







 文章介绍了YOLOV7模型中RepConv-BN模块的创新,强调了将1×1卷积核升级到3×3以利用英伟达硬件的优势,同时讨论了正样本分配策略和EMA训练技巧。SPPCSPC块的整合也是关键改进。文章还涉及了输出层的设计和候选框筛选流程。
文章介绍了YOLOV7模型中RepConv-BN模块的创新,强调了将1×1卷积核升级到3×3以利用英伟达硬件的优势,同时讨论了正样本分配策略和EMA训练技巧。SPPCSPC块的整合也是关键改进。文章还涉及了输出层的设计和候选框筛选流程。
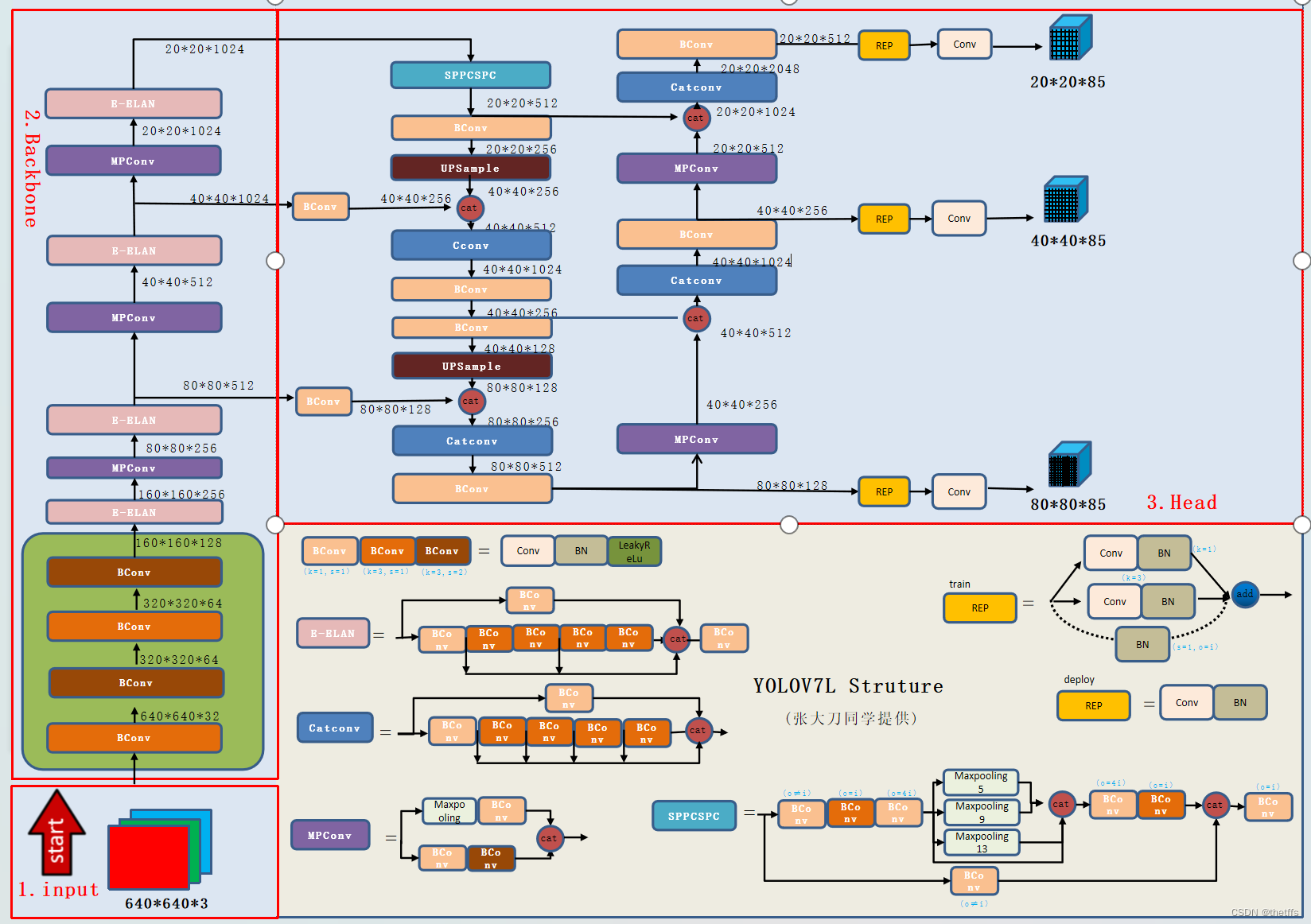
YOLOV7的改进
提升推理速度
RepConv-BN模块 (创新点1)
Conv层和BN层融合
将1×1卷积核提升到3×3
通常我们的1*1卷积核可以用来升维和降维。当我们认为网络中特征训练不好的时候通常增加网络的分支进行升维和降维。
具体操作:
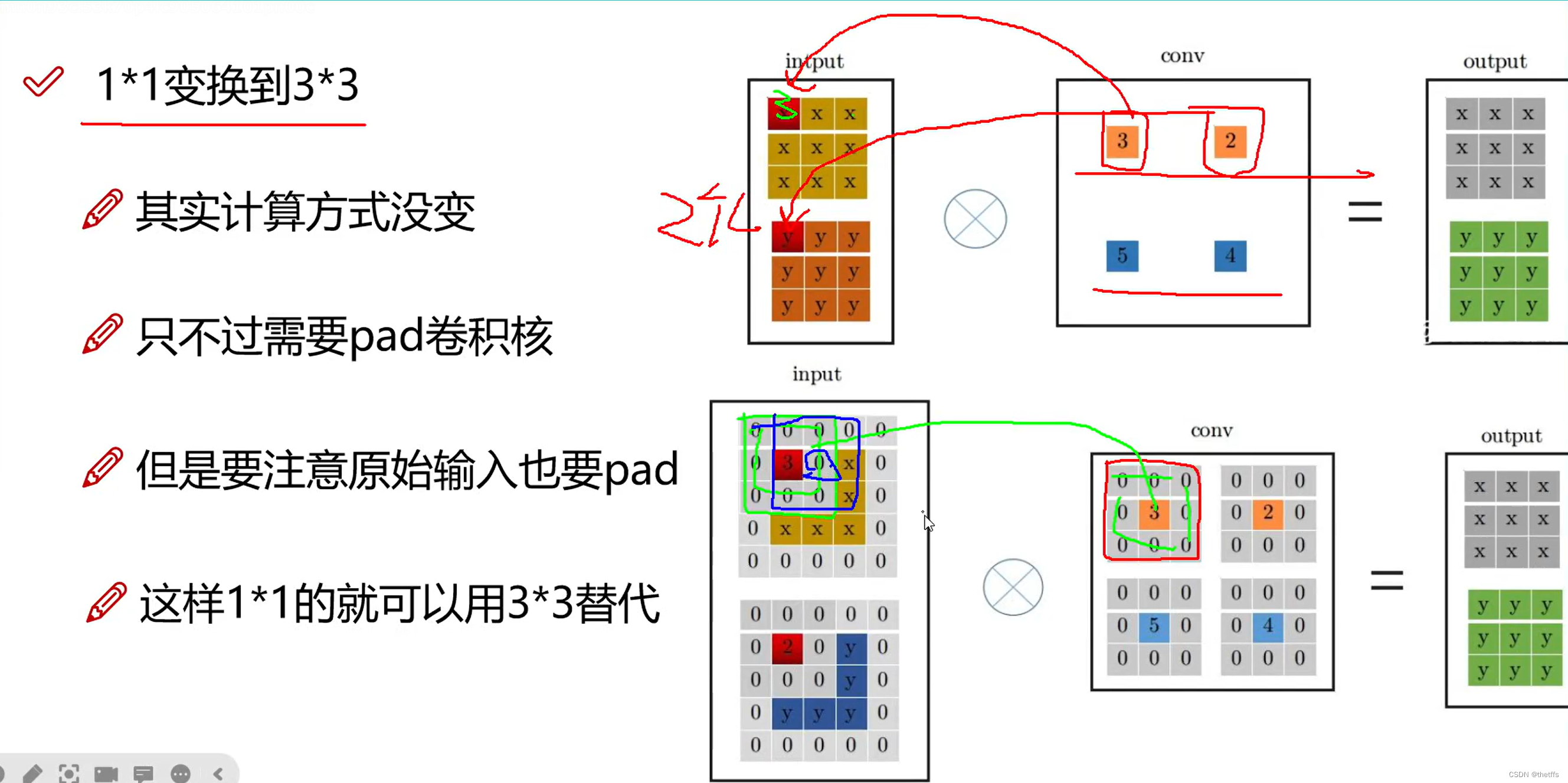
为什么要将11卷积核提升到33。因为英伟达的硬件对3*3的卷积计算支持的比较好,计算的更快。
英伟达的硬件对33的卷积计算支持的比较好,计算的更快的原因有以下几点:33的卷积核可以利用英伟达的 Tensor Core1,这是一种专门用于加速矩阵乘法和累加的硬件单元,可以大幅提高卷积运算的效率和吞吐量2。
33的卷积核可以使用英伟达的 cuDNN3 库,这是一种针对深度神经网络的高性能计算库,它提供了一些优化的算法和实现,例如 Winograd4 算法,可以减少卷积运算的乘法次数和内存访问5。
33的卷积核可以适应英伟达的 GPU架构,这是一种基于多个 流处理器 并行执行的硬件设计,它可以充分利用GPU的计算资源和带宽,避免出现空闲或者等待的情况。
综上所述,英伟达的硬件对33的卷积计算支持的比较好,计算的更快,这是由于它的硬件特性和软件优化相互配合,使得33的卷积核能够发挥出最大的性能。希望这能回答你的问题。
那为什么11的卷积核计算不如33的卷积核计算的快呢?
11的卷积核只能在通道维度上进行滤波操作,而不会改变特征图的高度和宽度,因此它不能有效地利用空间局部性,导致内存访问的开销较大12。
11的卷积核的参数量和计算量相对较小,因此它不能充分发挥英伟达的Tensor Core3的优势,这是一种专门用于加速矩阵乘法和累加的硬件单元,可以大幅提高卷积运算的效率和吞吐量4。
1*1的卷积核的计算粒度较细,因此它不能有效地利用英伟达的GPU架构5,这是一种基于多个流处理器并行执行的硬件设计,它可以充分利用GPU的计算资源和带宽,避免出现空闲或者等待的情况。
综上所述,11的卷积核计算不如33的卷积核计算计算的快,这是由于它的计算特性和英伟达的硬件特性不匹配,导致性能下降。
同时,将11的卷积核提升到33后,可以将网络的分支和主线部分(本身3*3)合并计算。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 240
240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









