







本文约4200字,建议阅读10+分钟
本文详细介绍了深度学习中几种关键的归一化技术。归一化是深度学习中的一个关键概念,可以确保更快的收敛、更稳定的训练和更好的整体性能。PyTorch中包含了几个归一化层,我们来详细看看每个归一化层的作用和使用方式。
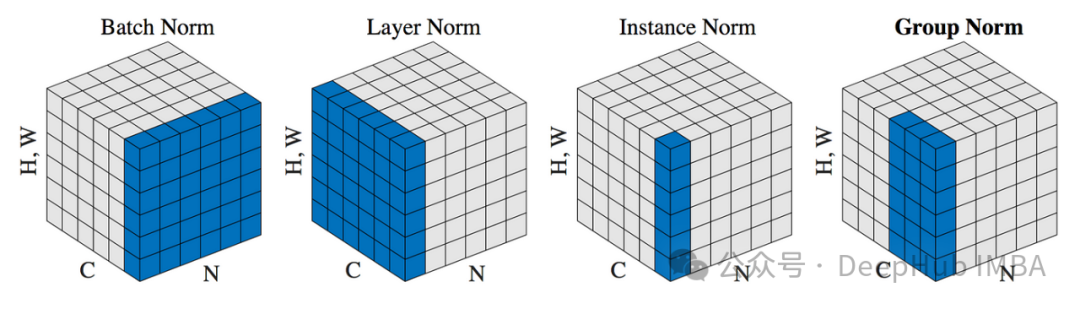
BN
批量归一化(Batch Normalization,简称BN)是一种广泛使用的技术,用于加速深度神经网络的训练,并提高其性能。它通过对每个小批量数据的输入进行归一化处理,使网络中间层的输入保持相对稳定,从而有助于解决训练过程中的梯度消失或梯度爆炸问题。
import torch.nn as nn
norm = nn.BatchNorm2d(num_features=64)批量归一化的主要作用:
改善梯度流:通过规范化层的输入,批量归一化有助于更平稳地传递梯度,这在训练深层网络时尤其重要。
允许使用更高的学习率:由于归一化的作用,参数空间更加平滑,因此可以使用更高的学习率,而不会导致训练过程不稳定。
减少模型对初始化的敏感性:归一化减少了模型初期权重设置的影响,从而使训练过程更加稳定。
具有轻微的正则化效果:由于每个小批量的均值和方差的估计引入了噪声,这种效果在某种程度上可以看作是模型的轻微正则化,有助于防止过拟合。
批量归一化的工作流程:
在训练过程中,批量归一化通过以下步骤实现:
计算批量均值与方差:对于给定的小批量数据,计算其特征的均值与方差。
归一化:使用计算出的均值和方差对小批量数据中的每个特征进行归一化处理,确保输出的均值接近0,方差接近1。
缩放与偏移:归一化后的数据会通过可学习的参数进行缩放和偏移,这两个参数是在训练过程中学习得到的,允许模型恢复可能被归一化操作去除的有用特征。
在模型推理或测试时,均值和方差不再针对每个小批量实时计算,而是使用整个训练集的移动平均值。
批量归一化已成为构建现代深度学习模型的基本组件,特别是在处理卷积网络和深层全连接网络时。
LN
层归一化(Layer Normalization,简称LN)是一种对神经网络中各层的输入进行标准化处理的技术,它与批量归一化(Batch Normalization)有相似的目的,都旨在帮助神经网络更快、更稳定地学习。不同于批量归一化主要针对一个批次中多个数据样本的相同特征进行归一化,层归一化则是在单个样本内部,对所有或部分特征进行归一化。
import torch.nn as nn
norm = nn.LayerNorm(256)层归一化的主要特点:
独立于批量大小:层归一化的操作与批量大小无关,这使得它在批量大小变化较大或为1时(如在线学习、强化学习中常见)特别有用。
适用于循环结构:在循环神经网络(RNN)中,由于时间步之间的依赖性,批量归一化难以有效应用。层归一化因其独立于批次维度,可以更好地应用于RNN及其变种中。
简化模型训练:层归一化由于不依赖于批次的统计信息,使得其在训练和推理时的行为更加一致,从而简化了模型的部署和维护。
层归一化的工作原理:
层归一化通常在神经网络的隐藏层中实施,其步骤如下:
计算特征的统计量:对于每个训练样本,计算其在单一层内所有或部分神经元的均值和方差。
归一化处理:使用上述计算得到的均值和方差,对每个样本的每个特征进行归一化,使其均值为0,方差为1。
重参数化:通过引入可学习的缩放参数和偏移参数,对归一化后的输出进行重新缩放和偏移,以便网络可以利用这些参数恢复那些可能对学习任务有用的被归一化掉的信息。
层归一化在自然语言处理中的Transformer模型(如BERT、GPT等)中非常有效。通过在每个隐藏层应用层归一化,这些模型能够更有效地训练深层网络结构。
IN
实例归一化(Instance Normalization,简称IN)是一种特定于图像处理领域的归一化技术,尤其在风格迁移和生成对抗网络(GANs)中得到广泛应用。实例归一化与批量归一化和层归一化有相似的目标,即通过规范化数据来加速神经网络的训练并提高其性能,但它在处理方式上有所不同。
import torch.nn as nn
norm = nn.InstanceNorm2d(num_features=64)实例归一化的特点:
针对单个数据实例:实例归一化独立于其他样本,对每个样本的每个通道分别进行归一化,这使得它适用于批大小为1的情况。
广泛应用于视觉任务:实例归一化在视觉任务中特别有效,尤其是在风格迁移中,可以帮助网络更好地学习和迁移风格特征,而不受图像内容的影响。
实例归一化的工作流程:
实例归一化主要在卷积神经网络中应用,具体步骤如下:
计算通道统计量:对于每个数据实例中的每个通道,计算该通道内所有元素的均值和方差。
归一化处理:使用上述统计量对每个通道的所有像素进行归一化,使输出的均值为0,方差为1。
重参数化:与其他归一化技术类似,实例归一化也使用可学习的缩放和偏移参数来调整归一化后的输出,从而允许模型恢复可能有助于任务的信息。
在图像风格迁移的应用中,实例归一化帮助网络专注于学习图像的风格特征,而不是内容特征。这种特性使得实例归一化在艺术风格迁移的任务中比批量归一化表现更优,因为它允许网络对每个图像独立地调整其风格表示,从而更有效地模拟不同的艺术风格。
GN
群归一化(Group Normalization,简称GN)介于实例归一化和层归一化之间。群归一化是由何恺明等人于2018年提出的,主要针对小批量训练数据的情况,以解决批量归一化在小批量数据上可能带来的不稳定性问题。
import torch.nn as nn
norm = nn.GroupNorm(num_groups=4, num_channels=64)群归一化的特点:
独立于批量大小:与批量归一化不同,群归一化的效果不依赖于批量大小,这使其在批量较小甚至为单个样本的情况下仍然有效。
适用于各种网络结构:群归一化可以被应用于卷积神经网络(CNN)和循环神经网络(RNN)等多种结构,提高模型的泛化能力和稳定性。
群归一化的工作原理:
群归一化将每个样本的特征分成若干个组,每组内部进行归一化处理。这里的“组”指的是将一个样本的通道分成若干个子集,每个子集内部独立计算均值和方差用于归一化。
具体步骤包括:
分组:选择一个合适的组数G(通常作为超参数)。每个样本的通道被平均分配到这些组中。
计算均值和方差:对于每个组内的通道,计算其所有激活值的均值和方差。
归一化处理:使用计算得到的均值和方差对每个组的每个通道的激活值进行归一化。
重参数化:归一化后的输出会通过可学习的缩放和偏移参数进行调整,以允许模型恢复可能对任务有用的信息。
群归一化在许多深度学习任务中表现出色,特别是在那些不适合使用批量归一化(例如,非常小的批量大小)的应用中。它在提供模型稳定性的同时,也保持了较高的训练和推理效率。此外,群归一化因其不依赖于批次大小的特性,特别适用于需要高度实时性的应用,如视频处理和移动设备上的实时应用。
SyncBN
同步批量归一化(Synchronized Batch Normalization,简称SyncBN)是批量归一化的一个变种,它主要应用于多GPU训练环境中。在标准的批量归一化中,每个GPU对其接收到的数据批进行独立的均值和方差计算,这在GPU数量较多时可能会因为每个GPU上的批量较小而影响归一化的效果。同步批量归一化解决了这个问题,通过在多个GPU或设备间同步均值和方差的计算,使得整体批量增大,从而提高了归一化的稳定性和效果。
import torch.nn as nn
norm = nn.SyncBatchNorm(num_features=64)同步批量归一化的工作原理:
跨设备同步:在进行前向传播和后向传播时,各个GPU计算其自己批次的均值和方差,然后这些统计量会在所有GPU之间进行聚合,计算全局均值和全局方差。
全局归一化:使用聚合后的全局均值和全局方差对各个GPU上的数据进行归一化处理。
学习参数:归一化后的数据通过可学习的缩放和偏移参数进行调整,这些参数在网络训练过程中进行优化。
同步批量归一化的优势:
增强模型的稳定性:通过使用更大的全局批量统计数据,可以减少批量归一化中因批量大小不足导致的估计不准确问题。
提高训练效率:在多GPU训练中,SyncBN有助于提高网络的收敛速度和最终性能,因为每个设备的归一化过程都利用了所有设备的信息。
适用于分布式训练:特别适合于大规模分布式训练,因为它可以平衡和统一在不同设备上的训练动态。
同步批量归一化特别适用于资源丰富的训练环境,如使用多个GPU或多台机器进行训练的场景。这在处理大型网络和复杂模型(如大型图像识别、视频处理或大规模语言模型)时尤其重要,这些模型通常需要大量的计算资源和数据批量来实现最优性能。
同步批量归一化通过在多GPU环境中同步均值和方差的计算,有效地克服了传统批量归一化在分布式训练中面临的挑战,提高了模型训练的效果和效率。
LRN
局部响应归一化(Local Response Normalization,简称LRN)是一种在卷积神经网络(CNN)中应用的归一化技术,特别是在较早的深度学习模型中,如AlexNet中,用于处理图像识别任务。LRN的灵感来源于生物学中的侧抑制现象,这种现象通过抑制活跃的神经元周围的神经元,从而增强模式的局部对比度,提高神经网络对图像中信息的响应能力。
import torch.nn as nn
norm = LocalResponseNorm(size=2)局部响应归一化通过对一个给定的激活在局部邻域内进行归一化来工作,这种邻域通常是在同一个空间位置上的不同通道之间。具体步骤如下:
计算活性:首先计算特定位置上每个通道的激活值的平方。
邻域求和:对每个激活值的平方在一个指定的邻域范围内求和,通常这个邻域包括当前通道的前后几个通道。
归一化:每个激活值将被其邻域求和的结果按照一个标准化公式调整,这个公式包含可调整的参数,用于控制归一化的程度。
保持比例:通过这种方式,一个神经元的输出会根据其相对于邻域内其他神经元的活跃程度进行调整,从而实现局部抑制效果。
LRN的数学公式通常表示为:
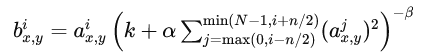
其中:
ax,yi 是在位置 (x, y) 第 i 个通道的原始激活值。
bx,yi, 是归一化后的激活值。
n 是邻域的大小。
α,β, k 是超参数,用于调整归一化的效果。
N是总的通道数。
LRN曾在一些早期的CNN模型中广泛使用,例如在AlexNet中用于提高分类精度。但是随着深度学习技术的发展,特别是批量归一化等更先进的归一化技术的出现,LRN的使用已经较少。这是因为批量归一化不仅能提供更加稳定和快速的训练过程,还能在很大程度上改善模型的最终性能。因此在现代深度学习架构中,LRN的使用已经逐渐被其他归一化方法所取代。
总结
本文详细介绍了深度学习中几种关键的归一化技术:批量归一化(BN)、层归一化(LN)、实例归一化(IN)、群归一化(GN)以及同步批量归一化(SyncBN)和局部响应归一化(LRN)。这些技术通过对神经网络中的数据进行归一化处理,帮助改善网络的学习速度和性能。每种技术都针对不同的应用场景和需求优化,如批量归一化适合大批量数据处理,实例归一化主要用于图像风格迁移,而群归一化则适用于小批量数据。同步批量归一化优化了多GPU训练的归一化过程,而局部响应归一化虽然在早期模型中使用较多,但在现代架构中已较少使用。
编辑:黄继彦
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU















 3969
3969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









