for i, data in enumerate(train_loader):
images, labels = data
out = model(images)
one_loss = loss(out, labels)
optimizer.zero_grad()
one_loss.backward()
optimizer.step()
total_loss += one_loss
if (i + 1) % 10 == 0:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, total_loss / 100))
total_loss = 0.0
print('train finish')
torch.save(model, 'model.pth') # 保存的是模型, 不止是w和b权重值
torch.save(model.state_dict(), 'model_name1.pth') # 保存的是w和b权重值
print('channel = 18')
correct = 0
total = 0
with torch.no_grad(): # 进行评测的时候网络不更新梯度
for data in test_loader: # 读取测试集
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 取出 最大值的索引 作为 分类结果
total += labels.size(0) # labels 的长度
correct += (predicted == labels).sum().item() # 预测正确的数目
print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))
# 损失降低的很快,但是最后的时候收敛很慢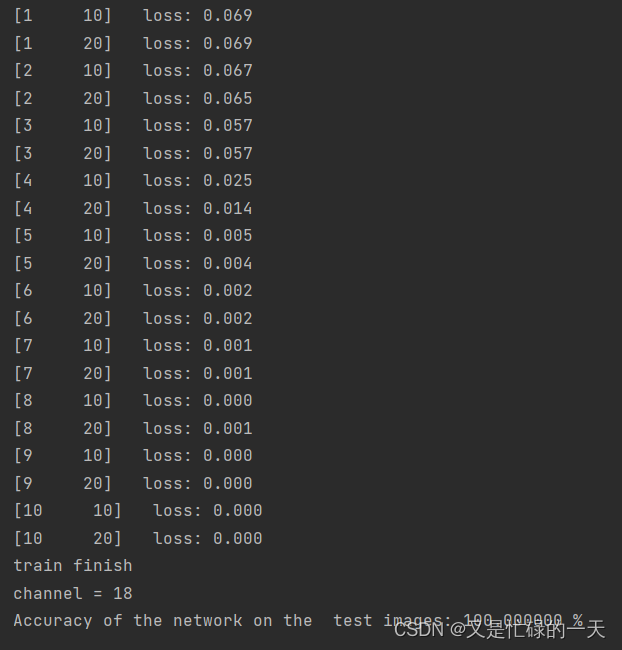
3.可视化
探索低级特征、中级特征、高级特征
低级特征通常是指图像中的边缘、角点等基本形状信息。这些特征由网络的第一层卷积层提取得到。卷积操作可以在图像中滑动一个小的窗口(卷积核),并计算窗口内像素的加权和,从而检测出图像的边缘和纹理等低级特征。
中级特征是在低级特征的基础上进一步组合和抽象得到的特征。这些特征由网络的中间层卷积层提取得到。通过多个卷积和池化层的叠加,网络可以逐渐扩大感受野,并捕捉到更大范围的图像结构和纹理信息。中级特征可以表示物体的局部形状和纹理特征。
高级特征是对整个图像的全局抽象和语义理解。这些特征由网络的最后几层卷积层和全连接层提取得到。在这些层中,网络学习到了更加抽象和语义化的特征表示,可以表示物体的类别、位置和姿态等高级特征。
import os
import matplotlib.pyplot as plt
import torch
from PIL import Image
import numpy as np
import torch.nn as nn
def conv2d(input, Kernel):
plt.figure()
Conv = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, bias=False)
Conv.weight = torch.nn.Parameter(Kernel)
Conv_output = Conv(input)
Conv_output_picture = Conv_output.squeeze().cpu().detach().numpy()
plt.imshow(Conv_output_picture, cmap='gray')
plt.show()
return Conv_output
Kernel = torch.tensor([[1.0, -1.0, -1.0],
[2.0, 1.0, -2.0],
[1.0, -1.0, -1.0]], dtype=torch.float32).view([1, 1, 3, 3])
# 读取图片
img = Image.open('风景.jpg')
img = img.convert('L')
print(img.size)
# 将图像转换为NumPy数组
img = img.resize((350, 350))
img_array = np.array(img)
x = torch.tensor(img_array, dtype=torch.float32).view([1, 1, 350, 350])
x_1 = conv2d(x, Kernel)
x_2 = conv2d(x_1, Kernel)
x_3 = conv2d(x_2, Kernel)

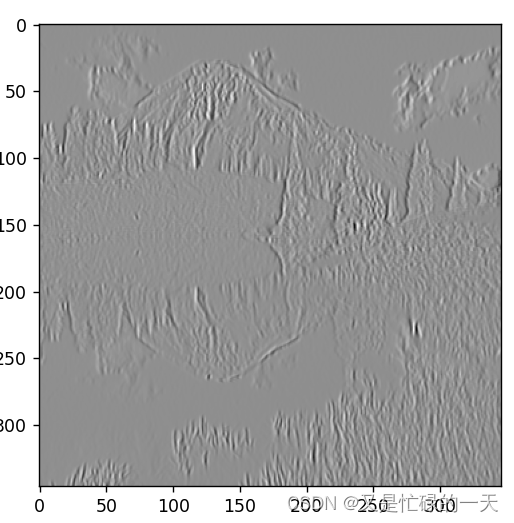
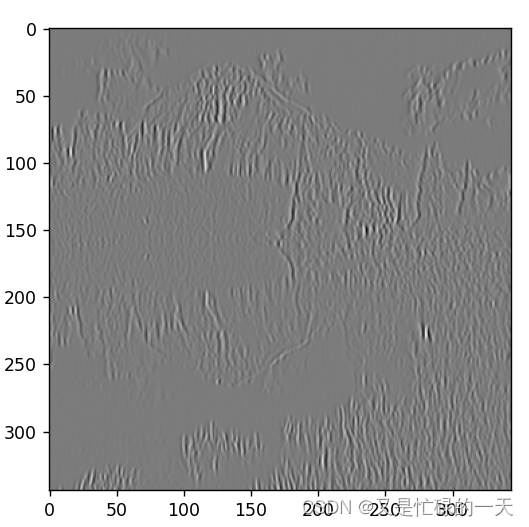
三、感悟
CNN和FNN比较类似,不过他相对于FNN加入了一些层。这些层由卷积层和池化组成。所以,在CNN中神经网络的层次和结构都是不固定的可以调整的。例如你可以只用一次卷积核一次池化,也可以用多次卷积多次池化,也可根据训练数据集的不同,去修改全连接层或者参数,例如学率,轮次等。















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









